Refine search
Actions for selected content:
53113 results in Statistics and Probability
Upper bounds for critical probabilities in Bernoulli percolation models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 23 January 2026, pp. 61-72
- Print publication:
- March 2026
-
- Article
- Export citation
-
We study bond and site Bernoulli percolation models on
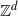 $\mathbb{Z}^d$ for
$\mathbb{Z}^d$ for 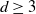 $d \geq 3$ with parameter p, in both the oriented and non-oriented versions. The main macroscopic quantity of interest is the probability of long-range order, and the existence of a non-trivial threshold is well established. Precise numerical results for the threshold values are available in the literature, but mathematically rigorous bounds are mostly restricted to two-dimensional lattices. Utilizing dynamical coupling techniques, we introduce a comprehensive set of new rigorous upper bounds that corroborate existing numerical values.
$d \geq 3$ with parameter p, in both the oriented and non-oriented versions. The main macroscopic quantity of interest is the probability of long-range order, and the existence of a non-trivial threshold is well established. Precise numerical results for the threshold values are available in the literature, but mathematically rigorous bounds are mostly restricted to two-dimensional lattices. Utilizing dynamical coupling techniques, we introduce a comprehensive set of new rigorous upper bounds that corroborate existing numerical values.
A zero-inflated Poisson latent position cluster model
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 23 January 2026, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic dominance results under multivariate chain majorization for extreme order statistics of a generalized Gompertz distribution
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 3 / July 2026
- Published online by Cambridge University Press:
- 23 January 2026, pp. 330-354
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparing community-based interventions versus population-wide response in information diffusion on social media platforms
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 22 January 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Taking stock of urban data governance in German small towns
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 22 January 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Automated surface damage detection with an embodied intelligence robotic platform
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 22 January 2026, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk factors associated with acquiring gastrointestinal infections in UK international travellers: a case–control study
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 22 January 2026, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Clique density vs blowups
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 22 January 2026, pp. 294-315
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A well-known theorem of Nikiforov asserts that any graph with a positive
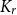 $K_{r}$-density contains a logarithmic blowup of
$K_{r}$-density contains a logarithmic blowup of 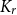 $K_r$. In this paper, we explore variants of Nikiforov’s result in the following form. Given
$K_r$. In this paper, we explore variants of Nikiforov’s result in the following form. Given 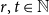 $r,t\in \mathbb{N}$, when a positive
$r,t\in \mathbb{N}$, when a positive 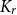 $K_{r}$-density implies the existence of a significantly larger (with almost linear size) blowup of
$K_{r}$-density implies the existence of a significantly larger (with almost linear size) blowup of 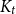 $K_t$? Our results include:
$K_t$? Our results include:• For an
 $n$-vertex ordered graph
$n$-vertex ordered graph 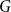 $G$ with no induced monotone path
$G$ with no induced monotone path 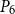 $P_{6}$, if its complement
$P_{6}$, if its complement 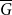 $\overline {G}$ has positive triangle density, then
$\overline {G}$ has positive triangle density, then 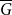 $\overline {G}$ contains a biclique of size
$\overline {G}$ contains a biclique of size 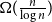 $\Omega ({n \over {\log n}})$. This strengthens a recent result of Pach and Tomon. For general
$\Omega ({n \over {\log n}})$. This strengthens a recent result of Pach and Tomon. For general 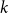 $k$, let
$k$, let 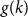 $g(k)$ be the minimum
$g(k)$ be the minimum 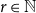 $r\in \mathbb{N}$ such that for any
$r\in \mathbb{N}$ such that for any  $n$-vertex ordered graph
$n$-vertex ordered graph 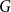 $G$ with no induced monotone
$G$ with no induced monotone 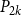 $P_{2k}$, if
$P_{2k}$, if 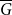 $\overline {G}$ has positive
$\overline {G}$ has positive 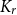 $K_r$-density, then
$K_r$-density, then 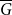 $\overline {G}$ contains a biclique of size
$\overline {G}$ contains a biclique of size 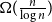 $\Omega ({n \over {\log n}})$. Using concentration of measure and the isodiametric inequality on high dimensional spheres, we provide constructions showing that, surprisingly,
$\Omega ({n \over {\log n}})$. Using concentration of measure and the isodiametric inequality on high dimensional spheres, we provide constructions showing that, surprisingly, 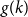 $g(k)$ grows quadratically. On the other hand, we relate the problem of upper bounding
$g(k)$ grows quadratically. On the other hand, we relate the problem of upper bounding 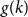 $g(k)$ to a certain Ramsey problem and determine
$g(k)$ to a certain Ramsey problem and determine 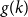 $g(k)$ up to a factor of 2.
$g(k)$ up to a factor of 2.• Any incomparability graph with positive
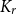 $K_{r}$-density contains a blowup of
$K_{r}$-density contains a blowup of 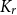 $K_r$ of size
$K_r$ of size 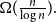 $\Omega ({n \over {\log n}}).$ This confirms a conjecture of Tomon in a stronger form. In doing so, we obtain a strong regularity type lemma for incomparability graphs with no large blowups of a clique, which is of independent interest. We also prove that any
$\Omega ({n \over {\log n}}).$ This confirms a conjecture of Tomon in a stronger form. In doing so, we obtain a strong regularity type lemma for incomparability graphs with no large blowups of a clique, which is of independent interest. We also prove that any  $r$-comparability graph with positive
$r$-comparability graph with positive 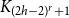 $K_{(2h-2)^{r}+1}$-density contains a blowup of
$K_{(2h-2)^{r}+1}$-density contains a blowup of 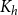 $K_h$ of size
$K_h$ of size 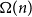 $\Omega (n)$, where the constant
$\Omega (n)$, where the constant 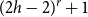 $(2h-2)^{r}+1$ is optimal.
$(2h-2)^{r}+1$ is optimal.
The
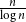 ${n \over {\log n}}$ size of the blowups in all our results are optimal up to a constant factor.
${n \over {\log n}}$ size of the blowups in all our results are optimal up to a constant factor.
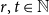
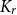
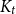

