Refine search
Actions for selected content:
52675 results in Statistics and Probability
Fostering trustworthy data sharing: Establishing data foundations in practice
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 05 February 2021, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Immunogenicity and safety of a quadrivalent meningococcal tetanus toxoid-conjugate vaccine (MenACYW-TT) vs. a licensed quadrivalent meningococcal tetanus toxoid-conjugate vaccine in meningococcal vaccine-naïve and meningococcal C conjugate vaccine-primed toddlers: a phase III randomised study
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 05 February 2021, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Legal Informatics
-
- Published online:
- 04 February 2021
- Print publication:
- 18 February 2021
Physical seed dormancy in Abrus precatorious (Ratti): a scientific validation of indigenous technique
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 04 February 2021, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CHARACTERIZATION OF THE TAIL BEHAVIOR OF A CLASS OF BEKK PROCESSES: A STOCHASTIC RECURRENCE EQUATION APPROACH
-
- Journal:
- Econometric Theory / Volume 38 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 04 February 2021, pp. 1-34
-
- Article
- Export citation
-
We consider conditions for strict stationarity and ergodicity of a class of multivariate BEKK processes
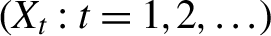 $(X_t : t=1,2,\ldots )$ and study the tail behavior of the associated stationary distributions. Specifically, we consider a class of BEKK-ARCH processes where the innovations are assumed to be Gaussian and a finite number of lagged
$(X_t : t=1,2,\ldots )$ and study the tail behavior of the associated stationary distributions. Specifically, we consider a class of BEKK-ARCH processes where the innovations are assumed to be Gaussian and a finite number of lagged 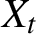 $X_t$’s may load into the conditional covariance matrix of
$X_t$’s may load into the conditional covariance matrix of 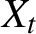 $X_t$. By exploiting that the processes have multivariate stochastic recurrence equation representations, we show the existence of strictly stationary solutions under mild conditions, where only a fractional moment of
$X_t$. By exploiting that the processes have multivariate stochastic recurrence equation representations, we show the existence of strictly stationary solutions under mild conditions, where only a fractional moment of 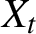 $X_t$ may be finite. Moreover, we show that each component of the BEKK processes is regularly varying with some tail index. In general, the tail index differs along the components, which contrasts with most of the existing literature on the tail behavior of multivariate GARCH processes. Lastly, in an empirical illustration of our theoretical results, we quantify the model-implied tail index of the daily returns on two cryptocurrencies.
$X_t$ may be finite. Moreover, we show that each component of the BEKK processes is regularly varying with some tail index. In general, the tail index differs along the components, which contrasts with most of the existing literature on the tail behavior of multivariate GARCH processes. Lastly, in an empirical illustration of our theoretical results, we quantify the model-implied tail index of the daily returns on two cryptocurrencies.
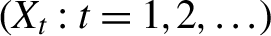
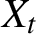
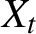
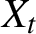
Oyster growth across a salinity gradient in a shallow, subtropical Gulf of Mexico estuary
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 04 February 2021, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
High seroprevalence of COVID-19 infection in a large slum in South India; what does it tell us about managing a pandemic and beyond?
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 04 February 2021, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NWS volume 9 issue 1 Cover and Back matter
-
- Journal:
- Network Science / Volume 9 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 04 February 2021, pp. b1-b2
-
- Article
-
- You have access
- Export citation
ITERATIONS OF DEPENDENT RANDOM MAPS AND EXOGENEITY IN NONLINEAR DYNAMICS
-
- Journal:
- Econometric Theory / Volume 37 / Issue 6 / December 2021
- Published online by Cambridge University Press:
- 04 February 2021, pp. 1135-1172
-
- Article
- Export citation
NWS volume 9 issue 1 Cover and Front matter
-
- Journal:
- Network Science / Volume 9 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 04 February 2021, pp. f1-f3
-
- Article
-
- You have access
- Export citation
The effect of Y on the microstructure and mechanical performance of an Mg-Al-Y casting alloy
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 03 February 2021, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Challenge of forecasting demand of medical resources and supplies during a pandemic: A comparative evaluation of three surge calculators for COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 03 February 2021, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifying the function of methylated genes in Alzheimer’s disease to determine epigenetic signatures: a comprehensive bioinformatics analysis
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 02 February 2021, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mortality models incorporating long memory for life table estimation: a comprehensive analysis
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 3 / November 2021
- Published online by Cambridge University Press:
- 02 February 2021, pp. 567-604
-
- Article
- Export citation
A DOUBLE COMMON FACTOR MODEL FOR MORTALITY PROJECTION USING BEST-PERFORMANCE MORTALITY RATES AS REFERENCE
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 01 February 2021, pp. 349-374
- Print publication:
- May 2021
-
- Article
- Export citation
Diversity of SARS-CoV-2 isolates driven by pressure and health index
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 01 February 2021, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TEMPERED PARETO-TYPE MODELLING USING WEIBULL DISTRIBUTIONS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 01 February 2021, pp. 509-538
- Print publication:
- May 2021
-
- Article
-
- You have access
- Open access
- Export citation
On the Erdős–Sós conjecture for trees with bounded degree
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 5 / September 2021
- Published online by Cambridge University Press:
- 01 February 2021, pp. 741-761
-
- Article
- Export citation
Comparative characterisation of human and ovine non-aureus staphylococci isolated in Sardinia (Italy) for antimicrobial susceptibility profiles and resistance genes
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 29 January 2021, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiology of COVID-19 in Northern Ireland, 26 February 2020–26 April 2020
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 29 January 2021, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
