Refine search
Actions for selected content:
53172 results in Statistics and Probability
Spatiotemporal trends in tetracycline- and trimethoprim–sulfamethoxazole-resistant S. aureus among veteran outpatients in the eastern United States
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 23 February 2026, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How nations narrate quantum policy: A topic modeling approach to national quantum strategies
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 23 February 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ordering of extreme order statistics among q-Weibull random variables
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 3 / July 2026
- Published online by Cambridge University Press:
- 23 February 2026, pp. 416-439
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The
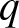 $q$-Weibull distribution, as a generalization of the Weibull distribution, plays an important role in the field of reliability theory, survival analysis, finance, engineering, medical science, etc. In contrast to the Weibull distribution, which is limited to describing monotonic hazard rate functions, the
$q$-Weibull distribution, as a generalization of the Weibull distribution, plays an important role in the field of reliability theory, survival analysis, finance, engineering, medical science, etc. In contrast to the Weibull distribution, which is limited to describing monotonic hazard rate functions, the 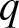 $q$-Weibull distribution offers the flexibility to model various behaviors of the hazard rate function, including unimodal, bathtub-shaped, monotonic (both increasing and decreasing), and constant. In this article, we investigated the stochastic comparison of extreme order statistics derived from independent, heterogeneous
$q$-Weibull distribution offers the flexibility to model various behaviors of the hazard rate function, including unimodal, bathtub-shaped, monotonic (both increasing and decreasing), and constant. In this article, we investigated the stochastic comparison of extreme order statistics derived from independent, heterogeneous 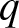 $q$-Weibull random variables using various stochastic orderings, including the usual stochastic order, hazard rate order, reversed hazard rate order, and likelihood ratio order. Some of these results are further extended to dependent setups by incorporating Archimedean copulas to model the dependence structure. Finally, we explored the behavior of extreme order statistics when the random variables are subjected to random shocks.
$q$-Weibull random variables using various stochastic orderings, including the usual stochastic order, hazard rate order, reversed hazard rate order, and likelihood ratio order. Some of these results are further extended to dependent setups by incorporating Archimedean copulas to model the dependence structure. Finally, we explored the behavior of extreme order statistics when the random variables are subjected to random shocks.
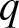
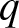
Total variation distance between SDEs with stable noise and Brownian motion
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-19
-
- Article
- Export citation
-
We consider d-dimensional stochastic differential equations (SDEs) of the form
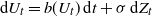 $\textrm{d}U_t = b(U_t)\,\textrm{d}t + \sigma\,\textrm{d}Z_t$. Let
$\textrm{d}U_t = b(U_t)\,\textrm{d}t + \sigma\,\textrm{d}Z_t$. Let 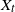 $X_t$ denote the solution if the driving noise
$X_t$ denote the solution if the driving noise 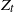 $Z_t$ is a d-dimensional rotationally symmetric
$Z_t$ is a d-dimensional rotationally symmetric  $\alpha$-stable process (
$\alpha$-stable process (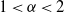 $1\lt \alpha\lt 2$), and let
$1\lt \alpha\lt 2$), and let 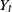 $Y_t$ be the solution if the driving noise is a d-dimensional Brownian motion. Continuing the work started in Deng et al. (2025), we derive an estimate of the total variation distance
$Y_t$ be the solution if the driving noise is a d-dimensional Brownian motion. Continuing the work started in Deng et al. (2025), we derive an estimate of the total variation distance 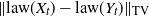 $\|\textrm{law}(X_{t})-\textrm{law}(Y_{t})\|_\textrm{TV}$ for all
$\|\textrm{law}(X_{t})-\textrm{law}(Y_{t})\|_\textrm{TV}$ for all 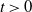 $t \gt 0$, and we show that the ergodic measures
$t \gt 0$, and we show that the ergodic measures 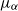 $\mu_\alpha$ and
$\mu_\alpha$ and 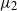 $\mu_2$ of
$\mu_2$ of 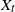 $X_t$ and
$X_t$ and 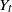 $Y_t$, respectively, satisfy
$Y_t$, respectively, satisfy 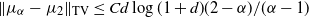 $\|\mu_\alpha-\mu_2\|_\textrm{TV} \leq {Cd\log(1+d)}(2-\alpha)/({\alpha-1})$. We show that this bound is optimal with respect to
$\|\mu_\alpha-\mu_2\|_\textrm{TV} \leq {Cd\log(1+d)}(2-\alpha)/({\alpha-1})$. We show that this bound is optimal with respect to  $\alpha$ by an Ornstein–Uhlenbeck SDE. Combining this bound with a recent interpolation result from Huang et al. (2023), we can derive a bound in the Wasserstein-p distance (
$\alpha$ by an Ornstein–Uhlenbeck SDE. Combining this bound with a recent interpolation result from Huang et al. (2023), we can derive a bound in the Wasserstein-p distance (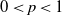 $0 \lt p \lt 1$):
$0 \lt p \lt 1$): 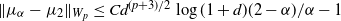 $\|\mu_\alpha-\mu_2\|_{W_p} \leq {Cd^{(p+3)/2}\log(1+d)}(2-\alpha)/{\alpha-1}$.
