Refine search
Actions for selected content:
53172 results in Statistics and Probability
Leveraging scale separation and stochastic closure for data-driven prediction of chaotic dynamics
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 20 April 2026, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Simulating turbulent fluid flows is a computationally prohibitive task, as it requires the resolution of fine-scale structures and the capture of complex nonlinear interactions across multiple scales. Consequently, extensive research has focused on analysing turbulent flows from a data-driven perspective. However, due to the complex and chaotic nature of these systems, traditional models often become unstable. To overcome these limitations, we propose a purely stochastic approach that separately addresses the evolution of large-scale coherent structures and the closure of high-fidelity statistical data. To this end, the dynamics of the filtered data are learnt using an autoregressive model. This combines a variational-autoencoder (VAE) and Transformer architecture. The VAE projection is probabilistic, ensuring consistency between the model’s stochasticity and the flow’s statistical properties. The mean realisation of stochastically sampled trajectories from our model shows relative
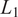 $ {L}_1 $ and
$ {L}_1 $ and 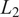 $ {L}_2 $ distances of 6% and 10%, respectively. Moreover, our framework enables the construction of meaningful confidence intervals, achieving a prediction interval coverage probability of 80% with minimal interval width. To recover high-fidelity velocity fields from the filtered space, Gaussian Process (GP) regression is employed. This strategy has been tested in the context of a Kolmogorov flow exhibiting chaotic behavior. We compare the performance of our model with state-of-the-art probabilistic baselines, including a VAE and a diffusion model. We demonstrate that our Gaussian process-based closure outperforms these baselines in capturing first and second moment statistics in this particular test bed, providing robust and adaptive confidence intervals.
$ {L}_2 $ distances of 6% and 10%, respectively. Moreover, our framework enables the construction of meaningful confidence intervals, achieving a prediction interval coverage probability of 80% with minimal interval width. To recover high-fidelity velocity fields from the filtered space, Gaussian Process (GP) regression is employed. This strategy has been tested in the context of a Kolmogorov flow exhibiting chaotic behavior. We compare the performance of our model with state-of-the-art probabilistic baselines, including a VAE and a diffusion model. We demonstrate that our Gaussian process-based closure outperforms these baselines in capturing first and second moment statistics in this particular test bed, providing robust and adaptive confidence intervals.
Congenital syphilis in Portugal, 2015–2024: Temporal-spatial characterization and gaps in prevention of vertical transmission
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 17 April 2026, e91
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the slow phase for fixed-energy activated random walks
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 17 April 2026, pp. 1-16
-
- Article
- Export citation
Large outbreak of Salmonella Muenchen linked to dried coconut pieces, September 2020 to July 2021, Germany
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 17 April 2026, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comments on “Adherence to oral zinc supplementation in the management of acute diarrhoeal disease among under-5 children: a systematic review and meta-analysis”
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 17 April 2026, e54
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI-driven dynamic electronic road pricing to reduce air pollution and traffic congestion
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 16 April 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
As a major metropolitan city, London faces persistent road congestion and severe air pollution. To address these issues, static electronic road pricing (ERP) models have been implemented. While effective, these are inherently limited in flexibility. This paper explores dynamic ERP models to improve upon static pricing by minimizing air pollution and traffic congestion within the Congestion Charge Zone. The problem is formulated as a multi-stakeholder multi-objective optimization problem, incorporating the perspectives of three stakeholders—the government, vehicle owners, and environmental organizations—and three objectives: air pollution, traffic congestion, and price. The NSGA-II optimization algorithm was applied on a representative day and demonstrated substantial improvements. The concentration of PM
 $ {}_{2.5} $—the more harmful pollutant—was reduced by up to 23%, while NO2 levels fell by 2–3%. Traffic flow, used as a proxy for congestion, decreased by approximately 3–4% during peak hours. These improvements were achieved with only a modest increase in the mean price to £12.51 (from a baseline of £11.50), with a standard deviation of £1.59 and a variance of £2.43 across hourly prices. These results suggest that targeted dynamic pricing—when aligned with environmental and behavioural incentives—can deliver measurable gains in urban air quality and congestion without imposing a significant cost burden on drivers. A core novelty of this work lies in its practical, stakeholder-inclusive problem formulation. While the approach assumes infrastructure for automated price deduction and routing, this limitation can be addressed in future work through advances in vehicle–infrastructure communication systems.
$ {}_{2.5} $—the more harmful pollutant—was reduced by up to 23%, while NO2 levels fell by 2–3%. Traffic flow, used as a proxy for congestion, decreased by approximately 3–4% during peak hours. These improvements were achieved with only a modest increase in the mean price to £12.51 (from a baseline of £11.50), with a standard deviation of £1.59 and a variance of £2.43 across hourly prices. These results suggest that targeted dynamic pricing—when aligned with environmental and behavioural incentives—can deliver measurable gains in urban air quality and congestion without imposing a significant cost burden on drivers. A core novelty of this work lies in its practical, stakeholder-inclusive problem formulation. While the approach assumes infrastructure for automated price deduction and routing, this limitation can be addressed in future work through advances in vehicle–infrastructure communication systems.

THE ECONOMETRIC THEORY AWARDS 2026
-
- Journal:
- Econometric Theory / Volume 42 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 16 April 2026, p. 1
-
- Article
-
- You have access
- HTML
- Export citation
Brochette first-passage percolation
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 14 April 2026, pp. 1-21
-
- Article
- Export citation
-
We investigate a novel first-passage percolation model, referred to as the Brochette first-passage percolation model, where the passage times associated with edges lying on the same line are equal. First, we establish a point-to-point convergence theorem, identifying the time constant. In particular, we explore the case where the time constant vanishes and demonstrate the existence of a wide range of possible behaviours. Next, we prove a shape theorem, showing that the limiting shape is the
 $L^1$ diamond. Finally, we extend the analysis by proving a point-to-point convergence theorem in the setting where passage times are allowed to be infinite.
$L^1$ diamond. Finally, we extend the analysis by proving a point-to-point convergence theorem in the setting where passage times are allowed to be infinite.

