Refine search
Actions for selected content:
53113 results in Statistics and Probability
EDITORIAL: A NEW CHAPTER FOR ECONOMETRIC THEORY
-
- Journal:
- Econometric Theory / Volume 42 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 29 December 2025, pp. 2-4
-
- Article
-
- You have access
- HTML
- Export citation
Quasi-stationary distributions in reducible state spaces
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 26 December 2025, pp. 1-37
-
- Article
- Export citation
Knowledge, attitudes, and readiness towards artificial intelligence in government services: a developing country perspective
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 26 December 2025, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Protection from second booster vaccines and natural immunity against SARS-CoV-2 infections, 2022–2023
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 26 December 2025, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk and prognosis of colorectal cancer following bacteraemia with Streptococcus bovis–Streptococcus equinus complex: A Swedish nationwide retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 26 December 2025, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Eat-Out-to-Help-Out incentive: A trigger for gastrointestinal infections in England, 2020?
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 26 December 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Narratives on quantum technologies: a cross-domain analysis of media, business, and policy discourses
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 23 December 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Increased transmission and incidence of syphilis in southern Sweden 2007–2022
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 23 December 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evaluating a quality improvement intervention for schistosomiasis mass drug administration in Ghana using the RE-AIM framework
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 23 December 2025, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Corrections of formulas in ‘An elementary derivation of moments of Hawkes processes’
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 22 December 2025, pp. 876-884
- Print publication:
- June 2026
-
- Article
- Export citation
Epidemiological impacts and cost-effectiveness of daily and on-demand oral pre-exposure prophylaxis among key HIV populations in China: An economic evaluation
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 19 December 2025, e139
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Space-grid approximations of hybrid stochastic differential equations and first-passage properties
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 19 December 2025, pp. 623-647
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ASB volume 56 issue 1 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 19 December 2025, pp. f1-f2
- Print publication:
- January 2026
-
- Article
-
- You have access
- Export citation
ASB volume 56 issue 1 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 19 December 2025, pp. b1-b3
- Print publication:
- January 2026
-
- Article
-
- You have access
- Export citation
Scaling limits of SIR epidemics with vertex-dependent transition rates on complete graphs
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 18 December 2025, pp. 1-45
-
- Article
- Export citation
-
In this paper we are concerned with susceptible–infected–removed (SIR) epidemics with vertex-dependent recovery and infection rates on complete graphs. We show that the hydrodynamic limit of our model is driven by a nonlinear function-valued ordinary differential equation consistent with a mean-field analysis. We further show that the fluctuation of our process is driven by a generalized Ornstein–Uhlenbeck process. A key step in the proofs of the main results is to show that states of different vertices are approximately independent as the population
 $N\rightarrow+\infty$.
$N\rightarrow+\infty$.

Making global sensitivity analysis feasible using neural network surrogates – ERRATUM
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 18 December 2025, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Connectivity of a family of bilateral preference random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 18 December 2025, pp. 552-579
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the bilateral preference graphs
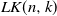 $\mathit{LK}(n, k)$ of La and Kabkab, obtained as follows. Put independent and uniform [0, 1] weights on the edges of the complete graph
$\mathit{LK}(n, k)$ of La and Kabkab, obtained as follows. Put independent and uniform [0, 1] weights on the edges of the complete graph 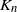 $K_n$. Then, each edge (i, j) is included in
$K_n$. Then, each edge (i, j) is included in 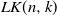 $\mathit{LK}(n,k)$ if it is bilaterally preferred, in the sense that it is among the k edges of lowest weight incident to vertex i, and among the k edges of lowest weight incident to vertex j. We show that
$\mathit{LK}(n,k)$ if it is bilaterally preferred, in the sense that it is among the k edges of lowest weight incident to vertex i, and among the k edges of lowest weight incident to vertex j. We show that 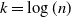 $k = \log(n)$ is the connectivity threshold, solving a conjecture of La and Kabkab, and obtaining finer results about the window. We also investigate the asymptotic behavior of the average degree of vertices in
$k = \log(n)$ is the connectivity threshold, solving a conjecture of La and Kabkab, and obtaining finer results about the window. We also investigate the asymptotic behavior of the average degree of vertices in 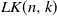 $\mathit{LK}(n, k)$ as
$\mathit{LK}(n, k)$ as 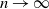 $n\rightarrow\infty$.
$n\rightarrow\infty$.
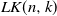
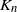
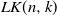
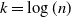
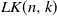
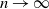
Hypergraphs with uniform Turán density equal to 8/27
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 17 December 2025, pp. 280-289
-
- Article
- Export citation
-
In the 1980s, Erdős and Sós initiated the study of Turán problems with a uniformity condition on the distribution of edges: the uniform Turán density of a hypergraph
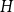 $H$ is the infimum over all
$H$ is the infimum over all 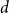 $d$ for which any sufficiently large hypergraph with the property that all its linear-size subhypergraphs have density at least
$d$ for which any sufficiently large hypergraph with the property that all its linear-size subhypergraphs have density at least 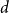 $d$ contains
$d$ contains 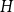 $H$. In particular, they asked to determine the uniform Turán densities of
$H$. In particular, they asked to determine the uniform Turán densities of 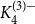 $K_4^{(3)-}$ and
$K_4^{(3)-}$ and 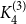 $K_4^{(3)}$. After more than 30 years, the former was solved in [Israel J. Math. 211 (2016), 349 – 366] and [J. Eur. Math. Soc. 20 (2018), 1139 – 1159], while the latter still remains open. Till today, there are known constructions of
$K_4^{(3)}$. After more than 30 years, the former was solved in [Israel J. Math. 211 (2016), 349 – 366] and [J. Eur. Math. Soc. 20 (2018), 1139 – 1159], while the latter still remains open. Till today, there are known constructions of 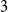 $3$-uniform hypergraphs with uniform Turán density equal to
$3$-uniform hypergraphs with uniform Turán density equal to 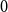 $0$,
$0$, 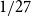 $1/27$,
$1/27$, 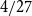 $4/27$, and
$4/27$, and 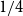 $1/4$ only. We extend this list by a fifth value: we prove an easy to verify sufficient condition for the uniform Turán density to be equal to
$1/4$ only. We extend this list by a fifth value: we prove an easy to verify sufficient condition for the uniform Turán density to be equal to 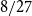 $8/27$ and identify hypergraphs satisfying this condition.
$8/27$ and identify hypergraphs satisfying this condition.
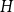
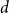
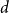
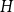
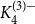
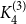
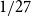
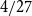
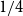
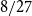
The impact of institutions on blockchain adoption in the European public sector: a qualitative comparative analysis
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 December 2025, e84
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Finite mixture models for option pricing: An application to Bitcoin options
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 16 December 2025, pp. 707-728
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
