Refine search
Actions for selected content:
52675 results in Statistics and Probability
2 - Levels of Data
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 22-35
-
- Chapter
- Export citation
4 - Visual Models
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 62-103
-
- Chapter
- Export citation
3 - Langevin and Fokker–Planck Equations and Their Applications
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 39-66
-
- Chapter
- Export citation
Examples
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp xvi-xx
-
- Chapter
- Export citation
8 - Random Matrix Theory
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 145-183
-
- Chapter
- Export citation
14 - Chi-Squared Test
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 410-455
-
- Chapter
- Export citation
Contents
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp v-vii
-
- Chapter
- Export citation
The effect of hemicylindrical disruptors on the cell free layer thickness in animal blood flows inside microchannels
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 17 December 2020, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Counting Hamilton cycles in Dirac hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 17 December 2020, pp. 631-653
-
- Article
- Export citation
-
A tight Hamilton cycle in a k-uniform hypergraph (k-graph) G is a cyclic ordering of the vertices of G such that every set of k consecutive vertices in the ordering forms an edge. Rödl, Ruciński and Szemerédi proved that for
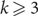 $k\ge 3$, every k-graph on n vertices with minimum codegree at least
$k\ge 3$, every k-graph on n vertices with minimum codegree at least  $n/2+o(n)$ contains a tight Hamilton cycle. We show that the number of tight Hamilton cycles in such k-graphs is
$n/2+o(n)$ contains a tight Hamilton cycle. We show that the number of tight Hamilton cycles in such k-graphs is 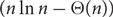 ${\exp(n\ln n-\Theta(n))}$. As a corollary, we obtain a similar estimate on the number of Hamilton
${\exp(n\ln n-\Theta(n))}$. As a corollary, we obtain a similar estimate on the number of Hamilton 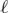 ${\ell}$-cycles in such k-graphs for all
${\ell}$-cycles in such k-graphs for all 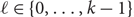 ${\ell\in\{0,\ldots,k-1\}}$, which makes progress on a question of Ferber, Krivelevich and Sudakov.
${\ell\in\{0,\ldots,k-1\}}$, which makes progress on a question of Ferber, Krivelevich and Sudakov.
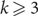

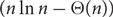
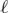
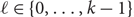
1 - Statistics and Models
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 1-21
-
- Chapter
- Export citation
Contents
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp vii-viii
-
- Chapter
- Export citation
Context-specific volume–delay curves by combining crowd-sourced traffic data with automated traffic counters: A case study for London
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 17 December 2020, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Appendix F - Notation, Notation. . .
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 222-224
-
- Chapter
- Export citation
References
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 225-231
-
- Chapter
- Export citation
2 - Random Walks
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 15-38
-
- Chapter
- Export citation
Appendix A5 - Critical Values for r
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 516-518
-
- Chapter
- Export citation
5 - Noise
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 81-95
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp i-iv
-
- Chapter
- Export citation
ADDRESSING IMBALANCED INSURANCE DATA THROUGH ZERO-INFLATED POISSON REGRESSION WITH BOOSTING
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 17 December 2020, pp. 27-55
- Print publication:
- January 2021
-
- Article
- Export citation
Glossary
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 521-536
-
- Chapter
- Export citation
