Refine search
Actions for selected content:
53172 results in Statistics and Probability
INSTRUMENTAL VARIABLES ESTIMATION FOR INFINITE ORDER PANEL AUTOREGRESSIVE PROCESSES
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 30 March 2026, pp. 1-48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A label-switching algorithm for fast core-periphery identification
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 29 March 2026, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiserver-job response time under multilevel scaling
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the multiserver-job setting in the load-focused multilevel scaling limit, where system load approaches capacity much faster than the growth of the number of servers
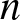 $n$. We consider the “1 and
$n$. We consider the “1 and 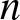 $n$” system, where each job requires either one server or all
$n$” system, where each job requires either one server or all 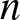 $n$. Within the multilevel scaling limit, we examine three regimes: load dominated by
$n$. Within the multilevel scaling limit, we examine three regimes: load dominated by 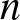 $n$-server jobs, 1-server jobs, or balanced. In each regime, we characterize the asymptotic growth rate of the boundary of the stability region and the scaled mean queue length. We demonstrate that mean queue length peaks near balanced load via theory, numerics, and simulation.
$n$-server jobs, 1-server jobs, or balanced. In each regime, we characterize the asymptotic growth rate of the boundary of the stability region and the scaled mean queue length. We demonstrate that mean queue length peaks near balanced load via theory, numerics, and simulation.
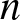
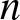
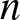
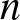
Transversal Hamilton cycles in digraph collections
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-57
-
- Article
-
- You have access
- HTML
- Export citation
-
Given a collection
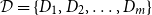 $\mathcal{D} =\{D_1,D_2,\ldots ,D_m\}$ of digraphs on the common vertex set
$\mathcal{D} =\{D_1,D_2,\ldots ,D_m\}$ of digraphs on the common vertex set 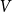 $V$, an
$V$, an  $m$-edge digraph
$m$-edge digraph 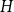 $H$ with vertices in
$H$ with vertices in 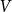 $V$ is transversal in
$V$ is transversal in 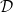 $\mathcal{D}$ if there exists a bijection
$\mathcal{D}$ if there exists a bijection 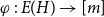 $\varphi \,:\,E(H)\rightarrow [m]$ such that
$\varphi \,:\,E(H)\rightarrow [m]$ such that 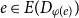 $e \in E(D_{\varphi (e)})$ for all
$e \in E(D_{\varphi (e)})$ for all 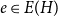 $e\in E(H)$. Ghouila-Houri proved that any
$e\in E(H)$. Ghouila-Houri proved that any  $n$-vertex digraph with minimum semi-degree at least
$n$-vertex digraph with minimum semi-degree at least 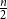 $\frac {n}{2}$ contains a directed Hamilton cycle. In this paper, we provide a transversal generalisation of Ghouila-Houri’s theorem, thereby solving a problem proposed by Chakraborti, Kim, Lee, and Seo. Our proof utilises the absorption method for transversals, the regularity method for digraph collections, as well as the transversal blow-up lemma and the related machinery. As an application, when
$\frac {n}{2}$ contains a directed Hamilton cycle. In this paper, we provide a transversal generalisation of Ghouila-Houri’s theorem, thereby solving a problem proposed by Chakraborti, Kim, Lee, and Seo. Our proof utilises the absorption method for transversals, the regularity method for digraph collections, as well as the transversal blow-up lemma and the related machinery. As an application, when  $n$ is sufficiently large, our result implies the transversal version of Dirac’s theorem, which was proved by Joos and Kim.
$n$ is sufficiently large, our result implies the transversal version of Dirac’s theorem, which was proved by Joos and Kim.
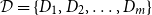

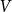
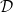
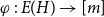
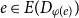
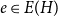

