Refine search
Actions for selected content:
53172 results in Statistics and Probability
Effectiveness of voluntary PCR testing against COVID-19 spread in remote Japanese islands
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 24 March 2026, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Burden of comorbid disease, treatment, and healthcare utilization among people with HIV: A retrospective, cross-sectional study from a large healthcare organization
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 24 March 2026, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Changes and predictions of mumps incidence in China: a time series model with intervention approach
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 24 March 2026, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Frequency, dynamics, and duration of faecal shedding in SARS-CoV-2-infected individuals, a scoping review
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 24 March 2026, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An EM algorithm for estimating phase-type distributions with left-truncated and right-censored data
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 24 March 2026, pp. 1-20
-
- Article
- Export citation
On a risk model with tree-structured Poisson Markov random field frequency, with application to rainfall events
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 23 March 2026, pp. 317-343
- Print publication:
- May 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Barriers and facilitators of childhood immunization: sociodemographic and knowledge-related determinants among parents in rural and urban Khyber Pakhtunkhwa, Pakistan
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 23 March 2026, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Selecting key opinion leaders under practical challenges
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 23 March 2026, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Numerical approximation of McKean–Vlasov SDEs via stochastic gradient descent
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 23 March 2026, pp. 1-33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On reflected lévy processes with collapse
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 17 March 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Denoising image point clouds using segmentation and synthetic data for enhanced structural health analysis of tunnels
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 11 March 2026, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multifactor cat bond pricing using distortion operator models with recurrent neural networks
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 10 March 2026, pp. 344-366
- Print publication:
- May 2026
-
- Article
- Export citation
Trace reconstruction of matrices and hypermatrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 10 March 2026, pp. 356-374
-
- Article
- Export citation
-
A trace of a sequence is generated by deleting each bit of the sequence independently with a fixed probability. The well-studied trace reconstruction problem asks how many traces are required to reconstruct an unknown binary sequence with high probability. In this paper, we study the multidimensional version of this problem for matrices and hypermatrices, where a trace is generated by deleting each row/column of the matrix or each slice of the hypermatrix independently with a constant probability. Previously, Krishnamurthy, Mazumdar, McGregor and Pal showed that
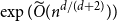 $\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown 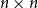 $n\times n$ matrix (for
$n\times n$ matrix (for 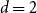 $d=2$) and any unknown
$d=2$) and any unknown 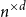 $n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around
$n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around 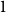 $1$, we improve this upper bound by showing that
$1$, we improve this upper bound by showing that 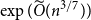 $\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown 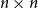 $n\times n$ matrix, and
$n\times n$ matrix, and 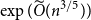 $\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown 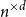 $n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from
$n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from 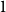 $1$ even as
$1$ even as 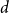 $d$ becomes very large.
$d$ becomes very large.
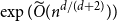
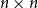
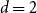
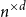
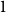
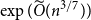
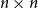
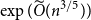
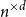
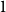
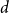
Direct economic and temporal burdens of nosocomial infections on orthopaedic patients: a nested case–control study
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 09 March 2026, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The probability that a random triangle in a cube is obtuse
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 09 March 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The illusion of the Web3 decentralization
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 09 March 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Strong survival and extinction for branching random walks via new order for generating functions
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-19
-
- Article
- Export citation
-
We consider general discrete-time multitype branching processes on a countable set X. According to these processes, a particle of type
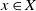 $x\in X$ generates a random number of children and chooses their type in X, not necessarily independently nor with the same law for different parent types. We introduce a new type of stochastic ordering of multitype branching processes, generalising the germ order introduced by Hutchcroft, which relies on the generating function of the process. We prove that given two multitype branching processes with laws
$x\in X$ generates a random number of children and chooses their type in X, not necessarily independently nor with the same law for different parent types. We introduce a new type of stochastic ordering of multitype branching processes, generalising the germ order introduced by Hutchcroft, which relies on the generating function of the process. We prove that given two multitype branching processes with laws 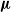 ${\boldsymbol{\mu}}$ and
${\boldsymbol{\mu}}$ and  ${\boldsymbol{\nu}}$ respectively, with
${\boldsymbol{\nu}}$ respectively, with 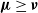 ${\boldsymbol{\mu}}\ge{\boldsymbol{\nu}}$, then in every set where there is survival according to
${\boldsymbol{\mu}}\ge{\boldsymbol{\nu}}$, then in every set where there is survival according to  ${\boldsymbol{\nu}}$, there is also survival according to
${\boldsymbol{\nu}}$, there is also survival according to 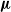 ${\boldsymbol{\mu}}$. Moreover, in every set where there is strong survival according to
${\boldsymbol{\mu}}$. Moreover, in every set where there is strong survival according to  ${\boldsymbol{\nu}}$, there is also strong survival according to
${\boldsymbol{\nu}}$, there is also strong survival according to 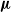 ${\boldsymbol{\mu}}$, provided that the supremum of the global extinction probabilities for the
${\boldsymbol{\mu}}$, provided that the supremum of the global extinction probabilities for the  ${\boldsymbol{\nu}}$ process, taken over all starting points x, is strictly smaller than 1. New conditions for survival and strong survival for inhomogeneous multitype branching processes are provided. We also extend a result of Moyal which claims that, under some conditions, the global extinction probability for a multitype branching process is the only fixed point of its generating function, whose supremum over all starting coordinates may be smaller than 1.
