Refine search
Actions for selected content:
53172 results in Statistics and Probability
On first-order autoregressive random field moving average coefficients: Time-domain approach
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 29 April 2026, pp. 1-15
-
- Article
- Export citation
-
This work is devoted to the theoretical and numerical derivation of the moving average coefficients for a first-order autoregressive random field
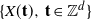 $\{X(\mathbf{t}),\, \mathbf{t}\in \mathbb{Z}^{d}\}$ where
$\{X(\mathbf{t}),\, \mathbf{t}\in \mathbb{Z}^{d}\}$ where 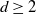 $d\geq 2$ and
$d\geq 2$ and 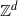 $\mathbb{Z}^d$ is the lattice of points with integer coordinates in the d-dimensional Euclidean space. We develop formulations for the autocorrelation function, the forecast recipe and the forecast error. A sufficient condition for causality is also provided, in addition to an algorithm and corresponding Wolfram Mathematica code for the numerical computation of the moving average coefficients.
$\mathbb{Z}^d$ is the lattice of points with integer coordinates in the d-dimensional Euclidean space. We develop formulations for the autocorrelation function, the forecast recipe and the forecast error. A sufficient condition for causality is also provided, in addition to an algorithm and corresponding Wolfram Mathematica code for the numerical computation of the moving average coefficients.
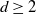
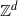
Remarks on Kolmogorov’s constant for simple branching processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 April 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recent investigations have argued that there is a simple explicit representation for the Kolmogorov constant c associated with the subcritical Galton–Watson branching process. We exhibit examples showing that although this representation can be valid, it more often is not. Our work is presented in terms of the limiting conditional mean population size
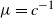 $\mu=c^{-1}$. The analogous quantity for the Markov branching process is denoted by
$\mu=c^{-1}$. The analogous quantity for the Markov branching process is denoted by 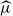 $\widehat\mu$. We show that the simple representation put forward for
$\widehat\mu$. We show that the simple representation put forward for 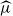 $\widehat\mu$ in fact is an upper bound that is attained only if the offspring-number probability-generating function is quadratic. The conditional mean
$\widehat\mu$ in fact is an upper bound that is attained only if the offspring-number probability-generating function is quadratic. The conditional mean 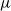 $\mu$ is the limit of a computable increasing sequence
$\mu$ is the limit of a computable increasing sequence 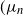 $(\mu_n$). Estimates of n are determined ensuring that, for any small positive number
$(\mu_n$). Estimates of n are determined ensuring that, for any small positive number  $\varepsilon$,
$\varepsilon$, 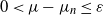 $0\lt\mu-\mu_n\le \varepsilon$.
$0\lt\mu-\mu_n\le \varepsilon$.
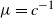
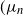

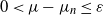
Diffusion limited aggregation in the layers model
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 April 2026, pp. 1-29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The attribution crisis in LLM search results: Estimating ecosystem exploitation
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 28 April 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From the field: a case of zoonotic transmission of Giardia duodenalis from wild reindeer?
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 27 April 2026, e65
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Digital twin for virtual sensing of ferry quays via a Gaussian process latent force model
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 27 April 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ASB volume 56 issue 2 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 24 April 2026, pp. f1-f2
- Print publication:
- May 2026
-
- Article
-
- You have access
- Export citation
Strong uniform convergence of Laplacians of random geometric and directed kNN graphs on compact manifolds
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 24 April 2026, pp. 1-36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Consider n points independently sampled from a density p of class
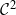 $\mathcal{C}^2$ on a smooth compact d-dimensional submanifold
$\mathcal{C}^2$ on a smooth compact d-dimensional submanifold 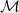 $\mathcal{M}$ of
$\mathcal{M}$ of 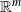 $\mathbb{R}^m$, and consider the random walk visiting these points according to a transition kernel K. We study the almost sure uniform convergence of the generator of this process to the diffusive Laplace–Beltrami operator when n tends to infinity, from which we establish the convergence of the random walk to a diffusion process on the manifold. In contrast to known results, our result does not require the kernel K to be continuous, which covers the cases of walks exploring k-nearest neighbor (kNN) and geometric graphs, and convergence rates are given. The distance between the random walk generator and the limiting operator is separated into several terms: a statistical term, related to the law of large numbers, is treated with concentration tools and an approximation term that we control with tools from differential geometry. The case of kNN Laplacians is detailed. The convergence of the stochastic processes having these operators as generators is also studied, by establishing additional tightness results of their distributions on the space of càdlàg functions.
