Refine search
Actions for selected content:
53172 results in Statistics and Probability
Chapter 15 - Bias in Genetic Studies
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 142-150
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 1-16
-
- Chapter
-
- You have access
- Export citation
Arbitrable stochastic games: three variations of the heads-or-tails game for bitcoin
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 06 May 2026, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Serial cycle threshold to assess the infectious potential of SARS-CoV-2: A systematic review
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 May 2026, e89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Global distribution and evolution of human metapneumovirus A2b2 clade: Insights from genomic surveillance
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 May 2026, e72
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Regulating Indonesia’s digital economy: Balancing growth, inclusion, and governance
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 05 May 2026, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association between chronic hepatitis B virus infection and stroke risk: a propensity score-matched analysis
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 05 May 2026, e66
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotic behavior of frequency polygon estimation of density function for dependent samples
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 05 May 2026, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper pays attention to the frequency polygon, which is constructed by connecting with straight lines the mid-bin values of a histogram. As a density estimator based on the histogram technique, the frequency polygon has the advantage of computational simplicity and has been widely used in many fields. The purpose of this article is to investigate the weak consistency, the uniformly weak consistency, and the rate of the uniformly weak consistency for frequency polygon estimation of the density function under
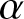 $\alpha$-mixing samples, which improve and extend the corresponding ones in the literature. In addition, the simulation study and real data analysis are also presented to verify the validity of the theoretical results based on finite samples.
$\alpha$-mixing samples, which improve and extend the corresponding ones in the literature. In addition, the simulation study and real data analysis are also presented to verify the validity of the theoretical results based on finite samples.
No-arbitrage valuation and Solvency Capital Requirement for equity-linked contracts under demographic uncertainty
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 05 May 2026, pp. 1-34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Acute COVID-19 mortality in England in the omicron era: a national-level matched cohort study
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 05 May 2026, e70
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Post-pandemic immunity debt for paediatric infectious diseases in Japan between 2014 and 2024
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 05 May 2026, e67
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Local limit theorems for energy fluxes of infinitely divisible random fields
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 04 May 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interregional outbreak of Salmonella Typhimurium linked to fresh cheese: A case–case study guided by whole-genome sequencing (WGS), Portugal, March–June 2024
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 04 May 2026, e68
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiological evaluation of cholera outbreak dynamics in conflict-affected Central and Northwestern Tigray, northern Ethiopia: evidence from GEE analysis
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 30 April 2026, e64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Influenza vaccination coverage and determinants of vaccination among older adults in Turkey
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 30 April 2026, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A comparison of frequentist and Bayesian methods for meta-analysis of diagnostic test accuracy studies
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 30 April 2026, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiologic and economic impact of introducing a National Immunization Program for herpes zoster vaccination on the prevention of herpes zoster and postherpetic neuralgia in South Korea, an ageing society
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 30 April 2026, e62
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mortality Forecasting in Geographical Space and Time – ERRATUM
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 30 April 2026, p. 1
-
- Article
-
- You have access
- HTML
- Export citation
Excess of age transfer policy for life annuities under longevity risk
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 29 April 2026, pp. 1-24
-
- Article
- Export citation
Reading gender into citizen data practices for sustainable development
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 29 April 2026, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
