Refine search
Actions for selected content:
53182 results in Statistics and Probability
Household transmission of human metapneumovirus and seasonal coronavirus
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 21 May 2024, e90
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
HETEROSKEDASTICITY ROBUST SPECIFICATION TESTING IN SPATIAL AUTOREGRESSION
-
- Journal:
- Econometric Theory / Volume 41 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 21 May 2024, pp. 995-1043
-
- Article
-
- You have access
- Open access
- Export citation
Bonus-Malus Scale premiums for Tweedie’s compound Poisson models
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 2 / July 2024
- Published online by Cambridge University Press:
- 21 May 2024, pp. 509-533
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AffineMortality: An R package for estimation, analysis, and projection of affine mortality models
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 21 May 2024, pp. 23-48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the benefits of pension plan consolidation: Understanding the impact of full plan mergers
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 21 May 2024, pp. 49-81
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
REAL ANALYTIC DISCRETE CHOICE MODELS OF DEMAND: THEORY AND IMPLICATIONS
-
- Journal:
- Econometric Theory / Volume 41 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 20 May 2024, pp. 1080-1128
-
- Article
-
- You have access
- Open access
- Export citation
Depths in random recursive metric spaces
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 20 May 2024, pp. 1448-1462
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
IFoA Presidential Address 2023
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 20 May 2024, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Harmonic Functions and Random Walks on Groups
-
- Published online:
- 16 May 2024
- Print publication:
- 23 May 2024
Series expansions for random disc-polygons in smooth plane convex bodies
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 16 May 2024, pp. 1407-1423
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We establish power-series expansions for the asymptotic expectations of the vertex number and missed area of random disc-polygons in planar convex bodies with
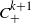 $C^{k+1}_+$-smooth boundaries. These results extend asymptotic formulas proved in Fodor et al. (2014).
$C^{k+1}_+$-smooth boundaries. These results extend asymptotic formulas proved in Fodor et al. (2014).
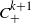
Investigating the cause of a 2021 winter wave of COVID-19 in a border region in eastern Germany: a mixed-methods study, August to November 2021
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 16 May 2024, e87
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Farm animal exposure setting impacts hemolytic uremic syndrome risk among Shiga toxin-producing Escherichia coli cases: Minnesota, 2010–2019
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 16 May 2024, e96
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How to co-create content moderation policies: the case of the AutSPACEs project
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 15 May 2024, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Calculating premium principles from the mode of a unimodal weighted distribution
- Part of
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 15 May 2024, pp. 791-803
- Print publication:
- September 2024
-
- Article
- Export citation
Spatial–temporal distribution characteristics of pulmonary tuberculosis in eastern China from 2011 to 2021
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 15 May 2024, e84
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk analysis of a multivariate aggregate loss model with dependence
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 14 May 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rao-Blackwellized particle smoothing for simultaneous localization and mapping
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 13 May 2024, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TESTING LIMITED OVERLAP
-
- Journal:
- Econometric Theory / Volume 41 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 13 May 2024, pp. 1129-1162
-
- Article
-
- You have access
- Open access
- Export citation
High all-cause mortality and increasing proportion of older adults with tuberculosis in Texas, 2008–2020
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 13 May 2024, e82
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Salmonella Hadar linked to two distinct transmission vehicles highlights challenges to enteric disease outbreak investigations
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 13 May 2024, e86
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
