Refine search
Actions for selected content:
53140 results in Statistics and Probability
Spanning clique subdivisions in pseudorandom graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 06 July 2026, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study the appearance of a spanning subdivision of a clique in graphs satisfying certain pseudorandom conditions. Specifically, we show the following results.
(i) There are constants
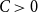 $C\gt 0$ and
$C\gt 0$ and 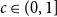 $c\in (0,1]$ such that, whenever
$c\in (0,1]$ such that, whenever 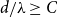 $d/\lambda \ge C$, every
$d/\lambda \ge C$, every 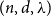 $(n,d,\lambda )$-graph contains a spanning subdivision of
$(n,d,\lambda )$-graph contains a spanning subdivision of 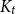 $K_t$ for all
$K_t$ for all 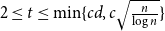 $2\le t \le \min \{cd,c\sqrt {\frac {n}{\log n}}\}$.
$2\le t \le \min \{cd,c\sqrt {\frac {n}{\log n}}\}$.(ii) There are constants
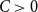 $C\gt 0$ and
$C\gt 0$ and 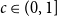 $c\in (0,1]$ such that, whenever
$c\in (0,1]$ such that, whenever 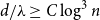 $d/\lambda \ge C\log ^3n$, every
$d/\lambda \ge C\log ^3n$, every 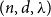 $(n,d,\lambda )$-graph contains a spanning nearly balanced subdivision of
$(n,d,\lambda )$-graph contains a spanning nearly balanced subdivision of 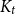 $K_t$ for all
$K_t$ for all 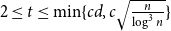 $2\le t \le \min \{cd,c\sqrt {\frac {n}{\log ^3n}}\}$.
$2\le t \le \min \{cd,c\sqrt {\frac {n}{\log ^3n}}\}$.(iii) For every
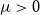 $\mu \gt 0$, there are constants
$\mu \gt 0$, there are constants 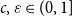 $c,\varepsilon \in (0,1]$ and
$c,\varepsilon \in (0,1]$ and 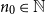 $n_0\in \mathbb N$ such that, whenever
$n_0\in \mathbb N$ such that, whenever  $n\ge n_0$, every
$n\ge n_0$, every  $n$-vertex graph with minimum degree at least
$n$-vertex graph with minimum degree at least 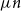 $\mu n$ and no bipartite holes of size
$\mu n$ and no bipartite holes of size 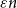 $\varepsilon n$ contains a spanning nearly balanced subdivision of
$\varepsilon n$ contains a spanning nearly balanced subdivision of 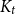 $K_t$ for all
$K_t$ for all 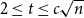 $2\le t \le c\sqrt {n}$.
$2\le t \le c\sqrt {n}$.
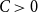
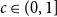
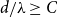
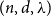
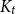
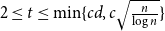
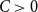
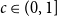
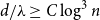
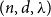
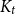
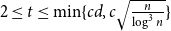
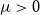
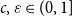
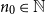