$\|\mu_\alpha-\mu_2\|_{W_p} \leq {Cd^{(p+3)/2}\log(1+d)}(2-\alpha)/{\alpha-1}$.
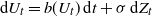

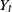
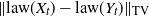
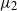
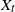
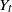
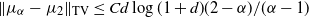

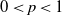
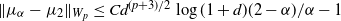
Embedded model form uncertainty quantification with measurement noise for Bayesian model calibration
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 23 February 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discovering the complexity of residual lifetimes of live components in the coherent system using cumulative residual extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 3 / July 2026
- Published online by Cambridge University Press:
- 23 February 2026, pp. 440-470
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the complexity of residual lifetimes of live components in coherent systems through the lens of cumulative residual extropy and its divergence-based extension, Jensen-cumulative residual extropy. Unlike classical reliability metrics that focus on system inactivity or mean residual life, our framework quantifies the hidden informational structure of components that remain alive at the system failure time. We derive closed-form expressions for the cumulative residual extropy of conditional residual lifetimes using system signatures and establish stochastic bounds and comparisons that highlight the impact of structural configuration. A novel divergence measure, the Jensen-cumulative residual extropy, is introduced to capture discrepancies between coherent systems and benchmark
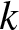 $k$-out-of-
$k$-out-of-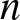 $n$ structures. Numerical illustrations with gamma-distributed lifetimes demonstrate the sensitivity of cumulative residual extropy and Jensen-cumulative residual extropy to redundancy patterns and dependence structures. Furthermore, by integrating cost considerations into the divergence framework, we provide a rigorous optimization scheme for selecting system signatures that jointly minimize informational complexity and economic expenditure. The proposed approach enriches the theoretical foundation of reliability analysis and offers practical guidelines for designing resilient, cost-effective, and information-efficient engineering systems.
$n$ structures. Numerical illustrations with gamma-distributed lifetimes demonstrate the sensitivity of cumulative residual extropy and Jensen-cumulative residual extropy to redundancy patterns and dependence structures. Furthermore, by integrating cost considerations into the divergence framework, we provide a rigorous optimization scheme for selecting system signatures that jointly minimize informational complexity and economic expenditure. The proposed approach enriches the theoretical foundation of reliability analysis and offers practical guidelines for designing resilient, cost-effective, and information-efficient engineering systems.
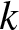
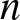
Hedging targeted risks with reinforcement learning: application to life insurance contracts with embedded guarantees
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 20 February 2026, pp. 420-446
- Print publication:
- May 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Spatio-temporal modelling of dengue counts in the Central Valley of Costa Rica
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 20 February 2026, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal reinsurance under endogenous default and background risk
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 20 February 2026, pp. 537-562
- Print publication:
- May 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The limiting spectral distribution of the noncentral unified matrix model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 20 February 2026, pp. 772-787
- Print publication:
- June 2026
-
- Article
- Export citation
-
We investigate the limiting spectral distribution of a noncentral unified matrix model defined by
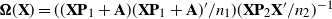 $\boldsymbol{\Omega}(\mathbf{X}) = ({(\mathbf{X}\mathbf{P}_1+\mathbf{A})(\mathbf{X}\mathbf{P}_1+\mathbf{A})'}/{n_1}) ({\mathbf{X}\mathbf{P}_2\mathbf{X}'}/{n_2})^{-1}$, where
$\boldsymbol{\Omega}(\mathbf{X}) = ({(\mathbf{X}\mathbf{P}_1+\mathbf{A})(\mathbf{X}\mathbf{P}_1+\mathbf{A})'}/{n_1}) ({\mathbf{X}\mathbf{P}_2\mathbf{X}'}/{n_2})^{-1}$, where 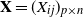 $\mathbf{X}=(X_{ij})_{p\times n}$ is a random matrix with independent and identically distributed real entries having zero mean and finite second moment.