${\boldsymbol{\nu}}$ process, taken over all starting points x, is strictly smaller than 1. New conditions for survival and strong survival for inhomogeneous multitype branching processes are provided. We also extend a result of Moyal which claims that, under some conditions, the global extinction probability for a multitype branching process is the only fixed point of its generating function, whose supremum over all starting coordinates may be smaller than 1.
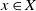
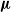

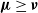



Analysis of clustering and degree index in random graphs and complex networks
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Monochromatic subgraphs in randomly colored dense multiplex networks
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-36
-
- Article
- Export citation
-
Given a sequence of graphs
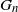 $G_n$ and a fixed graph H, denote by
$G_n$ and a fixed graph H, denote by 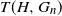 $T(H, G_n)$ the number of monochromatic copies of the graph H in a uniformly random c-coloring of the vertices of
$T(H, G_n)$ the number of monochromatic copies of the graph H in a uniformly random c-coloring of the vertices of 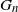 $G_n$. In this paper we study the joint distribution of a finite collection of monochromatic graph counts in networks with multiple layers (multiplex networks). Specifically, given a finite collection of graphs
$G_n$. In this paper we study the joint distribution of a finite collection of monochromatic graph counts in networks with multiple layers (multiplex networks). Specifically, given a finite collection of graphs 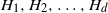 $H_1, H_2, \ldots, H_d$ we derive the joint distribution of
$H_1, H_2, \ldots, H_d$ we derive the joint distribution of 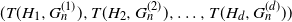 $(T(H_1, G_n^{(1)}), T(H_2, G_n^{(2)}), \ldots, T(H_d, G_n^{(d)}))$, where
$(T(H_1, G_n^{(1)}), T(H_2, G_n^{(2)}), \ldots, T(H_d, G_n^{(d)}))$, where 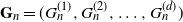 $\mathbf{G}_n = (G_n^{(1)}, G_n^{(2)}, \ldots, G_n^{(d)})$ is a collection of dense graphs on the same vertex set converging in the multiplex cut-metric. The limiting distribution is the sum of two independent components: a multivariate Gaussian and a sum of independent bivariate stochastic integrals. This extends previous results on the marginal convergence of monochromatic subgraphs in a sequence of graphs to the joint convergence of a finite collection of monochromatic subgraphs in a sequence of multiplex networks. Several applications and examples are discussed.
$\mathbf{G}_n = (G_n^{(1)}, G_n^{(2)}, \ldots, G_n^{(d)})$ is a collection of dense graphs on the same vertex set converging in the multiplex cut-metric. The limiting distribution is the sum of two independent components: a multivariate Gaussian and a sum of independent bivariate stochastic integrals. This extends previous results on the marginal convergence of monochromatic subgraphs in a sequence of graphs to the joint convergence of a finite collection of monochromatic subgraphs in a sequence of multiplex networks. Several applications and examples are discussed.
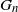
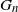
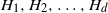
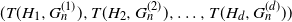
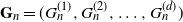
The largest subcritical component in inhomogeneous random graphs of preferential attachment type
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 04 March 2026, pp. 414-432
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
