Refine search
Actions for selected content:
53140 results in Statistics and Probability
Robustness with adaptation. Ownership networks of multinationals through COVID-19
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 11 December 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
HIF: The hypergraph interchange format for higher-order networks
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 11 December 2025, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research that I have not yet done, but that I consider worth doing
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 3 / November 2025
- Published online by Cambridge University Press:
- 11 December 2025, pp. 401-415
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Special issue to celebrate the 90th birthday of Professor David Wilkie
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 3 / November 2025
- Published online by Cambridge University Press:
- 11 December 2025, pp. 395-400
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hypergraphs without complete partite subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 11 December 2025, pp. 290-293
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Fix integers
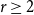 $r \ge 2$ and
$r \ge 2$ and 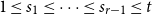 $1\le s_1\le \cdots \le s_{r-1}\le t$ and set
$1\le s_1\le \cdots \le s_{r-1}\le t$ and set 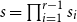 $s=\prod _{i=1}^{r-1}s_i$. Let
$s=\prod _{i=1}^{r-1}s_i$. Let 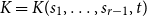 $K=K(s_1, \ldots , s_{r-1}, t)$ denote the complete
$K=K(s_1, \ldots , s_{r-1}, t)$ denote the complete  $r$-partite
$r$-partite  $r$-uniform hypergraph with parts of size
$r$-uniform hypergraph with parts of size 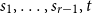 $s_1, \ldots , s_{r-1}, t$. We prove that the Zarankiewicz number
$s_1, \ldots , s_{r-1}, t$. We prove that the Zarankiewicz number 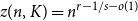 $z(n, K)= n^{r-1/s-o(1)}$ provided
$z(n, K)= n^{r-1/s-o(1)}$ provided 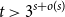 $t\gt 3^{s+o(s)}$. Previously this was known only for
$t\gt 3^{s+o(s)}$. Previously this was known only for 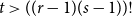 $t \gt ((r-1)(s-1))!$ due to Pohoata and Zakharov. Our novel approach, which uses Behrend’s construction of sets with no 3-term arithmetic progression, also applies for small values of
$t \gt ((r-1)(s-1))!$ due to Pohoata and Zakharov. Our novel approach, which uses Behrend’s construction of sets with no 3-term arithmetic progression, also applies for small values of 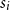 $s_i$, for example, it gives
$s_i$, for example, it gives 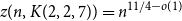 $z(n, K(2,2,7))=n^{11/4-o(1)}$ where the exponent 11/4 is optimal, whereas previously this was only known with 7 replaced by 721.
$z(n, K(2,2,7))=n^{11/4-o(1)}$ where the exponent 11/4 is optimal, whereas previously this was only known with 7 replaced by 721.
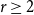
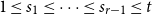
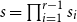
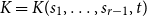


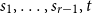
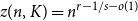
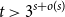
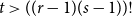
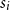
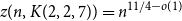
Asymptotic analysis for stationary distributions of multiscaled reaction networks
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 11 December 2025, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study stationary distributions in the context of stochastic reaction networks. In particular, we are interested in complex balanced reaction networks and the reduction of such networks by assuming that a set of species (called non-interacting species) are degraded fast (and therefore essentially absent from the network), implying that some reaction rates are large relative to others. Technically, we assume that these reaction rates are scaled by a common parameter N and let
 $N\to\infty$. The limiting stationary distribution as
$N\to\infty$. The limiting stationary distribution as  $N\to\infty$ is compared with the stationary distribution of the reduced reaction network obtained by elimination of the non-interacting species. In general, the limiting stationary distribution could differ from the stationary distribution of the reduced reaction network. We identify various sufficient conditions under which these two distributions are the same, including when the reaction network is detailed balanced and when the set of non-interacting species consists of intermediate species. In the latter case, the limiting stationary distribution essentially retains the form of the complex balanced distribution. This finding is particularly surprising given that the reduced reaction network could be non-weakly reversible and might exhibit unconventional kinetics.
