Refine search
Actions for selected content:
53183 results in Statistics and Probability
Unleashing collective intelligence for public decision-making: the Data for Policy community
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 15 April 2024, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Severe weather events and cryptosporidiosis in Aotearoa New Zealand: A case series of space–time clusters
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 15 April 2024, e64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ASB volume 54 issue 2 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 2 / May 2024
- Published online by Cambridge University Press:
- 15 April 2024, pp. f1-f2
- Print publication:
- May 2024
-
- Article
-
- You have access
- Export citation
ASB volume 54 issue 2 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 2 / May 2024
- Published online by Cambridge University Press:
- 15 April 2024, pp. b1-b3
- Print publication:
- May 2024
-
- Article
-
- You have access
- Export citation
IDENTIFICATION ROBUST INFERENCE FOR MOMENTS-BASED ANALYSIS OF LINEAR DYNAMIC PANEL DATA MODELS – ADDENDUM
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 15 April 2024, p. 1
-
- Article
-
- You have access
- Open access
- Export citation
Multidimensional credibility: A new approach based on joint distribution function
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 12 April 2024, pp. 652-678
- Print publication:
- September 2024
-
- Article
- Export citation
When can networks be inferred from observed groups?
-
- Journal:
- Network Science / Volume 12 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 12 April 2024, pp. 189-200
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The limiting spectral distribution of large random permutation matrices
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 12 April 2024, pp. 1301-1318
- Print publication:
- December 2024
-
- Article
- Export citation
-
We explore the limiting spectral distribution of large-dimensional random permutation matrices, assuming the underlying population distribution possesses a general dependence structure. Let
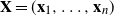 $\textbf X = (\textbf x_1,\ldots,\textbf x_n)$
$\textbf X = (\textbf x_1,\ldots,\textbf x_n)$ 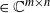 $\in \mathbb{C} ^{m \times n}$ be an
$\in \mathbb{C} ^{m \times n}$ be an 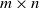 $m \times n$ data matrix after self-normalization (n samples and m features), where
$m \times n$ data matrix after self-normalization (n samples and m features), where 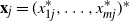 $\textbf x_j = (x_{1j}^{*},\ldots, x_{mj}^{*} )^{*}$. Specifically, we generate a permutation matrix
$\textbf x_j = (x_{1j}^{*},\ldots, x_{mj}^{*} )^{*}$. Specifically, we generate a permutation matrix 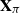 $\textbf X_\pi$ by permuting the entries of
$\textbf X_\pi$ by permuting the entries of 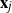 $\textbf x_j$
$\textbf x_j$ 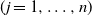 $(j=1,\ldots,n)$ and demonstrate that the empirical spectral distribution of
$(j=1,\ldots,n)$ and demonstrate that the empirical spectral distribution of 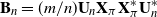 $\textbf {B}_n = ({m}/{n})\textbf{U} _{n} \textbf{X} _\pi \textbf{X} _\pi^{*} \textbf{U} _{n}^{*}$ weakly converges to the generalized Marčenko–Pastur distribution with probability 1, where
$\textbf {B}_n = ({m}/{n})\textbf{U} _{n} \textbf{X} _\pi \textbf{X} _\pi^{*} \textbf{U} _{n}^{*}$ weakly converges to the generalized Marčenko–Pastur distribution with probability 1, where 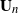 $\textbf{U} _n$ is a sequence of
$\textbf{U} _n$ is a sequence of 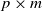 $p \times m$ non-random complex matrices. The conditions we require are
$p \times m$ non-random complex matrices. The conditions we require are 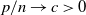 $p/n \to c >0$ and
$p/n \to c >0$ and 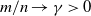 $m/n \to \gamma > 0$.
$m/n \to \gamma > 0$.
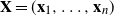
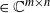
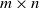
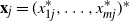
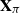
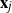
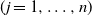
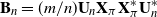
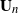
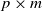
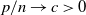
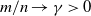
Algorithmic aspects of temporal betweenness
-
- Journal:
- Network Science / Volume 12 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 12 April 2024, pp. 160-188
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Genomic characterization of extended-spectrum β-lactamase-producing Enterobacterales isolated from abdominal surgical patients
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 12 April 2024, e70
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exposure dynamics of Ross River virus in horses – Horses as potential sentinels (a One Health approach)
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 12 April 2024, e67
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Serological follow-up after syphilis diagnosis in Israel
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 12 April 2024, e63
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The distribution of the maximum protection number in simply generated trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 12 April 2024, pp. 518-553
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The protection number of a vertex
 $v$ in a tree is the length of the shortest path from
$v$ in a tree is the length of the shortest path from  $v$ to any leaf contained in the maximal subtree where
$v$ to any leaf contained in the maximal subtree where  $v$ is the root. In this paper, we determine the distribution of the maximum protection number of a vertex in simply generated trees, thereby refining a recent result of Devroye, Goh, and Zhao. Two different cases can be observed: if the given family of trees allows vertices of outdegree
$v$ is the root. In this paper, we determine the distribution of the maximum protection number of a vertex in simply generated trees, thereby refining a recent result of Devroye, Goh, and Zhao. Two different cases can be observed: if the given family of trees allows vertices of outdegree 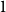 $1$, then the maximum protection number is on average logarithmic in the tree size, with a discrete double-exponential limiting distribution. If no such vertices are allowed, the maximum protection number is doubly logarithmic in the tree size and concentrated on at most two values. These results are obtained by studying the singular behaviour of the generating functions of trees with bounded protection number. While a general distributional result by Prodinger and Wagner can be used in the first case, we prove a variant of that result in the second case.
$1$, then the maximum protection number is on average logarithmic in the tree size, with a discrete double-exponential limiting distribution. If no such vertices are allowed, the maximum protection number is doubly logarithmic in the tree size and concentrated on at most two values. These results are obtained by studying the singular behaviour of the generating functions of trees with bounded protection number. While a general distributional result by Prodinger and Wagner can be used in the first case, we prove a variant of that result in the second case.



Machine Learning with High-Cardinality Categorical Features in Actuarial Applications
- Part of
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 2 / May 2024
- Published online by Cambridge University Press:
- 11 April 2024, pp. 213-238
- Print publication:
- May 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From bias to black boxes: understanding and managing the risks of AI – an actuarial perspective
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 11 April 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A stand-alone proximity-based gaming wearable for remote physical activity monitoring
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 11 April 2024, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using graph neural networks for wall modeling in compressible anisothermal flows
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 10 April 2024, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Network analysis in peace and state building: revealing power elites
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 April 2024, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generating preferential attachment graphs via a Pólya urn with expanding colors
-
- Journal:
- Network Science / Volume 12 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 08 April 2024, pp. 139-159
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Buffon’s problem determines Gaussian curvature in three geometries
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 08 April 2024, pp. 1127-1138
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