State-space dynamic functional regression for multicurve fixed income spread analysis and stress testing
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 2 / July 2026
- Published online by Cambridge University Press:
- 14 April 2026, pp. 439-472
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Off-diagonal Ramsey numbers for linear hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 14 April 2026, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study off-diagonal Ramsey numbers
 $r(H, K_n^{(k)})$ of
$r(H, K_n^{(k)})$ of 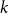 $k$-uniform hypergraphs, where
$k$-uniform hypergraphs, where 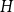 $H$ is a fixed linear
$H$ is a fixed linear  $k$-uniform hypergraph and
$k$-uniform hypergraph and  $K_n^{(k)}$ is complete on
$K_n^{(k)}$ is complete on  $n$ vertices. Recently, Conlon, Fox, Gunby, He, Mubayi, Suk, and Verstraëte disproved the folklore conjecture that
$n$ vertices. Recently, Conlon, Fox, Gunby, He, Mubayi, Suk, and Verstraëte disproved the folklore conjecture that  $r(H, K_n^{(3)})$ always grows polynomially in
$r(H, K_n^{(3)})$ always grows polynomially in  $n$. In this paper, we show that much larger growth rates are possible in higher uniformity. In uniformity
$n$. In this paper, we show that much larger growth rates are possible in higher uniformity. In uniformity 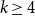 $k\ge 4$, we prove that for any constant
$k\ge 4$, we prove that for any constant 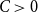 $C\gt 0$, there exists a linear
$C\gt 0$, there exists a linear  $k$-uniform hypergraph
$k$-uniform hypergraph  $H$ for which
$H$ for which \begin{equation*} r(H,K_n^{(k)}) \geq {\textrm {twr}}_{k-2}(2^{(\log n)^C}). \end{equation*}
\begin{equation*} r(H,K_n^{(k)}) \geq {\textrm {twr}}_{k-2}(2^{(\log n)^C}). \end{equation*}

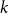
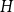





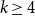
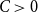



A CONSISTENT ICM-BASED
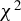 $\chi^2$ SPECIFICATION TEST
$\chi^2$ SPECIFICATION TEST
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 13 April 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In spite of the omnibus property of integrated conditional moment (ICM) specification tests, they are not commonly used in empirical practice owing to features such as the non-pivotality of the test and the high computational cost of available bootstrap schemes, especially in large samples. This article proposes specification and mean independence tests based on ICM metrics. The proposed test exhibits consistency, asymptotic
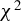 $\chi ^2$-distribution under the null hypothesis, and computational efficiency. Moreover, it demonstrates robustness to heteroskedasticity of unknown form and can be adapted to enhance power toward specific alternatives. A power comparison with classical bootstrap-based ICM tests using Bahadur slopes is also provided. Monte Carlo simulations are conducted to showcase the excellent size control and competitive power of the proposed test.
$\chi ^2$-distribution under the null hypothesis, and computational efficiency. Moreover, it demonstrates robustness to heteroskedasticity of unknown form and can be adapted to enhance power toward specific alternatives. A power comparison with classical bootstrap-based ICM tests using Bahadur slopes is also provided. Monte Carlo simulations are conducted to showcase the excellent size control and competitive power of the proposed test.
In search of common ground: Exploring value networks at the UNFCCC climate change talks
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 13 April 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data, algorithmic targeting, and artificial intelligence (AI) technologies in adaptive social cash systems: towards an AI governance framework
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 13 April 2026, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
County of San Diego, California, investigates Salmonella Typhimurium outbreak linked to unpasteurized milk – September 2023–January 2024
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 13 April 2026, e98
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A star is born: Explosive Crump–Mode–Jagers branching processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 13 April 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Local genomic epidemiology investigations of SARS-CoV-2 during the early pandemic response: A global systematic review
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 10 April 2026, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lévy processes under level-dependent Poisson switching
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 10 April 2026, pp. 1-34
-
- Article
- Export citation

An exploratory hybrid AI workflow for Brazilian federal budget allocation
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 08 April 2026, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotic normality for triangle counting in the sparse
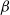 $\beta$-model
$\beta$-model
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the number of triangles
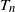 $T_n$ in the sparse
$T_n$ in the sparse 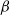 $\beta$-model on n vertices, a random graph model that captures degree heterogeneity in real-world networks. Using the norms of the heterogeneity parameter vector, we first determine the asymptotic mean and variance of
$\beta$-model on n vertices, a random graph model that captures degree heterogeneity in real-world networks. Using the norms of the heterogeneity parameter vector, we first determine the asymptotic mean and variance of 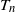 $T_n$. Next, by applying the Malliavin–Stein method, we derive a non-asymptotic upper bound on the Kolmogorov distance between the normalized
$T_n$. Next, by applying the Malliavin–Stein method, we derive a non-asymptotic upper bound on the Kolmogorov distance between the normalized 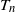 $T_n$ and the standard normal distribution. Under an additional assumption on degree heterogeneity, we further prove the asymptotic normality for
$T_n$ and the standard normal distribution. Under an additional assumption on degree heterogeneity, we further prove the asymptotic normality for 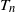 $T_n$ as
$T_n$ as 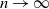 $n\to\infty$.
$n\to\infty$.
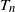
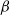
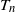
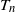
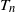
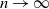
On the study of bivariate and conditional dynamic negative cumulative extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