$N\to\infty$ is compared with the stationary distribution of the reduced reaction network obtained by elimination of the non-interacting species. In general, the limiting stationary distribution could differ from the stationary distribution of the reduced reaction network. We identify various sufficient conditions under which these two distributions are the same, including when the reaction network is detailed balanced and when the set of non-interacting species consists of intermediate species. In the latter case, the limiting stationary distribution essentially retains the form of the complex balanced distribution. This finding is particularly surprising given that the reduced reaction network could be non-weakly reversible and might exhibit unconventional kinetics.


Limiting distributions of generalized money exchange models on hypergraphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 11 December 2025, pp. 850-875
- Print publication:
- June 2026
-
- Article
- Export citation
Asymptotics for a multidimensional risk model with a random number of delayed claims and multivariate regularly varying distribution
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 10 December 2025, pp. 782-811
- Print publication:
- June 2026
-
- Article
- Export citation
Enriched truncated exponentiated generalized family of distributions with application to heavy-tailed data
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 2 / May 2026
- Published online by Cambridge University Press:
- 10 December 2025, pp. 588-610
- Print publication:
- May 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sidorenko’s conjecture for subdivisions and theta substitutions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 10 December 2025, pp. 269-279
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The famous Sidorenko’s conjecture asserts that for every bipartite graph
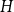 $H$, the number of homomorphisms from
$H$, the number of homomorphisms from 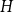 $H$ to a graph
$H$ to a graph 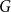 $G$ with given edge density is minimised when
$G$ with given edge density is minimised when 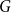 $G$ is pseudorandom. We prove that for any graph
$G$ is pseudorandom. We prove that for any graph 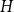 $H$, a graph obtained from replacing edges of
$H$, a graph obtained from replacing edges of 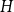 $H$ by generalised theta graphs consisting of even paths satisfies Sidorenko’s conjecture, provided a certain divisibility condition on the number of paths. To achieve this, we prove unconditionally that bipartite graphs obtained from replacing each edge of a complete graph with a generalised theta graph satisfy Sidorenko’s conjecture, which extends a result of Conlon, Kim, Lee and Lee [J. Lond. Math. Soc., 2018].
$H$ by generalised theta graphs consisting of even paths satisfies Sidorenko’s conjecture, provided a certain divisibility condition on the number of paths. To achieve this, we prove unconditionally that bipartite graphs obtained from replacing each edge of a complete graph with a generalised theta graph satisfy Sidorenko’s conjecture, which extends a result of Conlon, Kim, Lee and Lee [J. Lond. Math. Soc., 2018].
COVID-19 outbreaks in care homes: How does size influence transmission dynamics? A cross-sectional study with implications for outbreak management in small care homes
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 10 December 2025, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Uniform asymptotics for a time-dependent bidimensional delay-claim risk model with stochastic return and dependent subexponential claims
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 10 December 2025, pp. 745-781
- Print publication:
- June 2026
-
- Article
- Export citation
Non-asymptotic analysis of Langevin-type Monte Carlo algorithms
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 10 December 2025, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Monitoring effectiveness of nirsevimab immunization against RSV hospitalization using surveillance data: a test-negative case–control study, Spain, October 2024–March 2025
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 09 December 2025, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Central limit theorems for additive functionals of patricia tries
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 09 December 2025, pp. 334-347
- Print publication:
- March 2026
-
- Article
- Export citation
-
General additive functionals of patricia tries are studied asymptotically in a probabilistic model with independent, identically distributed letters from a finite alphabet. Asymptotic normality is shown after normalization together with asymptotic expansions of the moments. There are two regimes depending on the algebraic structure of the letter probabilities, with and without oscillations in the expansion of moments. As applications firstly the proportion of fringe trees of patricia tries with k keys is studied, which is oscillating around
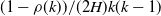 $(1-\rho(k))/(2H)k(k-1)$, where H denotes the source entropy and
$(1-\rho(k))/(2H)k(k-1)$, where H denotes the source entropy and 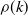 $\rho(k)$ is exponentially decreasing. The oscillations are identified explicitly. Secondly, the independence number of patricia tries and of tries is considered. The general results for additive functions also apply, where a leading constant is numerically approximated. The results extend work of Janson on tries by relating additive functionals on patricia tries to additive functionals on tries.
