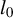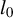Refine search
Actions for selected content:
53172 results in Statistics and Probability
Portfolio alignment metrics: what are they and how are they used in net zero investing?
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 03 March 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
De Finetti’s control for refracted skew Brownian motion
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-42
-
- Article
- Export citation
Relative and divergence measures based on extropy: dynamic forms and properties
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Non-asymptotic analysis of online noisy stochastic gradient descent
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random spherical disc–polygons and a duality
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Graduating mortality base tables: theory and practice part 2
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multi-state linear three-dimensional consecutive k-type systems
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 3 / July 2026
- Published online by Cambridge University Press:
- 02 March 2026, pp. 471-491
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Consecutive
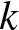 $k$-type systems have become important in both reliability theory and applications; in spite of a large literature existing on them, three-dimensional consecutive
$k$-type systems have become important in both reliability theory and applications; in spite of a large literature existing on them, three-dimensional consecutive 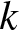 $k$-type systems have not yet been studied for multi-state case. In this paper, we introduce several different types of multi-state linear three-dimensional consecutive
$k$-type systems have not yet been studied for multi-state case. In this paper, we introduce several different types of multi-state linear three-dimensional consecutive 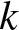 $k$-type systems for the first time, with due consideration to possible overlapping of failure blocks. The finite Markov chain imbedding approach is then used for the derivation of their reliability functions with state spaces and transition matrices provided in a novel way, and the involved computational process is illustrated through several numerical examples. Finally, some possible applications of the work and potential extensions are pointed out.
$k$-type systems for the first time, with due consideration to possible overlapping of failure blocks. The finite Markov chain imbedding approach is then used for the derivation of their reliability functions with state spaces and transition matrices provided in a novel way, and the involved computational process is illustrated through several numerical examples. Finally, some possible applications of the work and potential extensions are pointed out.
Graduating mortality base tables: theory and practice part 1
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On asymptotic behavior of time of extinction of critical bisexual branching process in random environment
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-13
-
- Article
- Export citation
-
We consider a critical bisexual branching process in a random environment generated by independent and identically distributed random variables. Assuming that the process starts with a large number of pairs N, we prove that its extinction time is of order
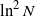 $\ln^2 N$. Interestingly, this result is valid for a general class of mating functions. Among these are the functions describing the monogamous and polygamous behavior of couples, as well as the function reducing the bisexual branching process to the simple one.
$\ln^2 N$. Interestingly, this result is valid for a general class of mating functions. Among these are the functions describing the monogamous and polygamous behavior of couples, as well as the function reducing the bisexual branching process to the simple one.
UNIFORM INFERENCE FOR NONPARAMETRIC PANEL MODELS WITH FIXED EFFECTS
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-29
-
- Article
- Export citation
-
This article studies uniform inference on a function
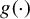 $g(\cdot )$ and its functionals in a nonparametric panel data model with fixed effects. The nonparametric panel model relaxes restrictions on time-series behavior by allowing for arbitrary types of stationary or nonstationary dependence (e.g., stationary mixingale, mildly stationary, or local-to-unity process). After removing the fixed effects via transformations, a sieve estimator is proposed, accompanied by Yurinskii’s coupling principle of Gaussian processes and uniform confidence bands (UCBs) that rely on the sieve score bootstrap method to test for linear functionals of
$g(\cdot )$ and its functionals in a nonparametric panel data model with fixed effects. The nonparametric panel model relaxes restrictions on time-series behavior by allowing for arbitrary types of stationary or nonstationary dependence (e.g., stationary mixingale, mildly stationary, or local-to-unity process). After removing the fixed effects via transformations, a sieve estimator is proposed, accompanied by Yurinskii’s coupling principle of Gaussian processes and uniform confidence bands (UCBs) that rely on the sieve score bootstrap method to test for linear functionals of 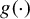 $g(\cdot )$. Under the asymptotic framework of an increasing cross-sectional dimension and either a fixed or diverging time dimension, we prove that the bootstrapping Kolmogorov–Smirnov (sup-type) test has asymptotic uniform size controls. This article shows that our uniform inference procedure can be extended to the two-way fixed-effects nonparametric panel model with stationary mixingale regressors. Extensive simulations confirm that our sieve estimators and their UCBs work well in finite samples. The present article further applies the above methods to empirical settings and finds some interesting results in nonlinear patterns of consumption concerning income shocks and asset holdings.
$g(\cdot )$. Under the asymptotic framework of an increasing cross-sectional dimension and either a fixed or diverging time dimension, we prove that the bootstrapping Kolmogorov–Smirnov (sup-type) test has asymptotic uniform size controls. This article shows that our uniform inference procedure can be extended to the two-way fixed-effects nonparametric panel model with stationary mixingale regressors. Extensive simulations confirm that our sieve estimators and their UCBs work well in finite samples. The present article further applies the above methods to empirical settings and finds some interesting results in nonlinear patterns of consumption concerning income shocks and asset holdings.
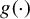
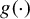
Self-normalized Cramér-type moderate deviation of stochastic gradient Langevin dynamics
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Paediatric infection hospital admissions in England before, during, and after the COVID-19 pandemic
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Antimicrobial prescribing patterns at a South African tertiary referral hospital: Insights from three global point prevalence surveys
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Can time-series foundation models perform building energy management tasks?
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Applied Probability Trust Donations 2025
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 07 April 2026, p. 472
- Print publication:
- March 2026
-
- Article
- Export citation
Autochthonous transmission of dengue in Europe, with special attention to the Spanish context
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 27 February 2026, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Risk Measures
- An Introduction to the Mathematical Theory
-
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026
Gaussian process models in actuarial science
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 26 February 2026, pp. 1-6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random walks in a time-inhomogeneous random environment conditioned to stay positive
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-13
-
- Article
- Export citation
DIRECTION IDENTIFICATION AND MINIMAX ESTIMATION IN HIGH-DIMENSIONAL SPARSE REGRESSION VIA A GENERALIZED EIGENVALUE APPROACH
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In high-dimensional (HD) sparse linear regression, parameter selection and estimation are addressed using a constraint
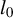 $l_0$ on the direction of the parameter vector. We begin by establishing a general result that identifies this direction through the leading generalized eigenspace of specific measurable matrices. Using this result, we propose a novel approach to the selection of the best subsets by solving an empirical generalized eigenvalue problem to estimate the direction of the HD parameter. We then introduce a new estimator based on the RIFLE algorithm, providing a non-asymptotic bound for the estimation risk, minimax convergence, and a central limit theorem. Simulations demonstrate the superiority of our method over existing
$l_0$ on the direction of the parameter vector. We begin by establishing a general result that identifies this direction through the leading generalized eigenspace of specific measurable matrices. Using this result, we propose a novel approach to the selection of the best subsets by solving an empirical generalized eigenvalue problem to estimate the direction of the HD parameter. We then introduce a new estimator based on the RIFLE algorithm, providing a non-asymptotic bound for the estimation risk, minimax convergence, and a central limit theorem. Simulations demonstrate the superiority of our method over existing 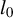 $l_0$-constrained estimators.
$l_0$-constrained estimators.