Refine search
Actions for selected content:
53172 results in Statistics and Probability
Mean-field stochastic Volterra equations
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Investigation of a prolonged nursery outbreak of Salmonella Poona in England identified using whole genome sequencing, 2016–2021
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 07 April 2026, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dynamic screening strategies for the control of a prolonged vancomycin-resistant enterococci outbreak: A decade-long study in a Japanese tertiary hospital
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 07 April 2026, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparing wastewater-based and case-based Rt estimates of SARS-CoV-2 transmission in Georgia using generalized linear mixed models
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e63
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The COVID-19 pandemic has highlighted limitations in case-based surveillance due to inconsistent testing and reporting. Wastewater-based epidemiology (WBE) has emerged as a complementary surveillance approach for tracking SARS-CoV-2 transmission, capturing both symptomatic and asymptomatic infections. The aim of this study was to evaluate the effectiveness of WBE in estimating the effective reproduction number (
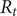 $ {R}_t $) of SARS-CoV-2 in Georgia, USA. We used a Generalized Linear Mixed Model (GLMM) to analyse viral concentration data from multiple wastewater treatment plants (WWTPs) collected between 1 June 2022 and 15 December 2022. After controlling for flow rates and site-level heterogeneity, model residuals were transformed into a non-negative incidence-like series used to estimate wastewater-based
$ {R}_t $) of SARS-CoV-2 in Georgia, USA. We used a Generalized Linear Mixed Model (GLMM) to analyse viral concentration data from multiple wastewater treatment plants (WWTPs) collected between 1 June 2022 and 15 December 2022. After controlling for flow rates and site-level heterogeneity, model residuals were transformed into a non-negative incidence-like series used to estimate wastewater-based 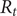 $ {R}_t $. Wastewater-based
$ {R}_t $. Wastewater-based 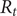 $ {R}_t $was compared with case-based
$ {R}_t $was compared with case-based 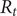 $ {R}_t $estimates using Spearman correlation. The two
$ {R}_t $estimates using Spearman correlation. The two 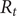 $ {R}_t $ estimates showed concordant temporal patterns across most sites, with stronger correlations in areas with higher case counts (Spearman correlations ranging from 0.39 to 0.84,
$ {R}_t $ estimates showed concordant temporal patterns across most sites, with stronger correlations in areas with higher case counts (Spearman correlations ranging from 0.39 to 0.84, 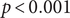 $ p<0.001 $). Wastewater-based
$ p<0.001 $). Wastewater-based 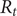 $ {R}_t $ tracked increases and decreases in transmission over similar time scales as case-based estimates, while exhibiting reduced sensitivity to short-term changes in clinical testing and reporting behaviour. These findings suggest that WBE can support estimation of transmission trends and complement traditional case-based surveillance for public health monitoring.
$ {R}_t $ tracked increases and decreases in transmission over similar time scales as case-based estimates, while exhibiting reduced sensitivity to short-term changes in clinical testing and reporting behaviour. These findings suggest that WBE can support estimation of transmission trends and complement traditional case-based surveillance for public health monitoring.
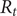
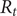
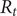
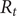
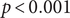
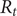
Perfect partitions of a random set of integers
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
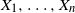 $X_1,\ldots, X_n$ be independent integers distributed uniformly on [M],
$X_1,\ldots, X_n$ be independent integers distributed uniformly on [M], 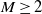 $M\ge 2$. A partition S of [n] into
$M\ge 2$. A partition S of [n] into  $\nu$ non-empty subsets
$\nu$ non-empty subsets 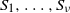 $S_1,\ldots, S_{\nu}$ is called perfect if all
$S_1,\ldots, S_{\nu}$ is called perfect if all  $\nu$ values
$\nu$ values  $\sum_{j\in S_{\alpha}}X_j$ are equal. For a perfect partition to exist,
$\sum_{j\in S_{\alpha}}X_j$ are equal. For a perfect partition to exist, 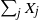 $\sum_j X_j$ has to be divisible by
$\sum_j X_j$ has to be divisible by  $\nu$. In 2001, for
$\nu$. In 2001, for 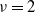 $\nu=2$, Christian Borgs, Jennifer Chayes, and the author proved that, conditioned on
$\nu=2$, Christian Borgs, Jennifer Chayes, and the author proved that, conditioned on 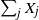 $\sum_j X_j$ being even, with high probability a perfect partition exists if
$\sum_j X_j$ being even, with high probability a perfect partition exists if 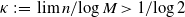 $\kappa\;:\!=\; \lim {{n}/{\log M}}>{{1}/{\log 2}}$, and that with high probability no perfect partition exists if
$\kappa\;:\!=\; \lim {{n}/{\log M}}>{{1}/{\log 2}}$, and that with high probability no perfect partition exists if 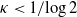 $\kappa<{{1}/{\log 2}}$. Responding to a question by George Varghese, we prove that for
$\kappa<{{1}/{\log 2}}$. Responding to a question by George Varghese, we prove that for  $\nu\ge 3$ with high probability no perfect partition exists if
$\nu\ge 3$ with high probability no perfect partition exists if  $\kappa<{{2}/{\log \nu}}$, which is twice as large as the naive threshold
$\kappa<{{2}/{\log \nu}}$, which is twice as large as the naive threshold  $1/\log 3$ for
$1/\log 3$ for 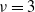 $\nu=3$. We identify the range of
$\nu=3$. We identify the range of  $\kappa$ where the expected number of perfect partitions is exponentially high. We show that for
$\kappa$ where the expected number of perfect partitions is exponentially high. We show that for 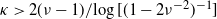 $\kappa> {{2(\nu-1)}/{\log[(1-2\nu^{-2})^{-1}]}}$ the total number of perfect partitions is exponentially high with probability
$\kappa> {{2(\nu-1)}/{\log[(1-2\nu^{-2})^{-1}]}}$ the total number of perfect partitions is exponentially high with probability 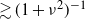 $\gtrsim (1+\nu^2)^{-1}$, i.e. below
$\gtrsim (1+\nu^2)^{-1}$, i.e. below  $1/\nu$, the limiting probability that
$1/\nu$, the limiting probability that 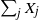 $\sum_j X_j$ is divisible by
$\sum_j X_j$ is divisible by  $\nu$.
$\nu$.
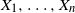
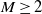

