Refine search
Actions for selected content:
53172 results in Statistics and Probability
Mixed data-source transfer learning for a turbulence model augmented physics-informed neural network
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 10 July 2026, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Physics-informed neural networks (PINNs) are a promising alternative for extracting additional time-averaged (mean) flow quantities from experimental data. In the case of particle image velocimetry (PIV), for example, the measured mean flow field is contaminated by noise, has a limited field of view, is restricted to a uniform grid, and does not provide the pressure field. To overcome these limitations, we present a methodology in which PINNs are first trained on a Reynolds-averaged Navier–Stokes (RANS) simulation such that it learns all states at every location in the domain. We then apply transfer learning, which updates the PINN using sub-sampled PIV data. The resulting predictions are in significantly better agreement with the full PIV dataset than PINNs, which are trained on experimental data only. This work builds on the recent literature by integrating a Spalart-Allmaras turbulence model and applying hard constraints to the no-slip wall boundary condition. We apply this methodology to a two-dimensional NACA 0012 airfoil inclined at an angle of attack, $ \alpha $
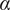 = 15°, for two Reynolds numbers of Re = 10,000 and 75,000. The proposed methodology is initially validated using large eddy simulation (LES) data and then demonstrated on experimental PIV data. Our transfer learning approach results in improved predictions and a reduction in training time when compared to using a random network initialization.
= 15°, for two Reynolds numbers of Re = 10,000 and 75,000. The proposed methodology is initially validated using large eddy simulation (LES) data and then demonstrated on experimental PIV data. Our transfer learning approach results in improved predictions and a reduction in training time when compared to using a random network initialization.
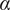
Lower deviations for branching processes with immigration
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 10 July 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
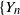 $\{Y_{n}$,
$\{Y_{n}$, 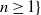 $n \geq 1\}$ be a critical branching process with immigration having finite variance for the offspring number of particles and finite mean for the immigrating number of particles. In this paper we study lower deviation probabilities for
$n \geq 1\}$ be a critical branching process with immigration having finite variance for the offspring number of particles and finite mean for the immigrating number of particles. In this paper we study lower deviation probabilities for 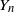 $Y_{n}$. More precisely, assuming that
$Y_{n}$. More precisely, assuming that 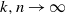 $k,n \to \infty$ so that
$k,n \to \infty$ so that 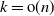 $k={\mathrm{o}} (n)$, we investigate the asymptotics of
$k={\mathrm{o}} (n)$, we investigate the asymptotics of 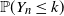 $\mathbb P(Y_{n} \leq k )$ and
$\mathbb P(Y_{n} \leq k )$ and 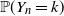 $\mathbb P(Y_{n} = k )$. Our results clarify the role of the moment conditions in the local limit theorem for
$\mathbb P(Y_{n} = k )$. Our results clarify the role of the moment conditions in the local limit theorem for 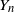 $Y_n$ proved by Mellein (1982).
$Y_n$ proved by Mellein (1982).
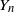
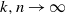
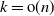
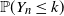
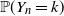
Cancer and insurance: strategies, risks, and models
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 2 / July 2026
- Published online by Cambridge University Press:
- 09 July 2026, pp. 213-216
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Author response to: Letter to the Editor on ‘Adherence to oral zinc supplementation in the management of acute diarrhoeal disease among under-5 children: A systematic review and meta-analysis’
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 08 July 2026, e92
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stationary analysis for the fluid flow system regulated by a double-ended queue subject to catastrophic failures and repairs – ADDENDUM
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 08 July 2026, p. 1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Efficacy of Dihydroartemisinin-piperaquine to Prevent Malaria and Complication-related Malaria during Pregnancy Compared to Sulfadoxine-pyrimethamine: A Systematic Review, Meta-analysis, and Meta-regression
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 08 July 2026, pp. 1-28
-
- Article
-
- You have access
- Open access
- Export citation
An analysis of diabetes mortality risk
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 08 July 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayesian multi-model time series approach for structural health monitoring with sequential updates
