Refine search
Actions for selected content:
53191 results in Statistics and Probability
Comparative epidemiology of outbreaks caused by SARS-CoV-2 Delta and Omicron variants in China
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 19 March 2024, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discounted densities of overshoot and undershoot for Lévy processes with applications in finance
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 4 / October 2024
- Published online by Cambridge University Press:
- 19 March 2024, pp. 644-667
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Annual risk of hepatitis E virus infection and seroreversion: Insights from a serological cohort in Sitakunda, Bangladesh
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 March 2024, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interplay of missed opportunity for vaccination and poor response to the vaccine led to measles outbreak in a slum area of Eastern Mumbai, India
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 March 2024, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rapid assessment of data systems for COVID-19 vaccination in the WHO African Region
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 March 2024, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using the Five Safes to structure economic evaluations of data governance
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 18 March 2024, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A representation-learning approach for insurance pricing with images
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 2 / May 2024
- Published online by Cambridge University Press:
- 15 March 2024, pp. 280-309
- Print publication:
- May 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The molecular epidemiology of hepatitis E virus genotype 3 in Canada
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 15 March 2024, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Barriers to vaccine acceptance in the adult population of mainland Finland, 2021
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 15 March 2024, e54
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Appendix A - Pre-test questions
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp 319-324
-
- Chapter
- Export citation
Appendix B - Final exam questions
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp 325-356
-
- Chapter
- Export citation
Machine learning for detecting fake accounts and genetic algorithm-based feature selection
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 14 March 2024, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 1 - Active learning
- from Part 1: - Organizing a plan of study
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp 3-12
-
- Chapter
-
- You have access
- Export citation
Chapter 3 - Week by week: the first semester
- from Part 2: - Stories, activities, problems, and demonstrations
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp 31-162
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp i-iv
-
- Chapter
- Export citation
Contents
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp v-vi
-
- Chapter
- Export citation
Combining models to generate a consensus effective reproduction number R for the COVID-19 epidemic status in England
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 14 March 2024, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The effective reproduction number
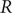 $ R $ was widely accepted as a key indicator during the early stages of the COVID-19 pandemic. In the UK, the
$ R $ was widely accepted as a key indicator during the early stages of the COVID-19 pandemic. In the UK, the 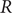 $ R $ value published on the UK Government Dashboard has been generated as a combined value from an ensemble of epidemiological models via a collaborative initiative between academia and government. In this paper, we outline this collaborative modelling approach and illustrate how, by using an established combination method, a combined
$ R $ value published on the UK Government Dashboard has been generated as a combined value from an ensemble of epidemiological models via a collaborative initiative between academia and government. In this paper, we outline this collaborative modelling approach and illustrate how, by using an established combination method, a combined 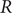 $ R $ estimate can be generated from an ensemble of epidemiological models. We analyse the
$ R $ estimate can be generated from an ensemble of epidemiological models. We analyse the 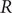 $ R $ values calculated for the period between April 2021 and December 2021, to show that this
$ R $ values calculated for the period between April 2021 and December 2021, to show that this 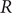 $ R $ is robust to different model weighting methods and ensemble sizes and that using heterogeneous data sources for validation increases its robustness and reduces the biases and limitations associated with a single source of data. We discuss how
$ R $ is robust to different model weighting methods and ensemble sizes and that using heterogeneous data sources for validation increases its robustness and reduces the biases and limitations associated with a single source of data. We discuss how 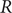 $ R $ can be generated from different data sources and show that it is a good summary indicator of the current dynamics in an epidemic.
$ R $ can be generated from different data sources and show that it is a good summary indicator of the current dynamics in an epidemic.
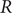
Part 2: - Stories, activities, problems, and demonstrations
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp 29-30
-
- Chapter
- Export citation
Appendix C - Outlines of classroom activities
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp 357-361
-
- Chapter
- Export citation
How to use this book
-
- Book:
- Active Statistics
- Published online:
- 07 March 2024
- Print publication:
- 14 March 2024, pp vii-viii
-
- Chapter
- Export citation
