Refine search
Actions for selected content:
52923 results in Statistics and Probability
A CONSISTENT ICM-BASED
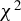 $\chi^2$ SPECIFICATION TEST
$\chi^2$ SPECIFICATION TEST
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 13 April 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In spite of the omnibus property of integrated conditional moment (ICM) specification tests, they are not commonly used in empirical practice owing to features such as the non-pivotality of the test and the high computational cost of available bootstrap schemes, especially in large samples. This article proposes specification and mean independence tests based on ICM metrics. The proposed test exhibits consistency, asymptotic
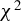 $\chi ^2$-distribution under the null hypothesis, and computational efficiency. Moreover, it demonstrates robustness to heteroskedasticity of unknown form and can be adapted to enhance power toward specific alternatives. A power comparison with classical bootstrap-based ICM tests using Bahadur slopes is also provided. Monte Carlo simulations are conducted to showcase the excellent size control and competitive power of the proposed test.
$\chi ^2$-distribution under the null hypothesis, and computational efficiency. Moreover, it demonstrates robustness to heteroskedasticity of unknown form and can be adapted to enhance power toward specific alternatives. A power comparison with classical bootstrap-based ICM tests using Bahadur slopes is also provided. Monte Carlo simulations are conducted to showcase the excellent size control and competitive power of the proposed test.
In search of common ground: Exploring value networks at the UNFCCC climate change talks
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 13 April 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data, algorithmic targeting, and artificial intelligence (AI) technologies in adaptive social cash systems: towards an AI governance framework
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 13 April 2026, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
County of San Diego, California, Investigates Salmonella Typhimurium Outbreak Linked to Unpasteurized Milk — September 2023–January 2024
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 13 April 2026, pp. 1-24
-
- Article
-
- You have access
- Open access
- Export citation
A star is born: Explosive Crump–Mode–Jagers branching processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 13 April 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Local genomic epidemiology investigations of SARS-CoV-2 during the early pandemic response: A global systematic review
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 10 April 2026, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lévy processes under level-dependent Poisson switching
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 10 April 2026, pp. 1-34
-
- Article
- Export citation

