Refine search
Actions for selected content:
53140 results in Statistics and Probability
Published Salmonella risk assessment model contains major errors and inconsistencies – ERRATUM
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 04 June 2026, e74
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Classification
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 117-138
-
- Chapter
- Export citation
Data Sources
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 200-201
-
- Chapter
- Export citation
Trees and treelike structures in dense digraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 04 June 2026, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that every oriented tree on
 $n$ vertices with bounded maximum degree appears as a spanning subdigraph of every directed graph on
$n$ vertices with bounded maximum degree appears as a spanning subdigraph of every directed graph on  $n$ vertices with minimum semidegree at least
$n$ vertices with minimum semidegree at least 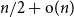 $n/2+{\mathrm{o}}(n)$. This can be seen as a directed graph analogue of a well-known theorem of Komlós, Sárközy, and Szemerédi. Our result for trees follows from a more general result, allowing the embedding of arbitrary orientations of a much wider class of spanning ‘tree-like’ structures, such as collections of at most
$n/2+{\mathrm{o}}(n)$. This can be seen as a directed graph analogue of a well-known theorem of Komlós, Sárközy, and Szemerédi. Our result for trees follows from a more general result, allowing the embedding of arbitrary orientations of a much wider class of spanning ‘tree-like’ structures, such as collections of at most 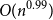 $O(n^{0.99})$ pairwise vertex-disjoint cycles and subdivisions of graphs
$O(n^{0.99})$ pairwise vertex-disjoint cycles and subdivisions of graphs 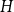 $H$ with
$H$ with 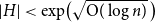 $|H|\lt \exp \bigl (\sqrt {\textrm {O}(\log n)}\,\bigr )$ in which each edge is subdivided at least once.
$|H|\lt \exp \bigl (\sqrt {\textrm {O}(\log n)}\,\bigr )$ in which each edge is subdivided at least once.


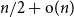
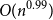
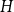
4 - High-Dimensional Linear Regression
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 56-65
-
- Chapter
- Export citation
11 - Causal Inference
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 147-172
-
- Chapter
- Export citation
10 - Prediction Sets and Conformal Inference
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 139-146
-
- Chapter
- Export citation
-
Summary
Regression and classification are used to produce a prediction
of an outcome Y. In many cases, we will also want a prediction set C that contains Y with probability
6 - Univariate Nonparametric Regression
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 75-98
-
- Chapter
- Export citation
-
Summary
In this chapter, we discuss nonparametric regression, which does not assume that the regression function
1 - Introduction
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 1-5
-
- Chapter
-
- You have access
- Export citation

Blockchain adoption in emerging markets: a systematic review of factors and perceived impacts
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 02 June 2026, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Solvability of a class of absorption problems with optimal operational scale and withdrawal control
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 02 June 2026, pp. 1-54
-
- Article
-
- You have access
- HTML
- Export citation
Jurimetrics and artificial intelligence for Indonesian tax court decisions: towards an integrated decision support system
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 02 June 2026, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Nonlinear system identification for model-based control of waked wind turbines
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 01 June 2026, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This work presents a nonlinear system identification framework for modeling the power extraction dynamics of wind turbines, including both freestream and waked conditions. The approach models turbine dynamics using data-driven power coefficient maps expressed as combinations of compact radial basis functions and polynomial bases, parameterized in terms of tip-speed ratio and upstream conditions. These surrogate models are embedded in a first-order dynamic system suitable for model-based control. Experimental validation is carried out in two wind tunnel configurations: a low-turbulence tandem setup and a high-turbulence wind farm scenario. In the tandem case, the identified model is integrated into an adapted $ K{\omega}^2 $
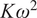 controller, resulting in improved tip-speed ratio tracking and power stability compared to steady-state models, while also outperforming the BEM-based model in the present low Reynolds number setting, where aerodynamic predictions are more uncertain. In the wind farm scenario, the model captures the statistical behavior of the turbines despite unresolved turbulence. The proposed method enables interpretable, adaptive control across a range of operating conditions without relying on black-box learning strategies.
controller, resulting in improved tip-speed ratio tracking and power stability compared to steady-state models, while also outperforming the BEM-based model in the present low Reynolds number setting, where aerodynamic predictions are more uncertain. In the wind farm scenario, the model captures the statistical behavior of the turbines despite unresolved turbulence. The proposed method enables interpretable, adaptive control across a range of operating conditions without relying on black-box learning strategies.
First-passage times of increasing Markov processes and classes of life distributions
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 01 June 2026, pp. 1-25
-
- Article
-
- You have access
- HTML
- Export citation
Public vs private provisioning of AI tools in high-stakes contexts: experimental evidence from technology and law students in India
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 01 June 2026, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Perceived fairness in networks
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 29 May 2026, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Beyond automation: toward a hybrid human-AI architecture for scalable, context-aware, and sustainable global data benchmarking
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 29 May 2026, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discrete-time joint signature and associated properties
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 29 May 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Shift from a Zero-COVID strategy to a New-normal strategy for controlling SARS-COV-2 infections in Vietnam – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 154 / 2026
- Published online by Cambridge University Press:
- 29 May 2026, e69
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
New stationarity conditions for IARCH processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 May 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
