Refine search
Actions for selected content:
53172 results in Statistics and Probability
Introduction
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 1-5
-
- Chapter
-
- You have access
- HTML
- Export citation
Chapter 4 - Bias in the Research Question Asked
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 35-43
-
- Chapter
- Export citation
Chapter 12 - Bias in the Dissemination of Study Results
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 112-119
-
- Chapter
- Export citation
Contents
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp vii-x
-
- Chapter
- Export citation
Chapter 3 - Biased Research in Recent Times – Even among Some of the Brightest
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 28-34
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp i-iv
-
- Chapter
- Export citation
Chapter 18 - Recognizing and Mitigating Bias
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 167-171
-
- Chapter
- Export citation
Chapter 1 - All at Sea
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 6-13
-
- Chapter
- Export citation
Tracking policy-relevant narratives of democratic resilience at scale: From experts and machines, to AI & the transformer revolution
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 07 May 2026, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - Testing for Unit Roots and Stationarity
- from Part I - Preliminary Questions
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 52-106
-
- Chapter
- Export citation
Chapter 7 - Compared to What?
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 60-67
-
- Chapter
- Export citation
Preface
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp xi-xii
-
- Chapter
- Export citation
Part III - Multiple-equation Regression Models
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 305-306
-
- Chapter
- Export citation
19 - Afterword
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 172-179
-
- Chapter
- Export citation
5 - Regression Models for Stationary Time Series
- from Part II - Single-equation Regression Models
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 151-223
-
- Chapter
- Export citation
Synopsis
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp vi-vi
-
- Chapter
- Export citation
Chapter 5 - Research Participation Bias
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 44-51
-
- Chapter
- Export citation
Dedication
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp v-vi
-
- Chapter
- Export citation
Subcritical annulus crossing in spatial random graphs
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 07 May 2026, pp. 1-40
-
- Article
-
- You have access
- HTML
- Export citation
-
We consider general continuum percolation models obeying sparseness, translation invariance, and spatial decorrelation. In particular, this includes models constructed on general point sets other than the standard Poisson point process or the Bernoulli-percolated lattice. Moreover, in our setting the existence of an edge may depend not only on the two end vertices but also on a surrounding vertex set and models are included that are not monotone in some of their parameters. We study the critical annulus-crossing intensity
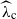 $\widehat{\lambda}_\mathrm{c}$, which is smaller than or equal to the classical critical percolation intensity
$\widehat{\lambda}_\mathrm{c}$, which is smaller than or equal to the classical critical percolation intensity 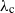 $\lambda_\mathrm{c}$ and derive a condition for
$\lambda_\mathrm{c}$ and derive a condition for 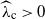 $\widehat{\lambda}_\mathrm{c}\gt 0$ by relating the crossing of annuli to the occurrence of long edges. This condition is sharp for models that have a modicum of independence. In a nutshell, our result states that annuli are either not crossed for small intensities or crossed by a single edge. Our proof rests on a multiscale argument that further allows us to directly describe the decay of the annulus-crossing probability with the decay of long-edges probabilities. We apply our result to a number of examples from the literature. Most importantly, we extensively discuss the weight-dependent random connection model in a generalized version, for which we derive sufficient conditions for the presence or absence of long edges that are typically easy to check. These conditions are built on a decay coefficient
$\widehat{\lambda}_\mathrm{c}\gt 0$ by relating the crossing of annuli to the occurrence of long edges. This condition is sharp for models that have a modicum of independence. In a nutshell, our result states that annuli are either not crossed for small intensities or crossed by a single edge. Our proof rests on a multiscale argument that further allows us to directly describe the decay of the annulus-crossing probability with the decay of long-edges probabilities. We apply our result to a number of examples from the literature. Most importantly, we extensively discuss the weight-dependent random connection model in a generalized version, for which we derive sufficient conditions for the presence or absence of long edges that are typically easy to check. These conditions are built on a decay coefficient 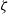 $\zeta$ that has recently seen some attention due to its importance for various proofs of global graph properties.
$\zeta$ that has recently seen some attention due to its importance for various proofs of global graph properties.
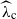
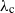
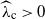
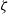
References
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 505-524
-
- Chapter
- Export citation