$\rho(k)$ is exponentially decreasing. The oscillations are identified explicitly. Secondly, the independence number of patricia tries and of tries is considered. The general results for additive functions also apply, where a leading constant is numerically approximated. The results extend work of Janson on tries by relating additive functionals on patricia tries to additive functionals on tries.
On stability of rainbow matchings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 09 December 2025, pp. 255-268
-
- Article
-
- You have access
- HTML
- Export citation
-
We show that for any integer
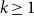 $k\ge 1$ there exists an integer
$k\ge 1$ there exists an integer 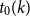 $t_0(k)$ such that, for integers
$t_0(k)$ such that, for integers 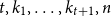 $t, k_1, \ldots , k_{t+1}, n$ with
$t, k_1, \ldots , k_{t+1}, n$ with 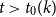 $t\gt t_0(k)$,
$t\gt t_0(k)$, 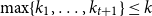 $\max \{k_1, \ldots , k_{t+1}\}\le k$, and
$\max \{k_1, \ldots , k_{t+1}\}\le k$, and 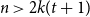 $n \gt 2k(t+1)$, the following holds: If
$n \gt 2k(t+1)$, the following holds: If 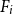 $F_i$ is a
$F_i$ is a 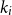 $k_i$-uniform hypergraph with vertex set
$k_i$-uniform hypergraph with vertex set 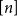 $[n]$ and more than
$[n]$ and more than 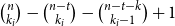 $ \binom{n}{k_i}-\binom{n-t}{k_i} - \binom{n-t-k}{k_i-1} + 1$ edges for all
$ \binom{n}{k_i}-\binom{n-t}{k_i} - \binom{n-t-k}{k_i-1} + 1$ edges for all 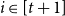 $i \in [t+1]$, then either
$i \in [t+1]$, then either 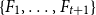 $\{F_1,\ldots , F_{t+1}\}$ admits a rainbow matching of size
$\{F_1,\ldots , F_{t+1}\}$ admits a rainbow matching of size 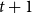 $t+1$ or there exists
$t+1$ or there exists 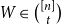 $W\in \binom{[n]}{t}$ such that
$W\in \binom{[n]}{t}$ such that 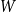 $W$ intersects
$W$ intersects 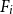 $F_i$ for all
$F_i$ for all 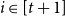 $i\in [t+1]$. This may be viewed as a rainbow non-uniform extension of the classical Hilton-Milner theorem. We also show that the same holds for every
$i\in [t+1]$. This may be viewed as a rainbow non-uniform extension of the classical Hilton-Milner theorem. We also show that the same holds for every  $t$ and
$t$ and 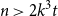 $n \gt 2k^3t$, generalizing a recent stability result of Frankl and Kupavskii on matchings to rainbow matchings.
$n \gt 2k^3t$, generalizing a recent stability result of Frankl and Kupavskii on matchings to rainbow matchings.
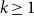
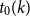
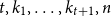
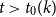
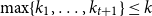
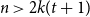
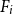
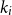
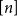
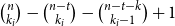
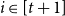
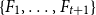
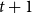
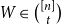
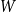
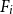
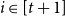

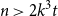
Large deviations for dynamical Schrödinger problems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 09 December 2025, pp. 668-689
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trends in asthma exacerbations in children before, during, and after the COVID-19 pandemic
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 05 December 2025, e138
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Inequality – actuarial perspectives
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 05 December 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - Gaussian Free Field with Neumann Boundary Conditions
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 220-255
-
- Chapter
- Export citation
