Refine search
Actions for selected content:
52383 results in Statistics and Probability
Mass gathering events and undetected transmission of SARS-CoV-2 in vulnerable populations leading to an outbreak with high case fatality ratio in the district of Tirschenreuth, Germany
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 October 2020, e252
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Covering and tiling hypergraphs with tight cycles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 13 October 2020, pp. 288-329
-
- Article
- Export citation
-
A k-uniform tight cycle
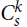 $C_s^k$ is a hypergraph on s > k vertices with a cyclic ordering such that every k consecutive vertices under this ordering form an edge. The pair (k, s) is admissible if gcd (k, s) = 1 or k / gcd (k,s) is even. We prove that if
$C_s^k$ is a hypergraph on s > k vertices with a cyclic ordering such that every k consecutive vertices under this ordering form an edge. The pair (k, s) is admissible if gcd (k, s) = 1 or k / gcd (k,s) is even. We prove that if 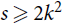 $s \ge 2{k^2}$ and H is a k-uniform hypergraph with minimum codegree at least (1/2 + o(1))|V(H)|, then every vertex is covered by a copy of
$s \ge 2{k^2}$ and H is a k-uniform hypergraph with minimum codegree at least (1/2 + o(1))|V(H)|, then every vertex is covered by a copy of 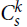 $C_s^k$. The bound is asymptotically sharp if (k, s) is admissible. Our main tool allows us to arbitrarily rearrange the order in which a tight path wraps around a complete k-partite k-uniform hypergraph, which may be of independent interest.
$C_s^k$. The bound is asymptotically sharp if (k, s) is admissible. Our main tool allows us to arbitrarily rearrange the order in which a tight path wraps around a complete k-partite k-uniform hypergraph, which may be of independent interest.For hypergraphs F and H, a perfect F-tiling in H is a spanning collection of vertex-disjoint copies of F. For
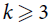 $k \ge 3$, there are currently only a handful of known F-tiling results when F is k-uniform but not k-partite. If s ≢ 0 mod k, then
$k \ge 3$, there are currently only a handful of known F-tiling results when F is k-uniform but not k-partite. If s ≢ 0 mod k, then 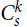 $C_s^k$ is not k-partite. Here we prove an F-tiling result for a family of non-k-partite k-uniform hypergraphs F. Namely, for
$C_s^k$ is not k-partite. Here we prove an F-tiling result for a family of non-k-partite k-uniform hypergraphs F. Namely, for 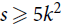 $s \ge 5{k^2}$, every k-uniform hypergraph H with minimum codegree at least (1/2 + 1/(2s) + o(1))|V(H)| has a perfect
$s \ge 5{k^2}$, every k-uniform hypergraph H with minimum codegree at least (1/2 + 1/(2s) + o(1))|V(H)| has a perfect 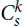 $C_s^k$-tiling. Moreover, the bound is asymptotically sharp if k is even and (k, s) is admissible.
$C_s^k$-tiling. Moreover, the bound is asymptotically sharp if k is even and (k, s) is admissible.
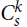
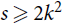
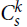
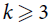
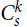
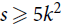
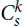
Tight Hamilton cycles in cherry-quasirandom 3-uniform hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 12 October 2020, pp. 412-443
-
- Article
-
- You have access
- Open access
- Export citation
-
We employ the absorbing-path method in order to prove two results regarding the emergence of tight Hamilton cycles in the so-called two-path or cherry-quasirandom 3-graphs.
Our first result asserts that for any fixed real α > 0, cherry-quasirandom 3-graphs of sufficiently large order n having minimum 2-degree at least α(n – 2) have a tight Hamilton cycle.
Our second result concerns the minimum 1-degree sufficient for such 3-graphs to have a tight Hamilton cycle. Roughly speaking, we prove that for every d, α > 0 satisfying d + α > 1, any sufficiently large n-vertex such 3-graph H of density d and minimum 1-degree at least
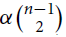 $\alpha \left({\matrix{{n - 1} \cr 2 \cr } } \right)$ has a tight Hamilton cycle.
$\alpha \left({\matrix{{n - 1} \cr 2 \cr } } \right)$ has a tight Hamilton cycle.
