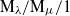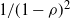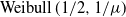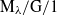Refine search
Actions for selected content:
53140 results in Statistics and Probability
6 - Developing a Theory of Status Effects
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp 66-91
-
- Chapter
- Export citation
3 - Logical Sentences and Truth
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp 17-26
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp iv-iv
-
- Chapter
- Export citation
1 - What Is a Theory?
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp 1-5
-
- Chapter
- Export citation
Hypothesis testing for community structure in temporal networks using e-values
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 18 June 2026, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Index
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp 119-122
-
- Chapter
- Export citation
Evaluating the financial sustainability of English NHS trusts: a research proposal to the Big Pitch Event 2026
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 18 June 2026, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
8 - Avoiding Common Missteps
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp 106-118
-
- Chapter
- Export citation
Aggregating heavy-tailed random vectors: from finite sums to lévy processes
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 18 June 2026, pp. 1-44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The tail behavior of aggregates of heavy-tailed random vectors is known to be determined by the so-called principle of ‘one large jump’, be it for finite sums, random sums, or Lévy processes. We establish that, in fact, a more general principle is at play. Assuming that the random vectors are multivariate regularly varying on various subcones of the positive orthant
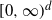 $[0,\infty)^d$, first we show that their aggregates are also multivariate regularly varying on these subcones. This allows us to approximate certain tail probabilities rendered asymptotically negligible under classical regular variation. Second, we discover that depending on the structure of a particular tail event, the tail behavior of the aggregates may be characterized by more than a single large jump. Finally, we illustrate a similar phenomenon for regularly varying multivariate Lévy processes, establishing as well a relationship between regular variation of a multivariate Lévy process and multivariate regular variation of its Lévy measure on different subcones. The applicability of these results in financial and insurance risk management is discussed.
$[0,\infty)^d$, first we show that their aggregates are also multivariate regularly varying on these subcones. This allows us to approximate certain tail probabilities rendered asymptotically negligible under classical regular variation. Second, we discover that depending on the structure of a particular tail event, the tail behavior of the aggregates may be characterized by more than a single large jump. Finally, we illustrate a similar phenomenon for regularly varying multivariate Lévy processes, establishing as well a relationship between regular variation of a multivariate Lévy process and multivariate regular variation of its Lévy measure on different subcones. The applicability of these results in financial and insurance risk management is discussed.
Contents
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp v-viii
-
- Chapter
- Export citation
Preface: Do We Need Theories?
-
- Book:
- Developing Theories in the Social Sciences
- Published online:
- 27 May 2026
- Print publication:
- 18 June 2026, pp xi-xviii
-
- Chapter
- Export citation
A hierarchical Bayesian approach for time-varying (possible multiple setups) finite element model updating
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 17 June 2026, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Behavioural economics for insurance nudges: quantifying the actuarial value of prevention interventions
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 17 June 2026, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stackelberg equilibria in monopoly insurance markets with probability weighting
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 16 June 2026, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A two-generation model with altruism for reverse mortgage demand
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA , First View
- Published online by Cambridge University Press:
- 16 June 2026, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The number of connected components in sub-critical random graph processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 16 June 2026, pp. 1-13
-
- Article
-
- You have access
- HTML
- Export citation
An ergodic theorem for the maximum of branching Brownian motion with absorption
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 16 June 2026, pp. 1-14
-
- Article
-
- You have access
- HTML
- Export citation
Spherical latent space models for social networks: Geometry-aware inference and comparison across latent geometries
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 15 June 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Results from an enhanced surveillance study of laboratory-confirmed acute Lyme disease cases in England between 1 April 2023 and 31 March 2024
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 15 June 2026, e87
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The overlapping time distribution in the M/M/1 queue
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 15 June 2026, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we analyze the distribution of the total overlapping time spent with other customers in the
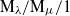 $\mathrm{M}_\lambda/\mathrm{M}_\mu/1$ queue with First-Come First-Served service discipline. We show that the Laplace–Stieltjes transform of the overlapping time reduces to an incomplete gamma function representation. We also calculate the transform of the joint distribution of the overlapping time and the number of overlaps. In addition, we prove a heavy-traffic limit for the total overlapping time with scaling
$\mathrm{M}_\lambda/\mathrm{M}_\mu/1$ queue with First-Come First-Served service discipline. We show that the Laplace–Stieltjes transform of the overlapping time reduces to an incomplete gamma function representation. We also calculate the transform of the joint distribution of the overlapping time and the number of overlaps. In addition, we prove a heavy-traffic limit for the total overlapping time with scaling 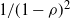 $1/(1-\rho)^2$ to a
$1/(1-\rho)^2$ to a 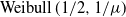 $\operatorname{Weibull}(1/2,1/\mu)$ random variable. Finally, for the
$\operatorname{Weibull}(1/2,1/\mu)$ random variable. Finally, for the 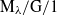 $\mathrm{M}_{\lambda}/\mathrm{G}/1$ case, we derive the first two moments of the overlapping time.
$\mathrm{M}_{\lambda}/\mathrm{G}/1$ case, we derive the first two moments of the overlapping time.