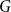
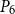
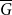
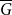
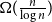
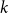
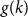
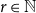

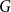
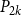
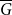
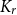
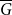
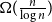
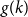
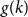
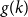
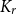
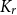
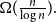

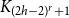
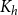
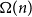
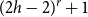
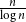
Quantitative convergence rates for stochastically monotone Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 21 January 2026, pp. 798-810
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Moving beyond constrained settings: Health and network dynamics among middle-aged and older adults in voluntary clubs
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 21 January 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sub-value and sup-value of a linear diffusion game
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 21 January 2026, pp. 1-48
-
- Article
- Export citation
Mapping the bird risk index for West Nile virus in Europe and its relationship with disease occurrence in humans
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 19 January 2026, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparing the Efficiency of General State Space Reversible MCMC Algorithms
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 15 January 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove new results about comparing the efficiency of general state space Markov chain Monte Carlo algorithms that randomly select a possibly different reversible method at each step (previously known only for finite state spaces). We also provide new, simpler, more accessible proofs of key results, and analyse numerous examples. We provide a full proof of the formula for the asymptotic variance for real-valued functionals on
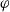 $\varphi$-irreducible reversible Markov chains, first introduced by Kipnis and Varadhan (1986, Commun. Math. Phys. 104, 1–19). Given two Markov kernels P and Q with stationary measure
$\varphi$-irreducible reversible Markov chains, first introduced by Kipnis and Varadhan (1986, Commun. Math. Phys. 104, 1–19). Given two Markov kernels P and Q with stationary measure 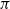 $\pi$, we say that the Markov kernel P efficiency-dominates the Markov kernel Q if the asymptotic variance with respect to P is at most the asymptotic variance with respect to Q for every real-valued functional
$\pi$, we say that the Markov kernel P efficiency-dominates the Markov kernel Q if the asymptotic variance with respect to P is at most the asymptotic variance with respect to Q for every real-valued functional 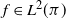 $f\in L^2(\pi)$. Assuming only a basic background in functional analysis, we prove that for two reversible Markov kernels P and Q, P efficiency-dominates Q if and only if the operator
$f\in L^2(\pi)$. Assuming only a basic background in functional analysis, we prove that for two reversible Markov kernels P and Q, P efficiency-dominates Q if and only if the operator 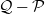 $\mathcal{Q}-\mathcal{P}$, where
$\mathcal{Q}-\mathcal{P}$, where 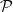 $\mathcal{P}$ is the operator on
$\mathcal{P}$ is the operator on 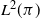 $L^2(\pi)$ that maps
$L^2(\pi)$ that maps 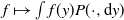 $f\mapsto\int f(y)P(\cdot,\mathrm{d}y)$ and similarly for
$f\mapsto\int f(y)P(\cdot,\mathrm{d}y)$ and similarly for 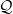 $\mathcal{Q}$, is positive on
$\mathcal{Q}$, is positive on 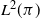 $L^2(\pi)$, i.e.
$L^2(\pi)$, i.e.  $\langle f,\left(\mathcal{Q}-\mathcal{P}\right)f\rangle\geq0$ for every
$\langle f,\left(\mathcal{Q}-\mathcal{P}\right)f\rangle\geq0$ for every 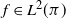 $f\in L^2(\pi)$ (previous proofs for general state spaces use technical results from monotone operator function theory). We use this result to show that under mild conditions, sandwich variants of data augmentation algorithms efficiency-dominate the original algorithm. We also provide other easy-to-check sufficient conditions for efficiency dominance, some of which are generalized from the finite state space case. We also provide a proof based on that of Tierney (1998, Ann. Appl. Prob. 8, 1–9) that Peskun dominance is a sufficient condition for efficiency dominance for reversible kernels. Using these results, we show that Markov kernels formed by random selection of other ‘component’ Markov kernels will always efficiency-dominate another Markov kernel formed in this way, as long as the component kernels of the former efficiency-dominate those of the latter. These results on the efficiency dominance of combining component kernels generalizes the results on the efficiency dominance of combined chains introduced by Neal and Rosenthal (2024, J. Appl. Prob. 62, 188–208) from finite state spaces to general state spaces.
$f\in L^2(\pi)$ (previous proofs for general state spaces use technical results from monotone operator function theory). We use this result to show that under mild conditions, sandwich variants of data augmentation algorithms efficiency-dominate the original algorithm. We also provide other easy-to-check sufficient conditions for efficiency dominance, some of which are generalized from the finite state space case. We also provide a proof based on that of Tierney (1998, Ann. Appl. Prob. 8, 1–9) that Peskun dominance is a sufficient condition for efficiency dominance for reversible kernels. Using these results, we show that Markov kernels formed by random selection of other ‘component’ Markov kernels will always efficiency-dominate another Markov kernel formed in this way, as long as the component kernels of the former efficiency-dominate those of the latter. These results on the efficiency dominance of combining component kernels generalizes the results on the efficiency dominance of combined chains introduced by Neal and Rosenthal (2024, J. Appl. Prob. 62, 188–208) from finite state spaces to general state spaces.
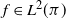
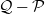
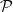
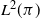
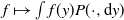
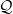
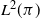

