Refine search
Actions for selected content:
53140 results in Statistics and Probability
Pre-averaging fractional processes contaminated by noise, with an application to turbulence
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 21 November 2025, pp. 1280-1300
- Print publication:
- December 2025
-
- Article
- Export citation
-
We consider the problem of estimating fractional processes based on noisy high-frequency data. Generalizing the idea of pre-averaging to a fractional setting, we exhibit a sequence of consistent estimators for the unknown parameters of interest by proving a law of large numbers for associated variation functionals. In contrast to the semimartingale setting, the optimal window size for pre-averaging depends on the unknown roughness parameter of the underlying process. We evaluate the performance of our estimators in a simulation study and use them to empirically verify Kolmogorov’s
 $2/3$-law in turbulence data contaminated by instrument noise.
$2/3$-law in turbulence data contaminated by instrument noise.

The distribution of the minimum observation until a stopping time, with an application to the minimal spacing in a Renewal process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 21 November 2025, pp. 157-176
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
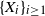 $\{X_{i}\}_{i\geq1}$ be a sequence of independent and identically distributed random variables and
$\{X_{i}\}_{i\geq1}$ be a sequence of independent and identically distributed random variables and 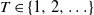 $T\in\{1,2,\ldots\}$ a stopping time associated with this sequence. In this paper, the distribution of the minimum observation,
$T\in\{1,2,\ldots\}$ a stopping time associated with this sequence. In this paper, the distribution of the minimum observation, 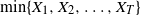 $\min\{X_{1},X_{2},\ldots,X_{T}\}$, until the stopping time T is provided by proposing a methodology based on an appropriate change of the initial probability measure of the probability space to a truncated (shifted) one on the
$\min\{X_{1},X_{2},\ldots,X_{T}\}$, until the stopping time T is provided by proposing a methodology based on an appropriate change of the initial probability measure of the probability space to a truncated (shifted) one on the 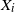 $X_{i}$. As an application of the aforementioned general result, the random variables
$X_{i}$. As an application of the aforementioned general result, the random variables 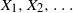 $X_{1},X_{2},\ldots$ are considered to be the interarrival times (spacings) between successive appearances of events in a renewal counting process
$X_{1},X_{2},\ldots$ are considered to be the interarrival times (spacings) between successive appearances of events in a renewal counting process 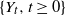 $\{Y_{t},t\geq0\}$, while the stopping time T is set to be the number of summands until the sum of the
$\{Y_{t},t\geq0\}$, while the stopping time T is set to be the number of summands until the sum of the 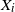 $X_{i}$ exceeds t for the first time, i.e.
$X_{i}$ exceeds t for the first time, i.e. 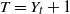 $T=Y_{t}+1$. Under this setup, the distribution of the minimal spacing,
$T=Y_{t}+1$. Under this setup, the distribution of the minimal spacing, 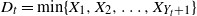 $D_{t}=\min\{X_{1},X_{2},\ldots,X_{Y_{t}+1}\}$, that starts in the interval [0, t] is investigated and a stochastic ordering relation for
$D_{t}=\min\{X_{1},X_{2},\ldots,X_{Y_{t}+1}\}$, that starts in the interval [0, t] is investigated and a stochastic ordering relation for 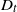 $D_{t}$ is obtained. In addition, bounds for the tail probability of
$D_{t}$ is obtained. In addition, bounds for the tail probability of 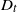 $D_{t}$ are provided when the interarrival times have the increasing failure rate / decreasing failure rate property. In the special case of a Poisson process, an exact formula, as well as closed-form bounds and an asymptotic result, are derived for the tail probability of
$D_{t}$ are provided when the interarrival times have the increasing failure rate / decreasing failure rate property. In the special case of a Poisson process, an exact formula, as well as closed-form bounds and an asymptotic result, are derived for the tail probability of 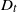 $D_{t}$. Furthermore, for renewal processes with Erlang and uniformly distributed interarrival times, exact and approximation formulae for the tail probability of
$D_{t}$. Furthermore, for renewal processes with Erlang and uniformly distributed interarrival times, exact and approximation formulae for the tail probability of 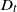 $D_{t}$ are also proposed. Finally, numerical examples are presented to illustrate the aforementioned exact and asymptotic results, and practical applications are briefly discussed.
$D_{t}$ are also proposed. Finally, numerical examples are presented to illustrate the aforementioned exact and asymptotic results, and practical applications are briefly discussed.
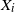
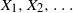
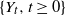
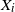
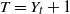
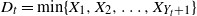
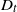
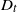
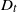
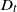
Reinventing Pareto: fits for all losses, small and large
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 21 November 2025, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On ergodicity and transience for a class of level-dependent GI/M/1-type Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 21 November 2025, pp. 1301-1317
- Print publication:
- December 2025
-
- Article
- Export citation
Government data ecosystems for addressing societal challenges: Lessons from two cases in the Netherlands
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 November 2025, e79
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Gaussian Free Field and Liouville Quantum Gravity
-
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025
Scaling limits for supercritical nearly unstable Hawkes processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 19 November 2025, pp. 607-622
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the asymptotic behavior of nearly unstable Hawkes processes whose regression kernel has
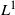 $L^1$ norm strictly greater than 1 and close to 1 as time goes to infinity. We find that the scaling size determines the scaling behavior of the processes as in Jaisson and Rosenbaum (2015). Specifically, after a suitable rescale of
$L^1$ norm strictly greater than 1 and close to 1 as time goes to infinity. We find that the scaling size determines the scaling behavior of the processes as in Jaisson and Rosenbaum (2015). Specifically, after a suitable rescale of 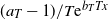 $({a_T-1})/{T{\textrm{e}}^{b_TTx}}$, the limit of the sequence of Hawkes processes is deterministic. Also, with another appropriate rescaling of
$({a_T-1})/{T{\textrm{e}}^{b_TTx}}$, the limit of the sequence of Hawkes processes is deterministic. Also, with another appropriate rescaling of 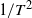 $1/T^2$, the sequence converges in law to an integrated Cox–Ingersoll–Ross-like process. This theoretical result may apply to model the recent COVID-19 outbreak in epidemiology and phenomena in social networks.
