Refine search
Actions for selected content:
53172 results in Statistics and Probability
Analysing heavy-tail properties of stochastic gradient descent by means of stochastic recurrence equations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 10 February 2026, pp. 459-483
- Print publication:
- June 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In recent works on the theory of machine learning, it has been observed that heavy tail properties of stochastic gradient descent (SGD) can be studied in the probabilistic framework of stochastic recursions. In particular, Gürbüzbalaban et al. (2021) considered a setup corresponding to linear regression for which iterations of SGD can be modelled by a multivariate affine stochastic recursion
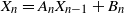 $X_n=A_nX_{n-1}+B_n$ for independent and identically distributed pairs
$X_n=A_nX_{n-1}+B_n$ for independent and identically distributed pairs 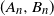 $(A_n,B_n)$, where
$(A_n,B_n)$, where 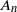 $A_n$ is a random symmetric matrix and
$A_n$ is a random symmetric matrix and 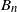 $B_n$ is a random vector. However, their approach is not completely correct and, in the present paper, the problem is put into the right framework by applying the theory of irreducible-proximal matrices.
$B_n$ is a random vector. However, their approach is not completely correct and, in the present paper, the problem is put into the right framework by applying the theory of irreducible-proximal matrices.
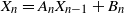
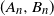
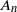
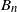
Cytomegalovirus seroprevalence and seroconversion in the Irish blood donor population
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 09 February 2026, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unravelling the dengue surge in South Asia during 2000–2023: pattern, trend, genomics, and key determinants
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 February 2026, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
IFoA Presidential Address 2025 by Paul Sweeting
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 06 February 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Excess mortality in Mainland China after the end of the Zero COVID policy: A systematic review
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 February 2026, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Antimicrobial resistance in Bordetella pertussis: A systematic review and meta-analysis
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 February 2026, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Leveraging the power of ChatGPT to analyze policy framing: policy agendas and issue positions of U.S. governors during the COVID-19 crisis
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 06 February 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measuring the excess mortality during the COVID-19 pandemic in the Northern Territory, Australia
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 February 2026, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Lorenz dominance index: a continuous measure for inequality and social welfare comparisons
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 3 / July 2026
- Published online by Cambridge University Press:
- 06 February 2026, pp. 376-399
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generalized percolation games on the two-dimensional square lattice and ergodicity of associated probabilistic cellular automata
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 06 February 2026, pp. 1-97
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a highly generalized set-up in which each vertex of the infinite two-dimensional square lattice graph (whose set of vertices is
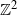 $\mathbb{Z}^{2}$, with each vertex (x, y) adjacent to each of
$\mathbb{Z}^{2}$, with each vertex (x, y) adjacent to each of 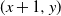 $(x+1,y)$ and
$(x+1,y)$ and 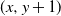 $(x,y+1)$) is assigned, independent of all else, a label that reads trap with probability p, target with probability q, and open with the remaining probability
$(x,y+1)$) is assigned, independent of all else, a label that reads trap with probability p, target with probability q, and open with the remaining probability 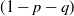 $(1-p-q)$, and, in addition, each edge is assigned, independent of all else, a label that reads trap with probability r and open with probability