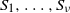


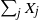

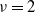
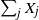
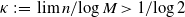
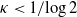



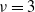

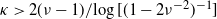
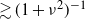

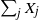

Reducing antimicrobial use in livestock alone may be not sufficient to reduce antimicrobial resistance among human Campylobacter infections: an ecological study in the Netherlands – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RANDOMIZED TESTING FOR JUMP DETECTION
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-42
-
- Article
- Export citation
Stakeholder engagement for sustainable open research data support services: insights from interviews and surveys in Switzerland
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE ECONOMETRIC THEORY INTERVIEW: PROFESSOR MARCO LIPPI
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-37
-
- Article
- Export citation
Disease burden associated with influenza activity at the population level
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Weak convergence of the integral of semi-Markov processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the asymptotic properties, in the weak sense, of regenerative processes and Markov renewal processes. For the latter, we derive both renewal-type results, also concerning the related counting process, and ergodic-type results, including the so-called
 $\varphi$-mixing property. This theoretical framework permits us to study the weak limit of the integral of a semi-Markov process, which can be interpreted as the position of a particle moving with finite velocities, taken for a random time according to the Markov renewal process underlying the semi-Markov one. Under mild conditions, we obtain the weak convergence to scaled Brownian motion. As a particular case, this result establishes the weak convergence of the classical generalized telegraph process.
$\varphi$-mixing property. This theoretical framework permits us to study the weak limit of the integral of a semi-Markov process, which can be interpreted as the position of a particle moving with finite velocities, taken for a random time according to the Markov renewal process underlying the semi-Markov one. Under mild conditions, we obtain the weak convergence to scaled Brownian motion. As a particular case, this result establishes the weak convergence of the classical generalized telegraph process.

Invasive meningococcal B disease: Spatiotemporal cluster identification using finetype data, the Netherlands, 2005–2023
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Are large pre-trained vision language models effective construction safety inspectors
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Financial valuation of retirement village via stochastic modelling of disability prevalence rates
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 31 March 2026, pp. 447-473
- Print publication:
- May 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The final outcome of SIR epidemics with infectivity profiles
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 31 March 2026, pp. 1-23
-
- Article
- Export citation
-
A stochastic model for the spread of an SIR (susceptible
 $\to$ infective
$\to$ infective  $\to$ removed) epidemic is considered. Infectives have independent and identically distributed infectivity profiles, which describe their infectiousness as a function of time since infection. The individual-to-individual infection rate depends also on the number of susceptibles present in the population. Exact results are derived for the distribution of statistics defined on the final outcome of the epidemic, including its final size. These are proved by using a generalisation of a Sellke construction to show that the distribution of the final outcome of the epidemic is the same as that of an associated discrete-time epidemic process, in which infectives are considered one at a time, and exploiting connection with death processes to analyse the final outcome of the latter. The results generalise easily to multipopulation epidemics.
$\to$ removed) epidemic is considered. Infectives have independent and identically distributed infectivity profiles, which describe their infectiousness as a function of time since infection. The individual-to-individual infection rate depends also on the number of susceptibles present in the population. Exact results are derived for the distribution of statistics defined on the final outcome of the epidemic, including its final size. These are proved by using a generalisation of a Sellke construction to show that the distribution of the final outcome of the epidemic is the same as that of an associated discrete-time epidemic process, in which infectives are considered one at a time, and exploiting connection with death processes to analyse the final outcome of the latter. The results generalise easily to multipopulation epidemics.
A forward algorithm for a class of Markov zero-sum stopping games
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 31 March 2026, pp. 1-28
-
- Article
- Export citation
Privacy preserving neural network predictive modelling in insurance using horizontal federated learning
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 31 March 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal periodic–classical barrier strategies for spectrally negative Lévy processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 31 March 2026, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Guaranteed minimum income benefit valuation via a numéraire transformation approach
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 30 March 2026, pp. 474-509
- Print publication:
- May 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal hurdle rate and investment policy in lifetime pension pools
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 30 March 2026, pp. 389-419
- Print publication:
- May 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