$\mathbb{R}^m$, and consider the random walk visiting these points according to a transition kernel K. We study the almost sure uniform convergence of the generator of this process to the diffusive Laplace–Beltrami operator when n tends to infinity, from which we establish the convergence of the random walk to a diffusion process on the manifold. In contrast to known results, our result does not require the kernel K to be continuous, which covers the cases of walks exploring k-nearest neighbor (kNN) and geometric graphs, and convergence rates are given. The distance between the random walk generator and the limiting operator is separated into several terms: a statistical term, related to the law of large numbers, is treated with concentration tools and an approximation term that we control with tools from differential geometry. The case of kNN Laplacians is detailed. The convergence of the stochastic processes having these operators as generators is also studied, by establishing additional tightness results of their distributions on the space of càdlàg functions.
ASB volume 56 issue 2 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 24 April 2026, pp. b1-b5
- Print publication:
- May 2026
-
- Article
-
- You have access
- Export citation
A Markov ageing-based multi-state group self-annuitisation
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 24 April 2026, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On stochastic properties of random age and remaining lifetime for populations of manufactured items
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 23 April 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Does Hamiltonian Monte Carlo mix faster than a random walk on multimodal densities?
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 23 April 2026, pp. 1-48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Hamiltonian Monte Carlo (HMC) is a very popular collection of Markov chain Monte Carlo (MCMC) algorithms. One explanation for the popularity of HMC algorithms is their excellent performance as the dimension d of the target becomes large: theoretical analyses show that popular versions of HMC can have a running time that scales as well as
 $d^{0.25}$ in good conditions, while even an optimally tuned random-walk metropolis (RWM) algorithm will not do better than d. In this paper, we investigate a different scaling question: does HMC beat RWM for targets with well-separated modes? We find that the answer is often no. Our main tool for answering this question is a novel and simple formula for the conductance of HMC based on Liouville’s theorem, and we also show how this new formula can be used to give very short proofs of results that seem tedious to show with the usual formula. We also use this result to compute the spectral gap of HMC algorithms, for both the classical HMC with isotropic momentum and the recent Riemannian HMC, for multimodal targets. While we focus on the concrete comparison of RWM and HMC, we expect qualitatively similar conclusions to hold for other gradient-based algorithms.
$d^{0.25}$ in good conditions, while even an optimally tuned random-walk metropolis (RWM) algorithm will not do better than d. In this paper, we investigate a different scaling question: does HMC beat RWM for targets with well-separated modes? We find that the answer is often no. Our main tool for answering this question is a novel and simple formula for the conductance of HMC based on Liouville’s theorem, and we also show how this new formula can be used to give very short proofs of results that seem tedious to show with the usual formula. We also use this result to compute the spectral gap of HMC algorithms, for both the classical HMC with isotropic momentum and the recent Riemannian HMC, for multimodal targets. While we focus on the concrete comparison of RWM and HMC, we expect qualitatively similar conclusions to hold for other gradient-based algorithms.


Bias!
