Refine search
Actions for selected content:
53140 results in Statistics and Probability
Index
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 414-416
-
- Chapter
- Export citation
Negative dependence in knockout tournaments
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 04 December 2025, pp. 536-551
- Print publication:
- June 2026
-
- Article
-
- You have access
- HTML
- Export citation
-
Negative dependence in tournaments has received attention in the literature. The property of negative orthant dependence (NOD) was proved for different tournament models with a special proof for each model. For general round-robin tournaments and knockout tournaments with random draws, Malinovsky and Rinott (2023) unified and simplified many existing results in the literature by proving a stronger property, negative association (NA). For a knockout tournament with a non-random draw, they presented an example to illustrate that
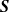 ${\boldsymbol{S}}$ is NOD but not NA. However, their proof is not correct. In this paper, we establish the properties of negative regression dependence (NRD), negative left-tail dependence (NLTD), and negative right-tail dependence (NRTD) for a knockout tournament with a random draw and with players being of equal strength. For a knockout tournament with a non-random draw and with equal strength, we prove that
${\boldsymbol{S}}$ is NOD but not NA. However, their proof is not correct. In this paper, we establish the properties of negative regression dependence (NRD), negative left-tail dependence (NLTD), and negative right-tail dependence (NRTD) for a knockout tournament with a random draw and with players being of equal strength. For a knockout tournament with a non-random draw and with equal strength, we prove that 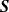 ${\boldsymbol{S}}$ is NA and NRTD, while
${\boldsymbol{S}}$ is NA and NRTD, while 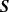 ${\boldsymbol{S}}$ is, in general, not NRD or NLTD.
${\boldsymbol{S}}$ is, in general, not NRD or NLTD.
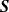
A nonzero-sum game with reinforcement learning under mean-variance framework
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 04 December 2025, pp. 154-180
- Print publication:
- January 2026
-
- Article
-
- You have access
- HTML
- Export citation
5 - Introduction to Liouville Conformal Field Theory
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 168-219
-
- Chapter
- Export citation
1 - Definition and Properties of the GFF
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 1-56
-
- Chapter
-
- You have access
- Export citation
References
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 399-410
-
- Chapter
- Export citation
7 - QuantumWedges and Scale-Invariant Random Surfaces
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 256-298
-
- Chapter
- Export citation
Notation and Symbols
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 411-413
-
- Chapter
- Export citation
Contents
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp ix-xii
-
- Chapter
- Export citation
Acknowledgements
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp xvii-xx
-
- Chapter
- Export citation
4 - Statistical Physics on Random Planar Maps
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 133-167
-
- Chapter
- Export citation
-
Summary
In this chapter, we describe a model of random planar maps weighted by self-dual Fortuin-Kasteleyn (FK) percolation. This can be thought of as a canonical discretisation of Liouville quantum gravity. We start with some generalities about planar maps and then introduce the FK random map model, which depends on a parameter
, before explaining the conjectured connection to Liouville quantum gravity. A fundamental tool for studying such random planar maps is Sheffield’s (hamburger-cheeseburger) bijection. We first explain it carefully for tree-decorated maps (the special case of the FK model of planar maps with
Frontmatter
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp i-vi
-
- Chapter
- Export citation
Appendix B - Reverse Loewner Flow and Reverse SLE
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 382-390
-
- Chapter
- Export citation
9 - Liouville Quantum Gravity as a Mating of Trees
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 334-372
-
- Chapter
- Export citation
-
Summary
In this chapter, we take forward the ideas developed in Chapter 8 and show that if one explores a
Preface
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp xiii-xvi
-
- Chapter
- Export citation
Dedication
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp vii-viii
-
- Chapter
- Export citation
8 - SLE and the Quantum Zipper
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 299-333
-
- Chapter
- Export citation
-
Summary
We describe couplings between Schramm–Loewner Evolution (SLE) curves and variants of the Gaussian free field (GFF). In particular, we give a complete proof of Sheffield’s construction of
Conflict-free hypergraph matchings and coverings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 04 December 2025, pp. 230-254
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recent work showing the existence of conflict-free almost-perfect hypergraph matchings has found many applications. We show that, assuming certain simple degree and codegree conditions on the hypergraph
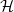 $ \mathcal{H}$ and the conflicts to be avoided, a conflict-free almost-perfect matching can be extended to one covering all vertices in a particular subset of
$ \mathcal{H}$ and the conflicts to be avoided, a conflict-free almost-perfect matching can be extended to one covering all vertices in a particular subset of 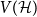 $ V(\mathcal{H})$, by using an additional set of edges; in particular, we ensure that our matching avoids all additional conflicts, which may consist of both old and new edges. This setup is useful for various applications in design theory and Ramsey theory. For example, our main result provides a crucial tool in the recent proof of the high-girth existence conjecture due to Delcourt and Postle. It also provides a black box which encapsulates many long and tedious calculations, greatly simplifying the proofs of results in generalised Ramsey theory.
$ V(\mathcal{H})$, by using an additional set of edges; in particular, we ensure that our matching avoids all additional conflicts, which may consist of both old and new edges. This setup is useful for various applications in design theory and Ramsey theory. For example, our main result provides a crucial tool in the recent proof of the high-girth existence conjecture due to Delcourt and Postle. It also provides a black box which encapsulates many long and tedious calculations, greatly simplifying the proofs of results in generalised Ramsey theory.
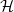
2 - Liouville Measure
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 57-74
-
- Chapter
- Export citation
-
Summary
In this chapter, we introduce the Liouville measures associated with the continuum two-dimensional Gaussian free field (GFF). Informally speaking, for a fixed parameter
Appendix D - Convergence of Random Variables in the Space of Distributions
-
- Book:
- Gaussian Free Field and Liouville Quantum Gravity
- Published online:
- 20 November 2025
- Print publication:
- 04 December 2025, pp 396-398
-
- Chapter
- Export citation
