Refine search
Actions for selected content:
53140 results in Statistics and Probability
Author Index
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 935-951
-
- Chapter
- Export citation
Appendix
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 866-897
-
- Chapter
- Export citation
19 - Random Processes on Networks
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 570-594
-
- Chapter
- Export citation
2 - Network Data Sets
- from Part I - Basic Setting
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 9-27
-
- Chapter
- Export citation
9 - Normal Approximation
- from Part II - Probability Preliminaries
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 213-237
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 1-6
-
- Chapter
-
- You have access
- Export citation
15 - Random Geometric Graphs
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 489-530
-
- Chapter
- Export citation
18 - Dense Graph Limits and Graphon Models
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 560-569
-
- Chapter
- Export citation
Hush hush: Keeping neural networks claims modelling private, secret, and distributed using federated learning: Discussion
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 25 June 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contents
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp vii-xvi
-
- Chapter
- Export citation
8 - Ramifications of Poisson Approximation
- from Part II - Probability Preliminaries
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 187-212
-
- Chapter
- Export citation
5 - Branching Processes
- from Part II - Probability Preliminaries
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 121-155
-
- Chapter
- Export citation
Quantum internal models
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 25 June 2026, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A large hole in pseudo-random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 25 June 2026, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that there exist constants
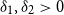 $\delta _1,\delta _2\gt 0$ such that if
$\delta _1,\delta _2\gt 0$ such that if 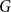 $G$ is an
$G$ is an 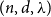 $(n,d,\lambda )$-graph with
$(n,d,\lambda )$-graph with 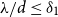 $\lambda /d\le \delta _1$, then
$\lambda /d\le \delta _1$, then 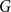 $G$ contains an induced cycle of length at least
$G$ contains an induced cycle of length at least 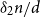 $\delta _2n/d$. We further demonstrate that, up to a constant factor, this is best possible. Utilising our techniques, we derive that the number of non-isomorphic induced subgraphs of such
$\delta _2n/d$. We further demonstrate that, up to a constant factor, this is best possible. Utilising our techniques, we derive that the number of non-isomorphic induced subgraphs of such 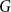 $G$ is at least exponential in
$G$ is at least exponential in 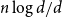 $n\log d/d$, and further demonstrate that this is tight up to a constant factor in the exponent.
$n\log d/d$, and further demonstrate that this is tight up to a constant factor in the exponent.
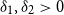
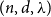
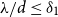
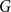
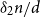
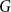
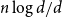
13 - The Chung–Lu Model
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 364-406
-
- Chapter
- Export citation
16 - Small World Graphs
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 531-542
-
- Chapter
- Export citation
Transparent and fair profiling in employment services: evidence from Switzerland
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 24 June 2026, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The socio-economic shield limits Lassa virus spillover in urban West Africa
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 24 June 2026, e88
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The impact of topical or oral antibiotics in children with acute otitis media on their middle ear, nasopharyngeal, and gut microbiomes
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 23 June 2026, e94
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessing the extent to which network structure causes people to be perceived as a leader
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 23 June 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