- How Systemic Error Threatens Biomedical Research
-
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026
The structural origins of the conservative online media niche, US Twitter 2022
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 22 April 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quasistatic approximation to time-inhomogeneous stochastic differential equations
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 22 April 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This work studies time averages of an observable
 $h(t,X_t)$, where
$h(t,X_t)$, where  $X_t$ is the solution to a time-inhomogeneous stochastic differential equation (SDE) driven by drift, b(t, x), and diffusion,
$X_t$ is the solution to a time-inhomogeneous stochastic differential equation (SDE) driven by drift, b(t, x), and diffusion,  $\sigma(t{,}{\kern.5pt}x)$, that change sufficiently slowly in time. In this quasistatic regime we derive an approximation to the time average that is computable from properties of the time-homogeneous SDEs driven by
$\sigma(t{,}{\kern.5pt}x)$, that change sufficiently slowly in time. In this quasistatic regime we derive an approximation to the time average that is computable from properties of the time-homogeneous SDEs driven by  $b(t,\cdot)$ and
$b(t,\cdot)$ and  $\sigma(t,\cdot)$ with fixed t; specifically, we utilize
$\sigma(t,\cdot)$ with fixed t; specifically, we utilize  $\log$-Sobolev inequalities for the instantaneous invariant distribution and generator for each t. We obtain explicit non-asymptotic error bounds on this quasistatic approximation, both in the form of concentration inequalities and bounds on the expected value. The error bounds demonstrate a competition between the speed of convergence to the instantaneous invariant distributions and their rate of change, matching the intuition that underlies the quasistatic approximation.
$\log$-Sobolev inequalities for the instantaneous invariant distribution and generator for each t. We obtain explicit non-asymptotic error bounds on this quasistatic approximation, both in the form of concentration inequalities and bounds on the expected value. The error bounds demonstrate a competition between the speed of convergence to the instantaneous invariant distributions and their rate of change, matching the intuition that underlies the quasistatic approximation.






HIGH-DIMENSIONAL NEWEY–POWELL TEST VIA APPROXIMATE MESSAGE PASSING
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 21 April 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We propose a high-dimensional extension of the heteroscedasticity test proposed in Newey and Powell (1987). Our test is based on expectile regression in the proportional asymptotic regime where
 $n/p \to \delta \in (0,1]$. The asymptotic analysis of the test statistic uses the approximate message passing algorithm, from which we obtain the limiting distribution of the test and establish its asymptotic power. The numerical performance of the test is validated through an extensive simulation study. As real-data applications, we present the analysis based on “international economic growth” data (Belloni et al., 2013), which is found to be homoscedastic, and “supermarket” data (Lan et al., 2016), which is found to be heteroscedastic.
$n/p \to \delta \in (0,1]$. The asymptotic analysis of the test statistic uses the approximate message passing algorithm, from which we obtain the limiting distribution of the test and establish its asymptotic power. The numerical performance of the test is validated through an extensive simulation study. As real-data applications, we present the analysis based on “international economic growth” data (Belloni et al., 2013), which is found to be homoscedastic, and “supermarket” data (Lan et al., 2016), which is found to be heteroscedastic.

Asymptotic error distribution of the Euler scheme for stochastic delay differential equations with locally Lipschitz coefficients
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 20 April 2026, pp. 1-43
-
- Article
- Export citation
-
This paper focuses mainly on the Euler scheme of stochastic delay differential equations with locally Lipschitz coefficients. The convergence in probability of the Euler scheme and the corresponding weak limit process of the normalized error process are derived. Furthermore, this paper also considers a class of specific degenerate stochastic delay equations and obtains the associated weak limit process for the stronger error process. The error parameter of this stronger error process for such a degenerate system is n instead of
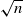 $\sqrt{n}$ in the normalized error process. This causes substantial challenges in the analysis and proofs and the weak limit process also becomes more complicated and involves some additional terms. This result is new and interesting even for the non-delay case.
$\sqrt{n}$ in the normalized error process. This causes substantial challenges in the analysis and proofs and the weak limit process also becomes more complicated and involves some additional terms. This result is new and interesting even for the non-delay case.
Reading between the green lines: A framework for scalable greenwashing detection
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 20 April 2026, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Historical reconstruction of the earliest enterovirus A71 epidemics in Japan in the 1960s
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 20 April 2026, e57
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A new credibility estimation of process variance with applications
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 20 April 2026, pp. 1-30
-
- Article
- Export citation
