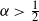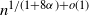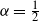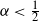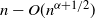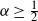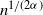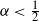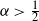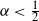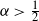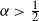Refine search
Actions for selected content:
53113 results in Statistics and Probability
What is a trustworthy national health data space in Switzerland? A national public focus group study
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 30 October 2025, e76
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reviews
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp ii-ii
-
- Chapter
- Export citation
Chapter 11 - Evidence in Science: Should We Use Data and What Data Can We Trust?
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 121-158
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp iv-iv
-
- Chapter
- Export citation
Chapter 6 - Admission Testing for Higher Education
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 72-81
-
- Chapter
- Export citation
Dedication
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp v-vi
-
- Chapter
- Export citation
Chapter 2 - Why Tests Are so Widely Disliked
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 11-23
-
- Chapter
- Export citation
Chapter 5 - Licensing Examinations
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 48-71
-
- Chapter
- Export citation
Chapter 13 - Coda
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 176-187
-
- Chapter
- Export citation
Index
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 203-208
-
- Chapter
- Export citation
Preface
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp xi-xv
-
- Chapter
- Export citation
Chapter 1 - A Brief Recounting of the First Four Millennia of Testing
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 1-10
-
- Chapter
-
- You have access
- HTML
- Export citation
Chapter 3 - The Origins and Consequences of Mental Testing in the U.S. Military
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 24-34
-
- Chapter
- Export citation
Chapter 7 - Tests Used for Merit-Based Scholarships
-
- Book:
- Testing and the Paradoxes of Fairness
- Published online:
- 10 October 2025
- Print publication:
- 30 October 2025, pp 82-89
-
- Chapter
- Export citation
National digital ID apps and disability: towards an agenda for digital inclusion?
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 29 October 2025, e74
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Catching the bad apples to keep up the good work: Dutch municipal government perspectives on data-driven technologies in unemployment
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 29 October 2025, e75
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Powers of Hamilton cycles in oriented and directed graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 28 October 2025, pp. 101-133
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The Pósa–Seymour conjecture determines the minimum degree threshold for forcing the
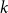 $k$th power of a Hamilton cycle in a graph. After numerous partial results, Komlós, Sárközy, and Szemerédi proved the conjecture for sufficiently large graphs. In this paper, we focus on the analogous problem for digraphs and for oriented graphs. We asymptotically determine the minimum total degree threshold for forcing the square of a Hamilton cycle in a digraph. We also give a conjecture on the corresponding threshold for
$k$th power of a Hamilton cycle in a graph. After numerous partial results, Komlós, Sárközy, and Szemerédi proved the conjecture for sufficiently large graphs. In this paper, we focus on the analogous problem for digraphs and for oriented graphs. We asymptotically determine the minimum total degree threshold for forcing the square of a Hamilton cycle in a digraph. We also give a conjecture on the corresponding threshold for 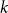 $k$th powers of a Hamilton cycle more generally. For oriented graphs, we provide a minimum semi-degree condition that forces the
$k$th powers of a Hamilton cycle more generally. For oriented graphs, we provide a minimum semi-degree condition that forces the 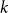 $k$th power of a Hamilton cycle; although this minimum semi-degree condition is not tight, it does provide the correct order of magnitude of the threshold. Turán-type problems for oriented graphs are also discussed.
$k$th power of a Hamilton cycle; although this minimum semi-degree condition is not tight, it does provide the correct order of magnitude of the threshold. Turán-type problems for oriented graphs are also discussed.
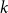
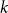
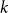
Disperse hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 27 October 2025, pp. 89-100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For
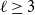 $\ell \geq 3$, an
$\ell \geq 3$, an 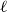 $\ell$-uniform hypergraph is disperse if the number of edges induced by any set of
$\ell$-uniform hypergraph is disperse if the number of edges induced by any set of 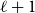 $\ell +1$ vertices is 0, 1,
$\ell +1$ vertices is 0, 1, 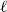 $\ell$, or
$\ell$, or 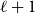 $\ell +1$. We show that every disperse
$\ell +1$. We show that every disperse 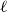 $\ell$-uniform hypergraph on
$\ell$-uniform hypergraph on  $n$ vertices contains a clique or independent set of size
$n$ vertices contains a clique or independent set of size 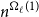 $n^{\Omega _{\ell }(1)}$, answering a question of the first author and Tomon. To this end, we prove several structural properties of disperse hypergraphs.
