Refine search
Actions for selected content:
53172 results in Statistics and Probability
Sparse surface pressure-based reconstruction of the flow around a thick airfoil over a range of angles of attack
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 14 May 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present an efficient neural-based approach to estimate the instantaneous flow field around an airfoil from limited surface pressure measurements. The model, denoted SNN-POD, relies on two independent shallow neural networks to predict the instantaneous flow over a wide range of angles of attack
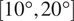 $ \left[10{}^{\circ},20{}^{\circ}\right] $. At all angles the global model correctly recovers the average characteristics of the flow from single-time sensor data, thus allowing combination with local, angle-dependent models. The method is applied to 2D URANS simulations of a thick airfoil at a Reynolds number of
$ \left[10{}^{\circ},20{}^{\circ}\right] $. At all angles the global model correctly recovers the average characteristics of the flow from single-time sensor data, thus allowing combination with local, angle-dependent models. The method is applied to 2D URANS simulations of a thick airfoil at a Reynolds number of 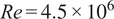 $ \mathit{\operatorname{Re}}=4.5\times {10}^6 $. The training set consists of snapshots obtained from a coarse sampling
$ \mathit{\operatorname{Re}}=4.5\times {10}^6 $. The training set consists of snapshots obtained from a coarse sampling 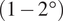 $ \left(1-2{}^{\circ}\right) $ of the angle of attack range. A variance-based criterion is used to determine the number and positions of sensors. Tests are carried out for unseen snapshots at angles of attack within the set (sampled angles) as well as outside the set (interpolated angles). The maximum MSE error of attack for sampled and interpolated angles is respectively
$ \left(1-2{}^{\circ}\right) $ of the angle of attack range. A variance-based criterion is used to determine the number and positions of sensors. Tests are carried out for unseen snapshots at angles of attack within the set (sampled angles) as well as outside the set (interpolated angles). The maximum MSE error of attack for sampled and interpolated angles is respectively 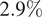 $ 2.9\% $ and
$ 2.9\% $ and 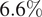 $ 6.6\% $. This makes it possible to develop adaptive strategies to improve the estimation if necessary.
$ 6.6\% $. This makes it possible to develop adaptive strategies to improve the estimation if necessary.
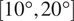
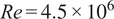
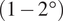
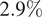
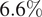
Earthquake solvency capital requirements’ re-assessment: an open-source spatio-temporal modeling approach
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 14 May 2026, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predicting crack evolution for small- and medium-span beam bridges using XGBoost–SHAP model
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 14 May 2026, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Rank-Ramsey problem and the Log-Rank conjecture
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A graph is called Rank-Ramsey if (i) Its clique number is small, and (ii) The adjacency matrix of its complement has small rank. We initiate a systematic study of such graphs. Our main motivation is that their constructions, as well as proofs of their non-existence, are intimately related to the famous log-rank conjecture from the field of communication complexity. These investigations also open interesting new avenues in Ramsey theory. We construct two families of Rank-Ramsey graphs exhibiting polynomial separation between order and complement rank. Graphs in the first family have bounded clique number (as low as
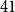 $41$). These are subgraphs of certain strong products, whose building blocks are derived from triangle-free strongly-regular graphs. Graphs in the second family are obtained by applying Boolean functions to Erdős-Rényi graphs. Their clique number is logarithmic, but their complement rank is far smaller than in the first family, about
$41$). These are subgraphs of certain strong products, whose building blocks are derived from triangle-free strongly-regular graphs. Graphs in the second family are obtained by applying Boolean functions to Erdős-Rényi graphs. Their clique number is logarithmic, but their complement rank is far smaller than in the first family, about 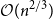 $\mathcal{O}(n^{2/3})$. A key component of this construction is our matrix-theoretic view of lifts. We also consider lower bounds on the Rank-Ramsey numbers, and determine them in the range where the complement rank is
$\mathcal{O}(n^{2/3})$. A key component of this construction is our matrix-theoretic view of lifts. We also consider lower bounds on the Rank-Ramsey numbers, and determine them in the range where the complement rank is 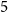 $5$ or less. We consider connections between said numbers and other graph parameters, and find that the two best known explicit constructions of triangle-free Ramsey graphs turn out to be far from Rank-Ramsey.
$5$ or less. We consider connections between said numbers and other graph parameters, and find that the two best known explicit constructions of triangle-free Ramsey graphs turn out to be far from Rank-Ramsey.
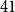
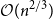
Relative contributions of public and domestic transmission domains in cholera outbreaks in displacement camps: an exploratory agent-based modeling study
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 13 May 2026, e97
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A two-account pricing framework for hybrid variable annuity contract embedded with living and death benefit riders
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-28
-
- Article
- Export citation
Stationary analysis for the fluid flow system regulated by a double-ended queue subject to catastrophic failures and repairs
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 11 May 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cost-of-capital valuation with risky assets
- Part of
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 11 May 2026, pp. 1-24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

All of Regression
-
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026
Asymptotic properties of wavelet estimators in a semi-parametric EV models with ANA errors
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 08 May 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, when the errors in the semi-parametric errors-in-variables model are asymptotic negatively associated (or ρ−, for short) random variables, the estimators of parameter, non-parameter, and error variances in the model are
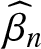 $\widehat{\beta}_{n}$,
$\widehat{\beta}_{n}$, 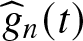 $\widehat{g}_{n}(t)$, and
$\widehat{g}_{n}(t)$, and 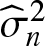 $ \widehat{\sigma}_{n}^{2}$, respectively, by using wavelet smoothing and least square method. Under some general assumptions, we also establish some results on the strong consistency of the estimators. Furthermore, simulations are conducted to assess the finite sample behavior of the estimators and confirm the validity of the theoretical results.
$ \widehat{\sigma}_{n}^{2}$, respectively, by using wavelet smoothing and least square method. Under some general assumptions, we also establish some results on the strong consistency of the estimators. Furthermore, simulations are conducted to assess the finite sample behavior of the estimators and confirm the validity of the theoretical results.
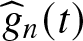
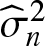
A data-driven assessment of buckling strength reduction in truncated conical shells: development of a hybrid Gaussian process-XG boost machine learning framework
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 08 May 2026, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analyzing pension fund mortality with Gaussian processes in a subpopulation framework
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 08 May 2026, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tables
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp xv-xvi
-
- Chapter
- Export citation
9 - Vector Autoregression for Unit Root Time Series
- from Part III - Multiple-equation Regression Models
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 382-488
-
- Chapter
- Export citation
Chapter 6 - Bias in Study Subjects
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 52-59
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp xvii-xviii
-
- Chapter
- Export citation
8 - Vector Autoregression for Stationary Time Series
- from Part III - Multiple-equation Regression Models
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 307-381
-
- Chapter
- Export citation
Chapter 11 - Bias in Study Interpretation
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 100-111
-
- Chapter
- Export citation
2 - Univariate Time Series Models
- from Part I - Preliminary Questions
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 21-51
-
- Chapter
- Export citation
6 - Regression Models for Unit Root Time Series
- from Part II - Single-equation Regression Models
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 224-272
-
- Chapter
- Export citation
