Refine search
Actions for selected content:
52675 results in Statistics and Probability
Subcutaneous emphysema and pneumomediastinum in patients with COVID-19 disease; case series from a tertiary care hospital in Pakistan
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 20 January 2021, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Full rainbow matchings in graphs and hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 5 / September 2021
- Published online by Cambridge University Press:
- 20 January 2021, pp. 762-780
-
- Article
- Export citation
-
Let G be a simple graph that is properly edge-coloured with m colours and let
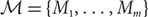 \[\mathcal{M} = \{ {M_1},...,{M_m}\} \] be the set of m matchings induced by the colours in G. Suppose that
\[\mathcal{M} = \{ {M_1},...,{M_m}\} \] be the set of m matchings induced by the colours in G. Suppose that 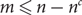 \[m \leqslant n - {n^c}\], where
\[m \leqslant n - {n^c}\], where 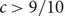 \[c > 9/10\], and every matching in
\[c > 9/10\], and every matching in 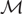 \[\mathcal{M}\] has size n. Then G contains a full rainbow matching, i.e. a matching that contains exactly one edge from Mi for each
\[\mathcal{M}\] has size n. Then G contains a full rainbow matching, i.e. a matching that contains exactly one edge from Mi for each 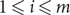 \[1 \leqslant i \leqslant m\]. This answers an open problem of Pokrovskiy and gives an affirmative answer to a generalization of a special case of a conjecture of Aharoni and Berger. Related results are also found for multigraphs with edges of bounded multiplicity, and for hypergraphs.
\[1 \leqslant i \leqslant m\]. This answers an open problem of Pokrovskiy and gives an affirmative answer to a generalization of a special case of a conjecture of Aharoni and Berger. Related results are also found for multigraphs with edges of bounded multiplicity, and for hypergraphs.Finally, we provide counterexamples to several conjectures on full rainbow matchings made by Aharoni and Berger.
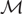
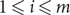
Surviving COVID-19 in Bergamo province: a post-acute outpatient re-evaluation
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 19 January 2021, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PES volume 35 issue 1 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 18 January 2021, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Influences of reopening businesses and social venues: COVID-19 incidence rate in East Texas county
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 18 January 2021, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Persistently high SARS-CoV-2 positivity rate and incidence for Hispanic/Latinos during state reopening in an urban setting: a retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 18 January 2021, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PES volume 35 issue 1 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 18 January 2021, pp. f1-f2
-
- Article
-
- You have access
- Export citation
How to improve infectious disease prediction by integrating environmental data: an application of a novel ensemble analysis strategy to predict HFMD
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 15 January 2021, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Bayesian Econometric Methods
-
- Published online:
- 14 January 2021
- Print publication:
- 15 August 2019
-
- Textbook
- Export citation
ON EXTROPY PROPERTIES AND DISCRIMINATION INFORMATION OF DIFFERENT STRATIFIED SAMPLING SCHEMES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 14 January 2021, pp. 644-659
-
- Article
- Export citation
Why does the spread of COVID-19 vary greatly in different countries? Revealing the efficacy of face masks in epidemic prevention
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 14 January 2021, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Impact of PD-1 gene polymorphism and its interaction with tea drinking on susceptibility to tuberculosis
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 13 January 2021, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON SMOOTH TESTS FOR THE EQUALITY OF DISTRIBUTIONS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 12 January 2021, pp. 194-208
-
- Article
- Export citation
INSTRUMENTAL VARIABLE ESTIMATION OF STRUCTURAL VAR MODELS ROBUST TO POSSIBLE NONSTATIONARITY
-
- Journal:
- Econometric Theory / Volume 38 / Issue 5 / October 2022
- Published online by Cambridge University Press:
- 11 January 2021, pp. 845-874
-
- Article
- Export citation
LEAST SQUARES ESTIMATION FOR NONLINEAR REGRESSION MODELS WITH HETEROSCEDASTICITY
-
- Journal:
- Econometric Theory / Volume 37 / Issue 6 / December 2021
- Published online by Cambridge University Press:
- 11 January 2021, pp. 1267-1289
-
- Article
- Export citation
Rapid shortening of survival duration in early fatal cases of COVID-19, Wuhan, China
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 11 January 2021, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SARS-CoV-2 viral RNA load dynamics in the nasopharynx of infected children
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 11 January 2021, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON MARKOVIAN QUEUES WITH SINGLE WORKING VACATION AND BERNOULLI INTERRUPTIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 11 January 2021, pp. 616-643
-
- Article
- Export citation
ON THE REPRESENTATION OF THE NESTED LOGIT MODEL
-
- Journal:
- Econometric Theory / Volume 38 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 11 January 2021, pp. 370-380
-
- Article
- Export citation
Non-specific blood tests as proxies for COVID-19 hospitalisation: are there plausible associations after excluding noisy predictors?
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 11 January 2021, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