$1/T^2$, the sequence converges in law to an integrated Cox–Ingersoll–Ross-like process. This theoretical result may apply to model the recent COVID-19 outbreak in epidemiology and phenomena in social networks.
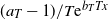
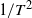
Projection-based model-order reduction via graph autoencoders suited for unstructured meshes
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 19 November 2025, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE LOCAL PROJECTION RESIDUAL BOOTSTRAP FOR AR(1) MODELS
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 19 November 2025, pp. 1-39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Examination of factors influencing accident frequency and severity of Electric Vehicles (EVs) vs Internal Combustion Engine Vehicles (ICEV)
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 18 November 2025, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Time-consistent annuitization and asset allocation under the mean-variance criterion
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 18 November 2025, pp. 648-667
- Print publication:
- June 2026
-
- Article
- Export citation
Quantifying Systemic Risk: Conditional Interval Risk Measures and Their Applications
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 18 November 2025, pp. 181-205
- Print publication:
- January 2026
-
- Article
- Export citation
Model-based clustering for network data via a latent shrinkage position cluster model
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 17 November 2025, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interpretable and efficient data-driven discovery and control of distributed systems
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 14 November 2025, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ISOTONIC PROPENSITY SCORE MATCHING
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 14 November 2025, pp. 1-51
-
- Article
-
- You have access
- Open access
- Export citation
Inhomogeneous random graphs with infinite-mean fitness variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 14 November 2025, pp. 375-400
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider an inhomogeneous Erdős–Rényi random graph ensemble with exponentially decaying random disconnection probabilities determined by an independent and identically distributed field of variables with heavy tails and infinite mean associated with the vertices of the graph. This model was recently investigated in the physics literature (Garuccio, Lalli, and Garlaschelli 2023) as a scale-invariant random graph within the context of network renormalization. From a mathematical perspective, the model fits in the class of scale-free inhomogeneous random graphs whose asymptotic geometrical features have recently attracted interest. While for this type of graph several results are known when the underlying vertex variables have finite mean and variance, here instead we consider the case of one-sided stable variables with necessarily infinite mean. To simplify our analysis, we assume that the variables are sampled from a Pareto distribution with parameter
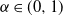 $\alpha\in(0,1)$. We start by characterizing the asymptotic distributions of the typical degrees and some related observables. In particular, we show that the degree of a vertex converges in distribution, after proper scaling, to a mixed Poisson law. We then show that correlations among degrees of different vertices are asymptotically non-vanishing, but at the same time a form of asymptotic tail independence is found when looking at the behavior of the joint Laplace transform around zero. Moreover, we present some findings concerning the asymptotic density of wedges and triangles, and show a cross-over for the existence of dust (i.e. disconnected vertices).
$\alpha\in(0,1)$. We start by characterizing the asymptotic distributions of the typical degrees and some related observables. In particular, we show that the degree of a vertex converges in distribution, after proper scaling, to a mixed Poisson law. We then show that correlations among degrees of different vertices are asymptotically non-vanishing, but at the same time a form of asymptotic tail independence is found when looking at the behavior of the joint Laplace transform around zero. Moreover, we present some findings concerning the asymptotic density of wedges and triangles, and show a cross-over for the existence of dust (i.e. disconnected vertices).
A survey of large language model use in a hospital, research, and teaching campus
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 13 November 2025, e78
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Adversarial disentanglement by backpropagation with physics-informed variational autoencoder
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 13 November 2025, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A rainbow Dirac theorem for loose Hamilton cycles in hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 11 November 2025, pp. 149-177
-
- Article
- Export citation
-
A meta-conjecture of Coulson, Keevash, Perarnau, and Yepremyan [12] states that above the extremal threshold for a given spanning structure in a (hyper-)graph, one can find a rainbow version of that spanning structure in any suitably bounded colouring of the host (hyper-)graph. We solve one of the most pertinent outstanding cases of this conjecture by showing that for any
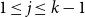 $1\leq j\leq k-1$, if
$1\leq j\leq k-1$, if 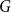 $G$ is a
$G$ is a 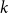 $k$-uniform hypergraph above the
$k$-uniform hypergraph above the 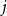 $j$-degree threshold for a loose Hamilton cycle, then any globally bounded colouring of
$j$-degree threshold for a loose Hamilton cycle, then any globally bounded colouring of 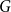 $G$ contains a rainbow loose Hamilton cycle.
$G$ contains a rainbow loose Hamilton cycle.
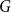
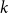
Anatomy of elite and mass polarization in social networks
- Part of
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 10 November 2025, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