ASYMPTOTIC ANALYSIS OF PERES’ ALGORITHM FOR RANDOM NUMBER GENERATION
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 12 October 2020, pp. 341-356
-
- Article
- Export citation
-
von Neumann [(1951). Various techniques used in connection with random digits. National Bureau of Standards Applied Math Series 12: 36–38] introduced a simple algorithm for generating independent unbiased random bits by tossing a (possibly) biased coin with unknown bias. While his algorithm fails to attain the entropy bound, Peres [(1992). Iterating von Neumann's procedure for extracting random bits. The Annals of Statistics 20(1): 590–597] showed that the entropy bound can be attained asymptotically by iterating von Neumann's algorithm. Let $b(n,p)$
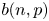 denote the expected number of unbiased bits generated when Peres’ algorithm is applied to an input sequence consisting of the outcomes of $n$
denote the expected number of unbiased bits generated when Peres’ algorithm is applied to an input sequence consisting of the outcomes of $n$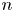 tosses of the coin with bias $p$
tosses of the coin with bias $p$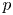 . With $p=1/2$
. With $p=1/2$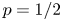 , the coin is unbiased and the input sequence consists of $n$
, the coin is unbiased and the input sequence consists of $n$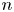 unbiased bits, so that $n-b(n,1/2)$
unbiased bits, so that $n-b(n,1/2)$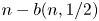 may be referred to as the cost incurred by Peres’ algorithm when not knowing $p=1/2$
may be referred to as the cost incurred by Peres’ algorithm when not knowing $p=1/2$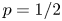 . We show that $\lim _{n\to \infty }\log [n-b(n,1/2)]/\log n =\theta =\log [(1+\sqrt {5})/2]$
. We show that $\lim _{n\to \infty }\log [n-b(n,1/2)]/\log n =\theta =\log [(1+\sqrt {5})/2]$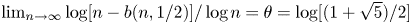 (where $\log$
(where $\log$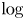 is the logarithm to base $2$
is the logarithm to base $2$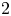 ), which together with limited numerical results suggests that $n-b(n,1/2)$
), which together with limited numerical results suggests that $n-b(n,1/2)$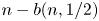 may be a regularly varying sequence of index $\theta$
may be a regularly varying sequence of index $\theta$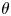 . (A positive sequence $\{L(n)\}$
. (A positive sequence $\{L(n)\}$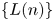 is said to be regularly varying of index $\theta$
is said to be regularly varying of index $\theta$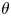 if $\lim _{n\to \infty }L(\lfloor \lambda n\rfloor )/L(n)=\lambda ^\theta$
if $\lim _{n\to \infty }L(\lfloor \lambda n\rfloor )/L(n)=\lambda ^\theta$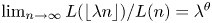 for all $\lambda > 0$
for all $\lambda > 0$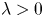 , where $\lfloor x\rfloor$
, where $\lfloor x\rfloor$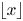 denotes the largest integer not exceeding $x$
denotes the largest integer not exceeding $x$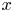 .) Some open problems on the asymptotic behavior of $nh(p)-b(n,p)$
.) Some open problems on the asymptotic behavior of $nh(p)-b(n,p)$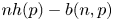 are briefly discussed where $h(p)=-p\log p- (1-p)\log (1-p)$
are briefly discussed where $h(p)=-p\log p- (1-p)\log (1-p)$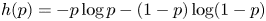 denotes the Shannon entropy of a random bit with bias $p$
denotes the Shannon entropy of a random bit with bias $p$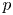 .
.
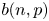
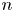
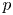
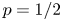
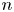
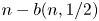
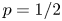
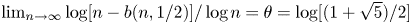
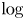
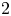
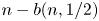
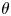
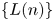
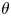
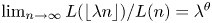
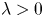
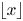
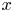
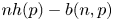
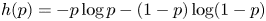
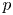
Sharp bounds for decomposing graphs into edges and triangles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 12 October 2020, pp. 271-287
-
- Article
-
- You have access
- Open access
- Export citation
-
For a real constant α, let
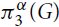 $\pi _3^\alpha (G)$ be the minimum of twice the number of K2’s plus α times the number of K3’s over all edge decompositions of G into copies of K2 and K3, where Kr denotes the complete graph on r vertices. Let
$\pi _3^\alpha (G)$ be the minimum of twice the number of K2’s plus α times the number of K3’s over all edge decompositions of G into copies of K2 and K3, where Kr denotes the complete graph on r vertices. Let 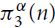 $\pi _3^\alpha (n)$ be the maximum of
$\pi _3^\alpha (n)$ be the maximum of 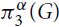 $\pi _3^\alpha (G)$ over all graphs G with n vertices.