$(1-p-q)$, and, in addition, each edge is assigned, independent of all else, a label that reads trap with probability r and open with probability 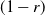 $(1-r)$. This model encompasses the seemingly more general model where, in addition to all the vertex-labels and edge-labels described above, an edge can also be labeled as a target, since assigning the label of target to an edge going from (x, y) to either
$(1-r)$. This model encompasses the seemingly more general model where, in addition to all the vertex-labels and edge-labels described above, an edge can also be labeled as a target, since assigning the label of target to an edge going from (x, y) to either 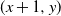 $(x+1,y)$ or
$(x+1,y)$ or 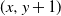 $(x,y+1)$ is equivalent to marking the vertex (x, y) as a trap. A percolation game is played on this random board, involving two players and a token. The players take turns to make moves, where a move involves relocating the token from where it is currently located, say some vertex
$(x,y+1)$ is equivalent to marking the vertex (x, y) as a trap. A percolation game is played on this random board, involving two players and a token. The players take turns to make moves, where a move involves relocating the token from where it is currently located, say some vertex 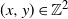 $(x,y) \in \mathbb{Z}^{2}$, to any one of
$(x,y) \in \mathbb{Z}^{2}$, to any one of 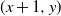 $(x+1,y)$ and
$(x+1,y)$ and 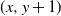 $(x,y+1)$. A player wins if she is able to move the token to a vertex labeled as a target, or force her opponent to either move the token to a vertex labeled as a trap or along an edge labeled as a trap. We seek to find a regime, in terms of values of the parameters p, q, and r, in which the probability of this game resulting in a draw equals 0. We further consider special cases of this game, such as when each edge is assigned, independently, a label that reads trap with probability r, target with probability s, and open with probability
$(x,y+1)$. A player wins if she is able to move the token to a vertex labeled as a target, or force her opponent to either move the token to a vertex labeled as a trap or along an edge labeled as a trap. We seek to find a regime, in terms of values of the parameters p, q, and r, in which the probability of this game resulting in a draw equals 0. We further consider special cases of this game, such as when each edge is assigned, independently, a label that reads trap with probability r, target with probability s, and open with probability 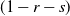 $(1-r-s)$, but the vertices are left unlabeled, and various regimes of values of r and s are explored in which the probability of draw is guaranteed to be 0. We show that the probability of draw in each such game equals 0 if and only if a suitably defined probabilistic cellular automaton (PCA) is ergodic, following which we implement the technique of weight functions or potential functions to investigate the regimes in which said PCA is ergodic. We mention here that one of the main results of Holroyd et al. (2019 Probab. Theory Related Fields 174, 1187–1217) follows as a special case of our main result. Moreover, our result shows that a phase transition happens at the origin (i.e. at
$(1-r-s)$, but the vertices are left unlabeled, and various regimes of values of r and s are explored in which the probability of draw is guaranteed to be 0. We show that the probability of draw in each such game equals 0 if and only if a suitably defined probabilistic cellular automaton (PCA) is ergodic, following which we implement the technique of weight functions or potential functions to investigate the regimes in which said PCA is ergodic. We mention here that one of the main results of Holroyd et al. (2019 Probab. Theory Related Fields 174, 1187–1217) follows as a special case of our main result. Moreover, our result shows that a phase transition happens at the origin (i.e. at 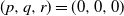 $(p,q,r)=(0,0,0)$ in the case of generalized percolation games, and at
$(p,q,r)=(0,0,0)$ in the case of generalized percolation games, and at 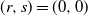 $(r,s)=(0,0)$ in the case of bond percolation games) in the sense that, the probability of draw equals 1 at
$(r,s)=(0,0)$ in the case of bond percolation games) in the sense that, the probability of draw equals 1 at 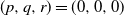 $(p,q,r)=(0,0,0)$ (respectively, at
$(p,q,r)=(0,0,0)$ (respectively, at  $(r,s)=(0,0)$), whereas in every neighborhood around (0, 0, 0) (respectively, (0, 0)), there exists some value of (p, q, r) (respectively, (r, s)) for which the probability of draw equals 0.
$(r,s)=(0,0)$), whereas in every neighborhood around (0, 0, 0) (respectively, (0, 0)), there exists some value of (p, q, r) (respectively, (r, s)) for which the probability of draw equals 0.