$\mathbf{X}=(X_{ij})_{p\times n}$ is a random matrix with independent and identically distributed real entries having zero mean and finite second moment. 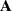 $\mathbf{A}$ is a
$\mathbf{A}$ is a 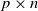 $p\times n$ nonrandom matrix. The matrices
$p\times n$ nonrandom matrix. The matrices 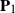 $\mathbf{P}_1$ and
$\mathbf{P}_1$ and 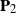 $\mathbf{P}_2$ are projection matrices satisfying
$\mathbf{P}_2$ are projection matrices satisfying 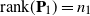 $\mathrm{rank}(\mathbf{P}_1)=n_1$,
$\mathrm{rank}(\mathbf{P}_1)=n_1$, 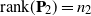 $\mathrm{rank}(\mathbf{P}_2)=n_2$, and
$\mathrm{rank}(\mathbf{P}_2)=n_2$, and 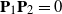 $\mathbf{P}_1\mathbf{P}_2=0$. When
$\mathbf{P}_1\mathbf{P}_2=0$. When 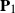 $\mathbf{P}_1$ and
$\mathbf{P}_1$ and 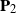 $\mathbf{P}_2$ are random, they are assumed to be independent of
$\mathbf{P}_2$ are random, they are assumed to be independent of 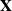 $\mathbf{X}$. When
$\mathbf{X}$. When 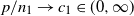 $p/n_1\to c_1\in(0,\infty)$ and
$p/n_1\to c_1\in(0,\infty)$ and 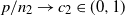 $p/n_2\to c_2\in(0,1)$, we establish the almost sure convergence of the empirical spectral distribution of
$p/n_2\to c_2\in(0,1)$, we establish the almost sure convergence of the empirical spectral distribution of 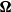 $\boldsymbol{\Omega}$ to a deterministic limiting distribution. Furthermore, we show that this limiting distribution coincides with that of the noncentral F-matrix, thus revealing a deep connection between the proposed model and classical multivariate analysis.
$\boldsymbol{\Omega}$ to a deterministic limiting distribution. Furthermore, we show that this limiting distribution coincides with that of the noncentral F-matrix, thus revealing a deep connection between the proposed model and classical multivariate analysis.
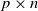
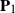
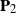
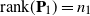
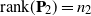
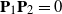
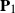
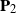
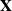
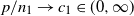
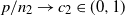
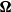
Principal component analysis and K-means clustering of fuel–air mixing in gas turbine combustors
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 19 February 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - Latent Variable Structural Equation Models
-
- Book:
- Elements of Structural Equation Models (SEMs)
- Published online:
- 05 February 2026
- Print publication:
- 19 February 2026, pp 411-499
-
- Chapter
- Export citation
Hints for the Exercises
-
- Book:
- High-Dimensional Probability
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 298-311
-
- Chapter
- Export citation
3 - Diversification, Convexity, and Coherence
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp 29-42
-
- Chapter
- Export citation
9 - Deviations of Random Matrices on Sets
-
- Book:
- High-Dimensional Probability
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 260-297
-
- Chapter
- Export citation
9 - Law-Determined Risk Measures on Lp-Spaces
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp 115-128
-
- Chapter
- Export citation
7 - Structural Equation Models with Categorical Indicators and Outcomes
-
- Book:
- Elements of Structural Equation Models (SEMs)
- Published online:
- 05 February 2026
- Print publication:
- 19 February 2026, pp 500-589
-
- Chapter
- Export citation
1 - Overview
-
- Book:
- Elements of Structural Equation Models (SEMs)
- Published online:
- 05 February 2026
- Print publication:
- 19 February 2026, pp 1-25
-
- Chapter
-
- You have access
- HTML
- Export citation
Copyright page
-
- Book:
- Elements of Structural Equation Models (SEMs)
- Published online:
- 05 February 2026
- Print publication:
- 19 February 2026, pp iv-iv
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp i-iv
-
- Chapter
- Export citation