An exploratory hybrid AI workflow for Brazilian federal budget allocation
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 08 April 2026, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotic normality for triangle counting in the sparse
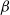 $\beta$-model
$\beta$-model
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the number of triangles
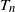 $T_n$ in the sparse
$T_n$ in the sparse 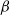 $\beta$-model on n vertices, a random graph model that captures degree heterogeneity in real-world networks. Using the norms of the heterogeneity parameter vector, we first determine the asymptotic mean and variance of
$\beta$-model on n vertices, a random graph model that captures degree heterogeneity in real-world networks. Using the norms of the heterogeneity parameter vector, we first determine the asymptotic mean and variance of 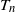 $T_n$. Next, by applying the Malliavin–Stein method, we derive a non-asymptotic upper bound on the Kolmogorov distance between the normalized
$T_n$. Next, by applying the Malliavin–Stein method, we derive a non-asymptotic upper bound on the Kolmogorov distance between the normalized 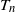 $T_n$ and the standard normal distribution. Under an additional assumption on degree heterogeneity, we further prove the asymptotic normality for
$T_n$ and the standard normal distribution. Under an additional assumption on degree heterogeneity, we further prove the asymptotic normality for 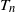 $T_n$ as
$T_n$ as 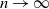 $n\to\infty$.
$n\to\infty$.
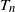
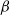
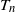
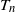
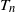
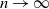
On the study of bivariate and conditional dynamic negative cumulative extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mean-field stochastic Volterra equations
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Investigation of a prolonged nursery outbreak of Salmonella Poona in England identified using whole genome sequencing, 2016–2021
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 07 April 2026, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dynamic screening strategies for the control of a prolonged vancomycin-resistant enterococci outbreak: A decade-long study in a Japanese tertiary hospital
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 07 April 2026, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparing wastewater-based and case-based Rt estimates of SARS-CoV-2 transmission in Georgia using generalized linear mixed models
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e63
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The COVID-19 pandemic has highlighted limitations in case-based surveillance due to inconsistent testing and reporting. Wastewater-based epidemiology (WBE) has emerged as a complementary surveillance approach for tracking SARS-CoV-2 transmission, capturing both symptomatic and asymptomatic infections. The aim of this study was to evaluate the effectiveness of WBE in estimating the effective reproduction number (
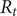 $ {R}_t $) of SARS-CoV-2 in Georgia, USA. We used a Generalized Linear Mixed Model (GLMM) to analyse viral concentration data from multiple wastewater treatment plants (WWTPs) collected between 1 June 2022 and 15 December 2022. After controlling for flow rates and site-level heterogeneity, model residuals were transformed into a non-negative incidence-like series used to estimate wastewater-based
$ {R}_t $) of SARS-CoV-2 in Georgia, USA. We used a Generalized Linear Mixed Model (GLMM) to analyse viral concentration data from multiple wastewater treatment plants (WWTPs) collected between 1 June 2022 and 15 December 2022. After controlling for flow rates and site-level heterogeneity, model residuals were transformed into a non-negative incidence-like series used to estimate wastewater-based 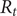 $ {R}_t $. Wastewater-based
$ {R}_t $. Wastewater-based 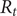 $ {R}_t $was compared with case-based
$ {R}_t $was compared with case-based 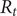 $ {R}_t $estimates using Spearman correlation. The two
$ {R}_t $estimates using Spearman correlation. The two 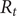 $ {R}_t $ estimates showed concordant temporal patterns across most sites, with stronger correlations in areas with higher case counts (Spearman correlations ranging from 0.39 to 0.84,
$ {R}_t $ estimates showed concordant temporal patterns across most sites, with stronger correlations in areas with higher case counts (Spearman correlations ranging from 0.39 to 0.84, 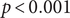 $ p<0.001 $). Wastewater-based
$ p<0.001 $). Wastewater-based 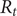 $ {R}_t $ tracked increases and decreases in transmission over similar time scales as case-based estimates, while exhibiting reduced sensitivity to short-term changes in clinical testing and reporting behaviour. These findings suggest that WBE can support estimation of transmission trends and complement traditional case-based surveillance for public health monitoring.
$ {R}_t $ tracked increases and decreases in transmission over similar time scales as case-based estimates, while exhibiting reduced sensitivity to short-term changes in clinical testing and reporting behaviour. These findings suggest that WBE can support estimation of transmission trends and complement traditional case-based surveillance for public health monitoring.
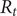
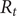
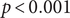
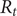
Perfect partitions of a random set of integers
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
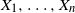 $X_1,\ldots, X_n$ be independent integers distributed uniformly on [M],
$X_1,\ldots, X_n$ be independent integers distributed uniformly on [M], 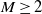 $M\ge 2$. A partition S of [n] into
$M\ge 2$. A partition S of [n] into  $\nu$ non-empty subsets
$\nu$ non-empty subsets 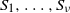 $S_1,\ldots, S_{\nu}$ is called perfect if all
$S_1,\ldots, S_{\nu}$ is called perfect if all  $\nu$ values
$\nu$ values  $\sum_{j\in S_{\alpha}}X_j$ are equal. For a perfect partition to exist,
$\sum_{j\in S_{\alpha}}X_j$ are equal. For a perfect partition to exist, 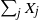 $\sum_j X_j$ has to be divisible by
$\sum_j X_j$ has to be divisible by  $\nu$. In 2001, for
$\nu$. In 2001, for 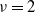 $\nu=2$, Christian Borgs, Jennifer Chayes, and the author proved that, conditioned on
$\nu=2$, Christian Borgs, Jennifer Chayes, and the author proved that, conditioned on 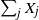 $\sum_j X_j$ being even, with high probability a perfect partition exists if
$\sum_j X_j$ being even, with high probability a perfect partition exists if 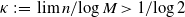 $\kappa\;:\!=\; \lim {{n}/{\log M}}>{{1}/{\log 2}}$, and that with high probability no perfect partition exists if
$\kappa\;:\!=\; \lim {{n}/{\log M}}>{{1}/{\log 2}}$, and that with high probability no perfect partition exists if 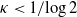 $\kappa<{{1}/{\log 2}}$. Responding to a question by George Varghese, we prove that for
$\kappa<{{1}/{\log 2}}$. Responding to a question by George Varghese, we prove that for  $\nu\ge 3$ with high probability no perfect partition exists if
$\nu\ge 3$ with high probability no perfect partition exists if  $\kappa<{{2}/{\log \nu}}$, which is twice as large as the naive threshold
$\kappa<{{2}/{\log \nu}}$, which is twice as large as the naive threshold  $1/\log 3$ for
$1/\log 3$ for 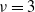 $\nu=3$. We identify the range of
$\nu=3$. We identify the range of  $\kappa$ where the expected number of perfect partitions is exponentially high. We show that for
$\kappa$ where the expected number of perfect partitions is exponentially high. We show that for 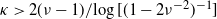 $\kappa> {{2(\nu-1)}/{\log[(1-2\nu^{-2})^{-1}]}}$ the total number of perfect partitions is exponentially high with probability
$\kappa> {{2(\nu-1)}/{\log[(1-2\nu^{-2})^{-1}]}}$ the total number of perfect partitions is exponentially high with probability 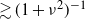 $\gtrsim (1+\nu^2)^{-1}$, i.e. below
$\gtrsim (1+\nu^2)^{-1}$, i.e. below  $1/\nu$, the limiting probability that
$1/\nu$, the limiting probability that 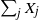 $\sum_j X_j$ is divisible by
$\sum_j X_j$ is divisible by  $\nu$.
$\nu$.
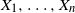
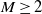

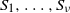


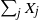

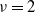
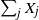
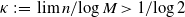
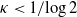



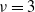

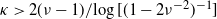
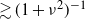

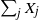

Reducing antimicrobial use in livestock alone may be not sufficient to reduce antimicrobial resistance among human Campylobacter infections: an ecological study in the Netherlands – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RANDOMIZED TESTING FOR JUMP DETECTION
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-42
-
- Article
- Export citation
Stakeholder engagement for sustainable open research data support services: insights from interviews and surveys in Switzerland
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE ECONOMETRIC THEORY INTERVIEW: PROFESSOR MARCO LIPPI
-
- Journal:
- Econometric Theory , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-37
-
- Article
- Export citation
Disease burden associated with influenza activity at the population level
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 06 April 2026, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