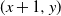
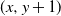
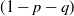
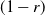
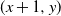
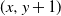
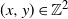
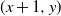
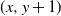
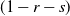
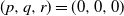
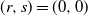
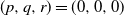


Elements of Structural Equation Models (SEMs)
-
- Published online:
- 05 February 2026
- Print publication:
- 19 February 2026
Graphical sequences and plane trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 05 February 2026, pp. 316-328
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Balister, the second author, Groenland, Johnston, and Scott recently showed that there are asymptotically
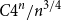 $C4^n/n^{3/4}$ many unordered sequences that occur as degree sequences of graphs with
$C4^n/n^{3/4}$ many unordered sequences that occur as degree sequences of graphs with  $n$ vertices. Combining limit theory for infinitely divisible distributions with a new connection between a class of random walk trajectories and a subset counting formula from additive number theory, we describe
$n$ vertices. Combining limit theory for infinitely divisible distributions with a new connection between a class of random walk trajectories and a subset counting formula from additive number theory, we describe 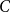 $C$ in terms of Walkup’s number of rooted plane trees. The bijection is related to an instance of the Lévy–Khintchine formula. Our main result complements a result of Stanley, that ordered graphical sequences are related to quasi-forests.
$C$ in terms of Walkup’s number of rooted plane trees. The bijection is related to an instance of the Lévy–Khintchine formula. Our main result complements a result of Stanley, that ordered graphical sequences are related to quasi-forests.

Applied probability trust prizes 2025
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 05 February 2026, p. 458
- Print publication:
- March 2026
-
- Article
- Export citation
Euler–Maruyama approximation for stable stochastic differential equations with Markovian switching and related asymptotics
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 05 February 2026, pp. 1-29
-
- Article
- Export citation
-
We investigate the EM approximation for
 $\mathbb{R}^d$-valued ergodic stochastic differential equations (SDEs) driven by rotationally invariant
$\mathbb{R}^d$-valued ergodic stochastic differential equations (SDEs) driven by rotationally invariant  $\alpha$-stable processes (
$\alpha$-stable processes ( $\alpha\in(1,2)$) with Markovian switching. The coefficient g violates the dissipative condition for certain states of the switching process. Using the Lindeberg principle, we establish quantitative error bounds between the original process
$\alpha\in(1,2)$) with Markovian switching. The coefficient g violates the dissipative condition for certain states of the switching process. Using the Lindeberg principle, we establish quantitative error bounds between the original process  $(X_t,R_t)_{t\geqslant 0}$ and its Euler–Maruyama (EM) scheme under a specially designed metric. Furthermore, we derive both a central limit theorem and a moderate derivation principle for the empirical measures of both the SDE and its EM scheme. The theoretical results are subsequently validated through a concrete example.
$(X_t,R_t)_{t\geqslant 0}$ and its Euler–Maruyama (EM) scheme under a specially designed metric. Furthermore, we derive both a central limit theorem and a moderate derivation principle for the empirical measures of both the SDE and its EM scheme. The theoretical results are subsequently validated through a concrete example.




Patterns of gastrointestinal pathogen co-detection in pediatric stool samples identified by rapid multiplex PCR
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 04 February 2026, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A robust generalized deep monotonic feature extraction model for label-free prediction of degenerative phenomena
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 04 February 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Time-inhomogeneous random walks on finite groups and cokernels of random integer block matrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 02 February 2026, pp. 329-355
-
- Article
- Export citation
Epidemiology and risk analysis of Powassan virus infection, New York state, USA, 2013–2023
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 02 February 2026, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Forest fire model on
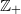 $\mathbb{Z}_+$ with delays
$\mathbb{Z}_+$ with delays
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 02 February 2026, pp. 116-134
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a generalization of the forest fire model on
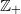 $\mathbb{Z}_+$ with ignition at zero only, studied by Volkov (2009 ALEA 6, 399–414). Unlike that model, we allow delays in the spread of the fires and the non-zero burning time of individual ‘trees’. We obtain some general properties for this model, which cover, among others, the phenomenon of an ‘infinite fire’, not present in the original model.
$\mathbb{Z}_+$ with ignition at zero only, studied by Volkov (2009 ALEA 6, 399–414). Unlike that model, we allow delays in the spread of the fires and the non-zero burning time of individual ‘trees’. We obtain some general properties for this model, which cover, among others, the phenomenon of an ‘infinite fire’, not present in the original model.

High-Dimensional Probability
- An Introduction with Applications in Data Science
-
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026