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 08 July 2026, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Perimeter length of the convex hull of Brownian motion in the hyperbolic plane
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 July 2026, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A stochastic Gordon–Loeb model for optimal cybersecurity investment under clustered attacks
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 07 July 2026, pp. 1-29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Numerical solution for stochastic differential equations driven by
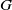 $G$-Brownian motion under locally Lipschitz continuous coefficients
$G$-Brownian motion under locally Lipschitz continuous coefficients
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 July 2026, pp. 1-19
-
- Article
-
- You have access
- HTML
- Export citation
-
Since stochastic differential equations (SDEs) driven by G-Brownian motion are of great importance in modeling situations that incorporate ambiguity, it is essential to address efficient numerical schemes to approximate the solution of such equations. The stream of research related to the numerical solutions of G-SDEs under standard assumptions is to some extent well understood. In this note, we are interested in designing an implicit
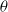 $\theta$-Euler–Maruyama scheme to approximate the solution of G-SDEs under locally Lipschitz continuous coefficients. The convergence of the proposed scheme is established using the stopping time technique. In addition, we investigate the exponentially/quasi-surely asymptotic stability property of the scheme.
$\theta$-Euler–Maruyama scheme to approximate the solution of G-SDEs under locally Lipschitz continuous coefficients. The convergence of the proposed scheme is established using the stopping time technique. In addition, we investigate the exponentially/quasi-surely asymptotic stability property of the scheme.
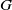
Estimating hepatitis A immunity and outbreak risk among MSM in New South Wales, Australia, 2017–2018
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 07 July 2026, e100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Spanning clique subdivisions in pseudorandom graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 06 July 2026, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study the appearance of a spanning subdivision of a clique in graphs satisfying certain pseudorandom conditions. Specifically, we show the following results.
(i) There are constants
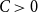 $C\gt 0$ and
$C\gt 0$ and 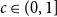 $c\in (0,1]$ such that, whenever
$c\in (0,1]$ such that, whenever 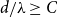 $d/\lambda \ge C$, every
$d/\lambda \ge C$, every 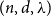 $(n,d,\lambda )$-graph contains a spanning subdivision of
$(n,d,\lambda )$-graph contains a spanning subdivision of 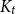 $K_t$ for all
$K_t$ for all 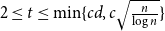 $2\le t \le \min \{cd,c\sqrt {\frac {n}{\log n}}\}$.
$2\le t \le \min \{cd,c\sqrt {\frac {n}{\log n}}\}$.(ii) There are constants
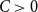 $C\gt 0$ and
$C\gt 0$ and 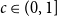 $c\in (0,1]$ such that, whenever
$c\in (0,1]$ such that, whenever 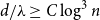 $d/\lambda \ge C\log ^3n$, every
$d/\lambda \ge C\log ^3n$, every 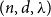 $(n,d,\lambda )$-graph contains a spanning nearly balanced subdivision of
$(n,d,\lambda )$-graph contains a spanning nearly balanced subdivision of 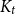 $K_t$ for all
$K_t$ for all 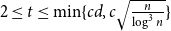 $2\le t \le \min \{cd,c\sqrt {\frac {n}{\log ^3n}}\}$.
$2\le t \le \min \{cd,c\sqrt {\frac {n}{\log ^3n}}\}$.(iii) For every
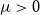 $\mu \gt 0$, there are constants
$\mu \gt 0$, there are constants 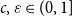 $c,\varepsilon \in (0,1]$ and
$c,\varepsilon \in (0,1]$ and 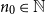 $n_0\in \mathbb N$ such that, whenever
$n_0\in \mathbb N$ such that, whenever  $n\ge n_0$, every
$n\ge n_0$, every  $n$-vertex graph with minimum degree at least
$n$-vertex graph with minimum degree at least 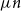 $\mu n$ and no bipartite holes of size
$\mu n$ and no bipartite holes of size 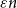 $\varepsilon n$ contains a spanning nearly balanced subdivision of
$\varepsilon n$ contains a spanning nearly balanced subdivision of 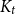 $K_t$ for all
$K_t$ for all 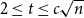 $2\le t \le c\sqrt {n}$.
$2\le t \le c\sqrt {n}$.
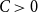
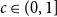
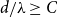
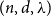
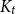
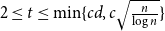
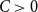
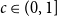
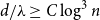
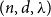
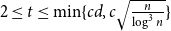
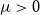
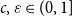
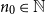