$\pi _3^\alpha (G)$ over all graphs G with n vertices.The extremal function
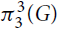 $\pi _3^3(n)$ was first studied by Győri and Tuza (Studia Sci. Math. Hungar. 22 (1987) 315–320). In recent progress on this problem, Král’, Lidický, Martins and Pehova (Combin. Probab. Comput. 28 (2019) 465–472) proved via flag algebras that
$\pi _3^3(n)$ was first studied by Győri and Tuza (Studia Sci. Math. Hungar. 22 (1987) 315–320). In recent progress on this problem, Král’, Lidický, Martins and Pehova (Combin. Probab. Comput. 28 (2019) 465–472) proved via flag algebras that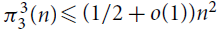 $\pi _3^3(n) \le (1/2 + o(1)){n^2}$. We extend their result by determining the exact value of
$\pi _3^3(n) \le (1/2 + o(1)){n^2}$. We extend their result by determining the exact value of 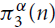 $\pi _3^\alpha (n)$ and the set of extremal graphs for all α and sufficiently large n. In particular, we show for α = 3 that Kn and the complete bipartite graph
$\pi _3^\alpha (n)$ and the set of extremal graphs for all α and sufficiently large n. In particular, we show for α = 3 that Kn and the complete bipartite graph 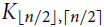 ${K_{\lfloor n/2 \rfloor,\lceil n/2 \rceil }}$ are the only possible extremal examples for large n.
${K_{\lfloor n/2 \rfloor,\lceil n/2 \rceil }}$ are the only possible extremal examples for large n.
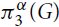
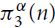
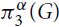
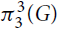
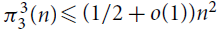
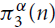
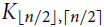
LAPLACE BOUNDS APPROXIMATION FOR AMERICAN OPTIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 09 October 2020, pp. 514-547
-
- Article
- Export citation
First observations of Polar Mesospheric Echoes at both 31 MHz and 53.5 MHz over Svalbard (78.2°N 15.1°E)
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 09 October 2020, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Candida albicans isolated from denture-related stomatitis in elderly patients: Antifungal susceptibility and production of virulence attributes
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 09 October 2020, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A predictive model for Covid-19 spread – with application to eight US states and how to end the pandemic
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 08 October 2020, e249
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ESTIMATION OF VOLATILITY FUNCTIONS IN JUMP DIFFUSIONS USING TRUNCATED BIPOWER INCREMENTS
-
- Journal:
- Econometric Theory / Volume 37 / Issue 5 / October 2021
- Published online by Cambridge University Press:
- 08 October 2020, pp. 926-958
-
- Article
- Export citation
NWS volume 8 issue 4 Cover and Front matter
-
- Journal:
- Network Science / Volume 8 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 07 October 2020, pp. f1-f3
-
- Article
-
- You have access
- Export citation
NWS volume 8 issue 4 Cover and Back matter
-
- Journal:
- Network Science / Volume 8 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 07 October 2020, pp. b1-b2
-
- Article
-
- You have access
- Export citation
The use of multiple hypothesis-generating methods in an outbreak investigation of Escherichia coli O121 infections associated with wheat flour, Canada 2016–2017
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 07 October 2020, e265
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toxoplasmosis and knowledge: what do the Italian women know about?
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 07 October 2020, e256
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SARS-CoV-2 transmission: a sociological review
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 07 October 2020, e242
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Quantitative Genetics
-
- Published online:
- 06 October 2020
- Print publication:
- 23 April 2020
-
- Textbook
- Export citation
Forecasting the epidemiological trends of COVID-19 prevalence and mortality using the advanced α-Sutte Indicator
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 05 October 2020, e236
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A meta-analytic evaluation of sex differences in meningococcal disease incidence rates in 10 countries
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 02 October 2020, e246
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Forage plant mixture type interacts with soil moisture to affect soil nutrient availability in the short term
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 02 October 2020, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Learning socio-organizational network structure in buildings with ambient sensing data
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 02 October 2020, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
