Refine search
Actions for selected content:
53141 results in Statistics and Probability
New stationarity conditions for IARCH processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 May 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A unified palm measure framework for failure-event-based component importance measures in nonrepairable, repairable, and phase-mission systems
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 28 May 2026, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing joint ideal point estimation strategies with Twitter social networks and text data
- Part of
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 28 May 2026, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bi-level optimization of security investment and insurance pricing
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 28 May 2026, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Seasonal Dynamics and Structural Changes in Dengue Transmission in Eastern Northeast of Brazil: A Time-Series Decomposition Using SSA and Pre- vs Post-COVID Comparative Analysis
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 28 May 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- Export citation
On the number of crossings and bouncings of a diffusion at a sticky threshold
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 May 2026, pp. 1-27
-
- Article
-
- You have access
- HTML
- Export citation
LLM for social good: A value-driven LLM framework to embed social good values
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 28 May 2026, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Developing Theories in the Social Sciences
- Methods and Applications
-
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026
Incidence of skin and soft-tissue infections in England: 11-year retrospective study
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 26 May 2026, e80
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Probability that n points are in convex position in a general convex polygon: Asymptotic results
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 26 May 2026, pp. 1-26
-
- Article
- Export citation
-
Let
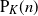 $\mathrm{P}_K(n)$ be the probability that n points
$\mathrm{P}_K(n)$ be the probability that n points 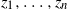 $z_1,\ldots,z_n$ picked uniformly and independently in K, a compact convex polygon in
$z_1,\ldots,z_n$ picked uniformly and independently in K, a compact convex polygon in 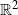 $\mathbb{R}^2$ with non-empty interior, are in convex position, that is, form the vertex set of a convex polygon. In this paper, the exact asymptotic behaviour of
$\mathbb{R}^2$ with non-empty interior, are in convex position, that is, form the vertex set of a convex polygon. In this paper, the exact asymptotic behaviour of 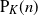 $\mathrm{P}_K(n)$ is determined as
$\mathrm{P}_K(n)$ is determined as 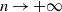 $n\to+\infty$. This improves on a famous result of Bárány [1999 Ann. Probab. 27, 2020–2034] (yet valid for a general convex set K) and a result initiated in the case where K is a regular convex polygon (Morin [2025 Adv. Appl. Probab. 57, 811–870]).
$n\to+\infty$. This improves on a famous result of Bárány [1999 Ann. Probab. 27, 2020–2034] (yet valid for a general convex set K) and a result initiated in the case where K is a regular convex polygon (Morin [2025 Adv. Appl. Probab. 57, 811–870]).
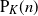
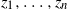
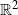
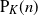
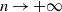
Tuberculosis infection in an urban homeless population
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 25 May 2026, e78
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unjustified Poisson assumptions lead to overconfident estimates of the effective reproductive number
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 25 May 2026, e79
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Inference in Statistical Modelling and Machine Learning
- A Concise Introduction
-
- Published online:
- 22 May 2026
- Print publication:
- 23 July 2026
An immunization method using a context-based centrality in multiplex networks
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 22 May 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rebuilding trust in public health: Beyond polarization
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 21 May 2026, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mapping malaria risk using geospatial and AHP approaches in Nsanje District, Malawi
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 21 May 2026, e76
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI-driven underwater 3D scanning: enhancing efficiency and accuracy with Bayesian optimization and Gaussian process regression
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 21 May 2026, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Alpha-robust non-zero-sum investment and reinsurance games with bounded memory and default risk
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 21 May 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Functional limit theorems for branching processes in a nearly degenerate varying environment
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 20 May 2026, pp. 1-20
-
- Article
- Export citation
-
We investigate branching processes in a nearly degenerate varying environment, where the offspring distribution converges to the degenerate distribution at 1. Such processes die out almost surely; therefore, we either condition on non-extinction or add inhomogeneous immigration. Extending our one-dimensional limit results from Kevei and Kubatovics (2024), we derive functional limit theorems. In the former case, the limit process is a time-changed simple birth-and-death process on
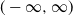 $(-\infty, \infty)$ conditioned on survival at 0, while in the latter, it is a time-changed stationary continuous-time Markov branching process with immigration.
$(-\infty, \infty)$ conditioned on survival at 0, while in the latter, it is a time-changed stationary continuous-time Markov branching process with immigration.
Dynamic Financial Analysis (DFA) of general insurers under climate change
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 20 May 2026, pp. 1-39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
