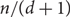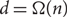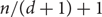Refine search
Actions for selected content:
52675 results in Statistics and Probability
TAIL CONDITIONAL EXPECTATIONS FOR GENERALIZED SKEW-ELLIPTICAL DISTRIBUTIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 05 January 2021, pp. 500-513
-
- Article
- Export citation
ASB volume 51 issue 1 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 22 January 2021, pp. b1-b2
- Print publication:
- January 2021
-
- Article
-
- You have access
- Export citation
ASB volume 51 issue 1 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 22 January 2021, pp. f1-f2
- Print publication:
- January 2021
-
- Article
-
- You have access
- Export citation
Physics-constrained local convexity data-driven modeling of anisotropic nonlinear elastic solids
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 30 December 2020, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Anomaly detection in a fleet of industrial assets with hierarchical statistical modeling
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 30 December 2020, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Digital twin of an urban-integrated hydroponic farm
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 29 December 2020, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Forecasting the final disease size: comparing calibrations of Bertalanffy–Pütter models
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 December 2020, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Temperature and humidity associated with increases in tuberculosis notifications: a time-series study in Hong Kong
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 December 2020, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Correlation of population mortality of COVID-19 and testing coverage: a comparison among 36 OECD countries
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 December 2020, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modelling pool testing for SARS-CoV-2: addressing heterogeneity in populations
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 December 2020, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Combined tests with Xpert MTB/RIF assay with bronchoalveolar lavage fluid increasing the diagnostic performance of smear-negative pulmonary tuberculosis in Eastern China
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 December 2020, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Species identification and antimicrobial susceptibility testing of non-tuberculous mycobacteria isolated in Chongqing, Southwest China
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 December 2020, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Statistics for the Social Sciences
- A General Linear Model Approach
-
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020
-
- Textbook
- Export citation
Roughness-induced vehicle energy dissipation from crowdsourced smartphone measurements through random vibration theory
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 23 December 2020, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COPULA REPRESENTATIONS FOR THE SUM OF DEPENDENT RISKS: MODELS AND COMPARISONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 23 December 2020, pp. 320-340
-
- Article
- Export citation
How useful are survey data for analyzing immigration policy?
-
- Journal:
- Data & Policy / Volume 2 / 2020
- Published online by Cambridge University Press:
- 23 December 2020, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A meta-analysis of the association between obesity and COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 22 December 2020, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trusts, co-ops, and crowd workers: Could we include crowd data workers as stakeholders in data trust design?
-
- Journal:
- Data & Policy / Volume 2 / 2020
- Published online by Cambridge University Press:
- 22 December 2020, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CLOUD STORAGE FACILITY AS A FLUID QUEUE CONTROLLED BY MARKOVIAN QUEUE
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 21 December 2020, pp. 237-253
-
- Article
- Export citation
Cycle partitions of regular graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 18 December 2020, pp. 526-549
-
- Article
- Export citation
-
Magnant and Martin conjectured that the vertex set of any d-regular graph G on n vertices can be partitioned into
 $n / (d+1)$ paths (there exists a simple construction showing that this bound would be best possible). We prove this conjecture when
$n / (d+1)$ paths (there exists a simple construction showing that this bound would be best possible). We prove this conjecture when 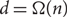 $d = \Omega(n)$, improving a result of Han, who showed that in this range almost all vertices of G can be covered by
$d = \Omega(n)$, improving a result of Han, who showed that in this range almost all vertices of G can be covered by 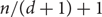 $n / (d+1) + 1$ vertex-disjoint paths. In fact our proof gives a partition of V(G) into cycles. We also show that, if $d = \Omega(n)$ and G is bipartite, then V(G) can be partitioned into n/(2d) paths (this bound is tight for bipartite graphs).
$n / (d+1) + 1$ vertex-disjoint paths. In fact our proof gives a partition of V(G) into cycles. We also show that, if $d = \Omega(n)$ and G is bipartite, then V(G) can be partitioned into n/(2d) paths (this bound is tight for bipartite graphs).