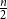

Indifference pricing of mortality-linked securities using backward stochastic differential equations
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 27 March 2026, pp. 510-536
- Print publication:
- May 2026
-
- Article
- Export citation
Record-biased permutations and their permuton limit
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 27 March 2026, pp. 375-413
-
- Article
- Export citation
Rough permutations with a fixed set of a given size
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
 $r, k, n$ be integers satisfying
$r, k, n$ be integers satisfying 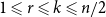 $1\leqslant r\leqslant k\leqslant n/2$. Let
$1\leqslant r\leqslant k\leqslant n/2$. Let 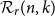 ${{\mathcal{R}}}_r(n, k)$ denote the proportion of permutations
${{\mathcal{R}}}_r(n, k)$ denote the proportion of permutations 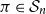 $\pi \in {{\mathcal{S}}}_n$ that fix a set of size
$\pi \in {{\mathcal{S}}}_n$ that fix a set of size  $k$ and have no cycle of length less than
$k$ and have no cycle of length less than  $r$. In this note, we determine the order of magnitude of
$r$. In this note, we determine the order of magnitude of  ${{\mathcal{R}}}_r(n, k)$ uniformly for all
${{\mathcal{R}}}_r(n, k)$ uniformly for all  $2\leqslant r\leqslant k\leqslant n/2$. This result generalises the corresponding estimate of Eberhard, Ford, and Green for the case
$2\leqslant r\leqslant k\leqslant n/2$. This result generalises the corresponding estimate of Eberhard, Ford, and Green for the case 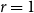 $r=1$.
$r=1$.

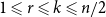
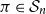




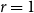
Non-hospital occupational blood exposure accidents: A nine-year retrospective analysis of post-exposure HIV, hepatitis B and C risk management in the Netherlands
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 27 March 2026, e58
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Inequalities in complete pneumococcal vaccination among Peruvian children before and after the COVID-19 pandemic: An evaluation using demographic and health surveys from 2018 to 2023
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 27 March 2026, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The random
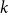 $\textit{k}$-SAT Gibbs uniqueness threshold revisited
$\textit{k}$-SAT Gibbs uniqueness threshold revisited
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that for any
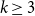 $k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random
$k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random 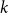 $k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any
$k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any 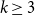 $k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small
$k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small 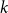 $k$.
$k$.
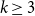
Defect and transference versions of the Alon–Frankl–Lovász theorem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Confirming a conjecture of Erdős on the chromatic number of Kneser hypergraphs, Alon, Frankl and Lovász proved that in any
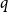 $q$-colouring of the edges of the complete
$q$-colouring of the edges of the complete  $r$-uniform hypergraph, there exists a monochromatic matching of size
$r$-uniform hypergraph, there exists a monochromatic matching of size 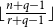 $\lfloor \frac {n+q-1}{r+q-1}\rfloor$. In this paper, we prove a transference version of this theorem. More precisely, for fixed
$\lfloor \frac {n+q-1}{r+q-1}\rfloor$. In this paper, we prove a transference version of this theorem. More precisely, for fixed 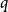 $q$ and
$q$ and  $r$, we show that with high probability, a monochromatic matching of approximately the same size exists in any
$r$, we show that with high probability, a monochromatic matching of approximately the same size exists in any 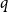 $q$-colouring of a random hypergraph, already when the average degree is a sufficiently large constant. In fact, our main new result is a defect version of the Alon–Frankl–Lovász theorem for almost complete hypergraphs. From this, the transference version is obtained via a variant of the weak hypergraph regularity lemma. The proof of the defect version uses tools from extremal set theory developed in the study of the Erdős matching conjecture.
$q$-colouring of a random hypergraph, already when the average degree is a sufficiently large constant. In fact, our main new result is a defect version of the Alon–Frankl–Lovász theorem for almost complete hypergraphs. From this, the transference version is obtained via a variant of the weak hypergraph regularity lemma. The proof of the defect version uses tools from extremal set theory developed in the study of the Erdős matching conjecture.
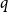

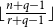
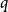