$n^{\Omega _{\ell }(1)}$, answering a question of the first author and Tomon. To this end, we prove several structural properties of disperse hypergraphs.
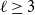
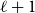
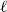
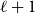
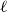

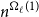
THIS SHOCK IS DIFFERENT: ESTIMATION AND INFERENCE IN MISSPECIFIED TWO-WAY FIXED EFFECTS PANEL REGRESSIONS
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 27 October 2025, pp. 1-34
-
- Article
-
- You have access
- Open access
- Export citation
Ordering and convergence of large degrees in random hyperbolic graphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 27 October 2025, pp. 661-696
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We describe the asymptotic behaviour of large degrees in random hyperbolic graphs for all values of the curvature parameter
 $\alpha$. We prove that, with high probability, the node degrees satisfy the following ordering property: the ranking of the nodes by decreasing degree coincides with the ranking of the nodes by increasing distance to the centre, at least up to any constant rank. In the sparse regime
$\alpha$. We prove that, with high probability, the node degrees satisfy the following ordering property: the ranking of the nodes by decreasing degree coincides with the ranking of the nodes by increasing distance to the centre, at least up to any constant rank. In the sparse regime 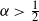 $\alpha>\tfrac{1}{2}$, the rank at which these two rankings cease to coincide is
$\alpha>\tfrac{1}{2}$, the rank at which these two rankings cease to coincide is 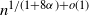 $n^{1/(1+8\alpha)+o(1)}$. We also provide a quantitative description of the large degrees by proving the convergence in distribution of the normalised degree process towards a Poisson point process. In particular, this establishes the convergence in distribution of the normalised maximum degree of the graph. A transition occurs at
$n^{1/(1+8\alpha)+o(1)}$. We also provide a quantitative description of the large degrees by proving the convergence in distribution of the normalised degree process towards a Poisson point process. In particular, this establishes the convergence in distribution of the normalised maximum degree of the graph. A transition occurs at 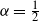 $\alpha = \tfrac{1}{2}$, which corresponds to the connectivity threshold of the model. For
$\alpha = \tfrac{1}{2}$, which corresponds to the connectivity threshold of the model. For 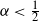 $\alpha < \tfrac{1}{2}$, the maximum degree is of order
$\alpha < \tfrac{1}{2}$, the maximum degree is of order 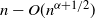 $n - O(n^{\alpha + 1/2})$, whereas for
$n - O(n^{\alpha + 1/2})$, whereas for 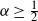 $\alpha \geq \tfrac{1}{2}$, the maximum degree is of order
$\alpha \geq \tfrac{1}{2}$, the maximum degree is of order 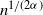 $n^{1/(2\alpha)}$. In the
$n^{1/(2\alpha)}$. In the 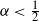 $\alpha < \tfrac{1}{2}$ and
$\alpha < \tfrac{1}{2}$ and 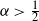 $\alpha > \tfrac{1}{2}$ cases, the limit distribution of the maximum degree belongs to the class of extreme value distributions (Weibull for
$\alpha > \tfrac{1}{2}$ cases, the limit distribution of the maximum degree belongs to the class of extreme value distributions (Weibull for 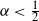 $\alpha < \tfrac{1}{2}$ and Fréchet for
$\alpha < \tfrac{1}{2}$ and Fréchet for 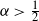 $\alpha > \tfrac{1}{2}$). This refines previous estimates on the maximum degree for
$\alpha > \tfrac{1}{2}$). This refines previous estimates on the maximum degree for 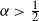 $\alpha > \tfrac{1}{2}$ and extends the study of large degrees to the dense regime
$\alpha > \tfrac{1}{2}$ and extends the study of large degrees to the dense regime 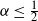 $\alpha \leq \tfrac{1}{2}$.
$\alpha \leq \tfrac{1}{2}$.