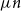
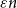
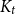
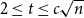
On the local convergence of integer-valued Lipschitz functions on regular trees
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 06 July 2026, pp. 1-33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study random integer-valued Lipschitz functions on regular trees. It was shown by Peled, Samotij, and Yehudayoff [22] that such functions are localized; however, finer questions about the structure of Gibbs measures remain unanswered. Our main result is that the weak limit of a uniformly chosen 1-Lipschitz function with 0 boundary condition on a
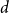 $d$-ary tree of height
$d$-ary tree of height  $n$ exists as
$n$ exists as 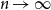 $n \to \infty$ if
$n \to \infty$ if 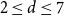 $2 \le d \le 7$, but not if
$2 \le d \le 7$, but not if 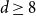 $d \ge 8$, thereby partially answering a question posed by Peled, Samotij and Yehudayoff. For large
$d \ge 8$, thereby partially answering a question posed by Peled, Samotij and Yehudayoff. For large 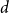 $d$, the value at the root alternates between being almost entirely concentrated on 0 for even
$d$, the value at the root alternates between being almost entirely concentrated on 0 for even  $n$ and being roughly uniform on
$n$ and being roughly uniform on 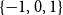 $\{-1,0,1\}$ for odd
$\{-1,0,1\}$ for odd  $n$, leading to different limits as
$n$, leading to different limits as  $n$ approaches infinity along evens or odds. For
$n$ approaches infinity along evens or odds. For 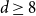 $d \ge 8$, the essence of this phenomenon is preserved, which obstructs the convergence. For
$d \ge 8$, the essence of this phenomenon is preserved, which obstructs the convergence. For 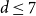 $d \le 7$, this phenomenon ceases to exist, and the law of the value at the root loses its connection with the parity of
$d \le 7$, this phenomenon ceases to exist, and the law of the value at the root loses its connection with the parity of  $n$. Along the way, we also obtain an alternative proof of localization. The key idea is a fixed point convergence result for a related operator on
$n$. Along the way, we also obtain an alternative proof of localization. The key idea is a fixed point convergence result for a related operator on 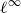 $\ell ^\infty$ and a procedure to show that the iterations get into a ‘basin of attraction’ of the fixed point. We also prove some accompanying analogous ‘even-odd phenomenon’ type results about
$\ell ^\infty$ and a procedure to show that the iterations get into a ‘basin of attraction’ of the fixed point. We also prove some accompanying analogous ‘even-odd phenomenon’ type results about 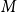 $M$-Lipschitz functions on general non-amenable graphs with high enough expansion (this includes for example the large
$M$-Lipschitz functions on general non-amenable graphs with high enough expansion (this includes for example the large 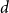 $d$ case for regular trees). We also prove a convergence result for 1-Lipschitz functions with
$d$ case for regular trees). We also prove a convergence result for 1-Lipschitz functions with 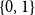 $\{0,1\}$ boundary condition. This last result relies on an absolute value FKG for uniform 1-Lipschitz functions when shifted by
$\{0,1\}$ boundary condition. This last result relies on an absolute value FKG for uniform 1-Lipschitz functions when shifted by 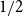 $1/2$.
$1/2$.
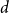

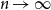
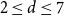
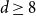

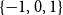


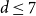

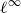
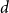
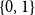
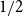
Recommendations for conducting ethical network research
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 02 July 2026, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How safe are women? Constructing a cross-national index on the foundations of women’s safety
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 29 June 2026, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiological Investigation of a Large Trichinellosis Outbreak in Lebanon, October 2023 – February 2024
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 29 June 2026, pp. 1-30
-
- Article
-
- You have access
- Open access
- Export citation
Pandemic preparedness: potential of routine general practice data for infectious disease early signal detection
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 29 June 2026, pp. 1-32
-
- Article
-
- You have access
- Open access
- Export citation

A Course in Interacting Particle Systems
-
- Published online:
- 26 June 2026
- Print publication:
- 23 July 2026
Using forensic autopsy data to estimate the age-specific infection fatality risk of COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 26 June 2026, e96
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