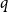
Counting chemical isomers with multivariate generating functions
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 26 March 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An illustrated tutorial on mixed-method social network analysis of embedded network agency
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 26 March 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Efficient simulation of fractional Brownian motion
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 26 March 2026, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Fractional Brownian motion, with its long-time correlated increments, has been applied in many fields in recent years. Since volatility was shown to be rough by Gatheral, Jaisson, and Rosenbaum, fractional Brownian motion has gained popularity as a financial model. In this work, we revisit the definitions and properties of the univariate and multivariate fractional Brownian motions, and consider four simulation methods. We demonstrate the issues associated with applying the standard Euler scheme for simulating stochastic processes driven by fractional Brownian motion with
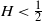 $H < \frac{1}{2}$ (which we call the rough models). We then introduce a novel approximate method for simulating such rough models based on the fast algorithm by Ma and Wu, which accounts for a factor of 10 speedup. Finally, we consider applications of these methods to option pricing.
$H < \frac{1}{2}$ (which we call the rough models). We then introduce a novel approximate method for simulating such rough models based on the fast algorithm by Ma and Wu, which accounts for a factor of 10 speedup. Finally, we consider applications of these methods to option pricing.
Large deviations for Cox–ingersoll–ross processes with state-dependent fast switching
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 26 March 2026, pp. 1-34
-
- Article
- Export citation
-
We study large deviations for Cox–Ingersoll–Ross processes with small noise and state-dependent fast switching via associated Hamilton–Jacobi–Bellman equations. As time scales separate, when the noise goes to 0 and the rate of switching goes to
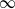 $\infty$, we get a limit equation characterized by the averaging principle. Moreover, we prove the large deviation principle with an action-integral form rate function to describe the asymptotic behavior of such systems. The new ingredient is establishing the comparison principle in the singular context. The proof is carried out using the nonlinear semigroup method from Feng and Kurtz’s book [14].
$\infty$, we get a limit equation characterized by the averaging principle. Moreover, we prove the large deviation principle with an action-integral form rate function to describe the asymptotic behavior of such systems. The new ingredient is establishing the comparison principle in the singular context. The proof is carried out using the nonlinear semigroup method from Feng and Kurtz’s book [14].
Mortality Forecasting in Geographical Space and Time
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 25 March 2026, pp. 367-388
- Print publication:
- May 2026
-
- Article
- Export citation
Two decades of ESKAPE pathogens: Longitudinal analysis of antibiotic resistance trends between 2002 and 2024 in a Hungarian clinical centre
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 25 March 2026, e47
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotically optimal policies for weakly coupled Markov decision processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 25 March 2026, pp. 1-31
-
- Article
- Export citation
-
We consider the problem of maximizing the expected average reward obtained over an infinite time horizon by n weakly coupled Markov decision processes. Our setup is a substantial generalization of the multi-armed restless bandit problem that allows for multiple actions and constraints. We establish a connection with a deterministic and continuous-variable control problem where the objective is to maximize the average reward derived from an occupancy measure that represents the empirical distribution of the processes when
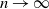 $n \to \infty$. We show that a solution of this fluid problem can be used to construct policies for the weakly coupled processes that achieve the maximum expected average reward as
$n \to \infty$. We show that a solution of this fluid problem can be used to construct policies for the weakly coupled processes that achieve the maximum expected average reward as 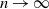 $n \to \infty$, and we give sufficient conditions for the existence of solutions. Under certain assumptions on the constraints, we prove that these conditions are automatically satisfied if the unconstrained single-process problem admits a suitable unichain and aperiodic policy. In particular, the assumptions include multi-armed restless bandits and a broad class of problems with multiple actions and inequality constraints. Also, the policies can be constructed in an explicit way in these cases. Our theoretical results are complemented by several concrete examples and numerical experiments, which include multichain setups that are covered by the theoretical results.
$n \to \infty$, and we give sufficient conditions for the existence of solutions. Under certain assumptions on the constraints, we prove that these conditions are automatically satisfied if the unconstrained single-process problem admits a suitable unichain and aperiodic policy. In particular, the assumptions include multi-armed restless bandits and a broad class of problems with multiple actions and inequality constraints. Also, the policies can be constructed in an explicit way in these cases. Our theoretical results are complemented by several concrete examples and numerical experiments, which include multichain setups that are covered by the theoretical results.
On technological and analytical innovations in insurance research and industry practice
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 2 / July 2026
- Published online by Cambridge University Press:
- 25 March 2026, pp. 414-438
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Intergenerational cross-subsidies in UK collective defined contribution funds
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 2 / July 2026
- Published online by Cambridge University Press:
- 25 March 2026, pp. 381-413
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