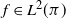
CAN PRINCIPAL COMPONENT ANALYSIS PRESERVE THE SPARSITY IN FACTOR LOADINGS?
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 14 January 2026, pp. 1-24
-
- Article
- Export citation

Play of Chance and Purpose
- An Invitation to Probability, Statistics, and Stochasticity Using Simulations and Projects
-
- Published online:
- 13 January 2026
- Print publication:
- 31 July 2026
-
- Textbook
- Export citation
Quantifying stochastic dependence of marginal lifetimes of two-component load-sharing parallel systems
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 3 / July 2026
- Published online by Cambridge University Press:
- 13 January 2026, pp. 315-329
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the joint right-tail distribution of the forward and backward recurrence times in a delayed renewal process
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 12 January 2026, pp. 288-314
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
HOW TO DETECT NETWORK DEPENDENCE IN LATENT FACTOR MODELS? A BIAS-CORRECTED CD TEST
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 12 January 2026, pp. 1-41
-
- Article
- Export citation
-
In a recent paper, Juodis and Reese (2022, Journal of Business & Economic Statistics, 40, 1191–1203) (JR) show that the application of the CD test proposed by Pesaran (2004, General diagnostic tests for cross-sectional dependence in panels, CWPE 0435, Cambridge) to residuals from panels with latent factors results in over-rejection. They propose a randomized test statistic to correct for over-rejection, and add a screening component to achieve power. This article considers the same problem but from a different perspective and shows that the standard CD test remains valid if the latent factors are weak. A bias-corrected version, CD
 $^{\ast}$, is proposed which is shown to be asymptotically standard normal under the null of error cross-sectional independence which has power against network-type alternatives. This result is shown to hold for pure latent factor models as well as for panel regression models with latent factors. The case where the errors are serially correlated is also considered. Small sample properties of the CD
$^{\ast}$, is proposed which is shown to be asymptotically standard normal under the null of error cross-sectional independence which has power against network-type alternatives. This result is shown to hold for pure latent factor models as well as for panel regression models with latent factors. The case where the errors are serially correlated is also considered. Small sample properties of the CD $^{\ast}$ test are investigated by Monte Carlo experiments and are shown to have satisfactory small sample properties. In an empirical application, using the CD
$^{\ast}$ test are investigated by Monte Carlo experiments and are shown to have satisfactory small sample properties. In an empirical application, using the CD $^{\ast}$ test, it is shown that there remains spatial error dependence in a panel data model for real house price changes across 377 Metropolitan Statistical Areas in the United States, even after the effects of latent factors are filtered out.
$^{\ast}$ test, it is shown that there remains spatial error dependence in a panel data model for real house price changes across 377 Metropolitan Statistical Areas in the United States, even after the effects of latent factors are filtered out.



Estimating influenza A subtype ratios among critical care admissions in England
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 12 January 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multitype branching processes with immigration generated by point processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 12 January 2026, pp. 828-848
- Print publication:
- June 2026
-
- Article
- Export citation