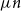
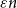
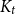
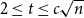
On the local convergence of integer-valued Lipschitz functions on regular trees
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 06 July 2026, pp. 1-33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study random integer-valued Lipschitz functions on regular trees. It was shown by Peled, Samotij, and Yehudayoff [22] that such functions are localized; however, finer questions about the structure of Gibbs measures remain unanswered. Our main result is that the weak limit of a uniformly chosen 1-Lipschitz function with 0 boundary condition on a
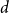 $d$-ary tree of height
$d$-ary tree of height  $n$ exists as
$n$ exists as 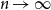 $n \to \infty$ if
$n \to \infty$ if 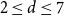 $2 \le d \le 7$, but not if
$2 \le d \le 7$, but not if 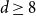 $d \ge 8$, thereby partially answering a question posed by Peled, Samotij and Yehudayoff. For large
$d \ge 8$, thereby partially answering a question posed by Peled, Samotij and Yehudayoff. For large 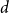 $d$, the value at the root alternates between being almost entirely concentrated on 0 for even
$d$, the value at the root alternates between being almost entirely concentrated on 0 for even  $n$ and being roughly uniform on
$n$ and being roughly uniform on 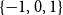 $\{-1,0,1\}$ for odd
$\{-1,0,1\}$ for odd  $n$, leading to different limits as
$n$, leading to different limits as  $n$ approaches infinity along evens or odds. For
$n$ approaches infinity along evens or odds. For 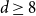 $d \ge 8$, the essence of this phenomenon is preserved, which obstructs the convergence. For
$d \ge 8$, the essence of this phenomenon is preserved, which obstructs the convergence. For 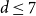 $d \le 7$, this phenomenon ceases to exist, and the law of the value at the root loses its connection with the parity of
$d \le 7$, this phenomenon ceases to exist, and the law of the value at the root loses its connection with the parity of  $n$. Along the way, we also obtain an alternative proof of localization. The key idea is a fixed point convergence result for a related operator on
$n$. Along the way, we also obtain an alternative proof of localization. The key idea is a fixed point convergence result for a related operator on 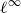 $\ell ^\infty$ and a procedure to show that the iterations get into a ‘basin of attraction’ of the fixed point. We also prove some accompanying analogous ‘even-odd phenomenon’ type results about
$\ell ^\infty$ and a procedure to show that the iterations get into a ‘basin of attraction’ of the fixed point. We also prove some accompanying analogous ‘even-odd phenomenon’ type results about 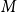 $M$-Lipschitz functions on general non-amenable graphs with high enough expansion (this includes for example the large
$M$-Lipschitz functions on general non-amenable graphs with high enough expansion (this includes for example the large 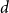 $d$ case for regular trees). We also prove a convergence result for 1-Lipschitz functions with
$d$ case for regular trees). We also prove a convergence result for 1-Lipschitz functions with 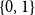 $\{0,1\}$ boundary condition. This last result relies on an absolute value FKG for uniform 1-Lipschitz functions when shifted by
$\{0,1\}$ boundary condition. This last result relies on an absolute value FKG for uniform 1-Lipschitz functions when shifted by 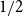 $1/2$.
$1/2$.

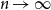
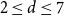
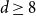

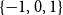


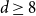
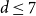

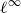
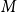
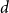
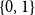
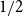
Recommendations for conducting ethical network research
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 02 July 2026, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How safe are women? Constructing a cross-national index on the foundations of women’s safety
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 29 June 2026, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiological Investigation of a Large Trichinellosis Outbreak in Lebanon, October 2023 – February 2024
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 29 June 2026, pp. 1-30
-
- Article
-
- You have access
- Open access
- Export citation
Pandemic preparedness: potential of routine general practice data for infectious disease early signal detection
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 29 June 2026, pp. 1-32
-
- Article
-
- You have access
- Open access
- Export citation

A Course in Interacting Particle Systems
-
- Published online:
- 26 June 2026
- Print publication:
- 23 July 2026
Using forensic autopsy data to estimate the age-specific infection fatality risk of COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 26 June 2026, e96
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mortality modeling for short-term climate stress test in France: impact of extreme heat
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 26 June 2026, pp. 1-36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ASSOCIATION BETWEEN INTRODUCTION OF 13-VALENT PNEUMOCOCCAL CONJUGATE VACCINE AND BURDEN OF HOSPITALIZED ADULT PNEUMOCOCCAL DISEASE IN TAIWAN – A RETROSPECTIVE DATABASE STUDY
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 26 June 2026, pp. 1-38
-
- Article
-
- You have access
- Open access
- Export citation
Maternal and congenital syphilis in Fiji 2019-2022: a secondary analysis of clinical trial data
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 26 June 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- Export citation
Matrix-based factor analysis on the prediction of insurance claims probability
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 26 June 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quantifying and pricing crop yield risk under climate change: a hierarchical model forecasting perspective
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 26 June 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
20 - Summary of Chapters 5–19
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 595-606
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp i-iv
-
- Chapter
- Export citation
11 - The Bernoulli Random Graph
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 259-314
-
- Chapter
- Export citation
21 - Sampling from Networks
- from Part IV - Network Inference
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 609-647
-
- Chapter
- Export citation
26 - Some Further Topics
- from Part IV - Network Inference
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 848-865
-
- Chapter
- Export citation
Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 257-258
-
- Chapter
- Export citation
14 - The Configuration and GPDS Models
- from Part III - Network Models
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 407-488
-
- Chapter
- Export citation
