Refine search
Actions for selected content:
52383 results in Statistics and Probability
Finding tight Hamilton cycles in random hypergraphs faster
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 23 September 2020, pp. 239-257
-
- Article
- Export citation
-
In an r-uniform hypergraph on n vertices, a tight Hamilton cycle consists of n edges such that there exists a cyclic ordering of the vertices where the edges correspond to consecutive segments of r vertices. We provide a first deterministic polynomial-time algorithm, which finds a.a.s. tight Hamilton cycles in random r-uniform hypergraphs with edge probability at least C log3 n/n.
Our result partially answers a question of Dudek and Frieze, who proved that tight Hamilton cycles exist already for p = ω(1/n) for r = 3 and p = (e + o(1))/n for
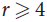 $r \ge 4$ using a second moment argument. Moreover our algorithm is superior to previous results of Allen, Böttcher, Kohayakawa and Person, and Nenadov and Škorić, in various ways: the algorithm of Allen et al. is a randomized polynomial-time algorithm working for edge probabilities
$r \ge 4$ using a second moment argument. Moreover our algorithm is superior to previous results of Allen, Böttcher, Kohayakawa and Person, and Nenadov and Škorić, in various ways: the algorithm of Allen et al. is a randomized polynomial-time algorithm working for edge probabilities 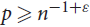 $p \ge {n^{ - 1 + \varepsilon}}$, while the algorithm of Nenadov and Škorić is a randomized quasipolynomial-time algorithm working for edge probabilities
$p \ge {n^{ - 1 + \varepsilon}}$, while the algorithm of Nenadov and Škorić is a randomized quasipolynomial-time algorithm working for edge probabilities 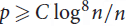 $p \ge C\mathop {\log }\nolimits^8 n/n$.
$p \ge C\mathop {\log }\nolimits^8 n/n$.
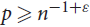
A model of COVID-19 transmission to understand the effectiveness of the containment measures: application to data from France
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 22 September 2020, e221
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The main objective of this paper is to address the following question: are the containment measures imposed by most of the world governments effective and sufficient to stop the epidemic of COVID-19 beyond the lock-down period? In this paper, we propose a mathematical model which allows us to investigate and analyse this problem. We show by means of the reproductive number, ${\cal R}_0$
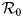 that the containment measures appear to have slowed the growth of the outbreak. Nevertheless, these measures remain only effective as long as a very large fraction of population, p, greater than the critical value $1-1/{\cal R}_0$
that the containment measures appear to have slowed the growth of the outbreak. Nevertheless, these measures remain only effective as long as a very large fraction of population, p, greater than the critical value $1-1/{\cal R}_0$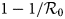 remains confined. Using French current data, we give some simulation experiments with five scenarios including: (i) the validation of model with p estimated to 93%, (ii) the study of the effectiveness of containment measures, (iii) the study of the effectiveness of the large-scale testing, (iv) the study of the social distancing and wearing masks measures and (v) the study taking into account the combination of the large-scale test of detection of infected individuals and the social distancing with linear progressive easing of restrictions. The latter scenario was shown to be effective at overcoming the outbreak if the transmission rate decreases to 75% and the number of tests of detection is multiplied by three. We also noticed that if the measures studied in our five scenarios are taken separately then the second wave might occur at least as far as the parameter values remain unchanged.
remains confined. Using French current data, we give some simulation experiments with five scenarios including: (i) the validation of model with p estimated to 93%, (ii) the study of the effectiveness of containment measures, (iii) the study of the effectiveness of the large-scale testing, (iv) the study of the social distancing and wearing masks measures and (v) the study taking into account the combination of the large-scale test of detection of infected individuals and the social distancing with linear progressive easing of restrictions. The latter scenario was shown to be effective at overcoming the outbreak if the transmission rate decreases to 75% and the number of tests of detection is multiplied by three. We also noticed that if the measures studied in our five scenarios are taken separately then the second wave might occur at least as far as the parameter values remain unchanged.
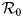
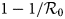
The COVID-19 pandemic: the public health reality
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 22 September 2020, e223
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
FACTORISABLE MULTITASK QUANTILE REGRESSION
-
- Journal:
- Econometric Theory / Volume 37 / Issue 4 / August 2021
- Published online by Cambridge University Press:
- 22 September 2020, pp. 794-816
-
- Article
- Export citation
Can elevated concentrations of ALT and AST predict the risk of ‘recurrence’ of COVID-19?
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 21 September 2020, e218
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predictions of coronavirus COVID-19 distinct cases in Pakistan through an artificial neural network
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 21 September 2020, e222
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Protecting healthcare workers from SARS-CoV-2 and other infections
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 21 September 2020, e217
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Public attitude towards quarantine during the COVID-19 outbreak
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 21 September 2020, e220
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROBUST TESTS FOR WHITE NOISE AND CROSS-CORRELATION
-
- Journal:
- Econometric Theory / Volume 38 / Issue 5 / October 2022
- Published online by Cambridge University Press:
- 21 September 2020, pp. 913-941
-
- Article
- Export citation
Practicality of Tricone Bit Wear Condition Assessment
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 21 September 2020, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Structured Dependence between Stochastic Processes
-
- Published online:
- 18 September 2020
- Print publication:
- 27 August 2020

Biostatistics with R
- An Introductory Guide for Field Biologists
-
- Published online:
- 18 September 2020
- Print publication:
- 30 July 2020
-
- Textbook
- Export citation
Safety considerations during return to work in the context of stable COVID-19 epidemic control: an analysis of health screening results of all returned staff from a hospital
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 18 September 2020, e214
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A comparative study of the cooling-rate effect on rock strength reduction after microwave irradiation
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 18 September 2020, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Response of macrobenthic communities to changes in water quality in a subtropical, microtidal estuary (Oso Bay, Texas)
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 18 September 2020, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evidence of Psychological Targeting but not Psychological Tailoring in Political Persuasion Around Brexit
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 18 September 2020, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
XPS and Electron Microscopy Study of Oxide-Scale Evolution on Ignition Resistant Mg-3Ca Alloy at Low and High Heating Rates
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 18 September 2020, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Processing Networks
- Fluid Models and Stability
-
- Published online:
- 17 September 2020
- Print publication:
- 15 October 2020
ASYMPTOTIC EXPANSION FOR THE TRANSITION DENSITIES OF STOCHASTIC DIFFERENTIAL EQUATIONS DRIVEN BY THE GAMMA PROCESSES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 17 September 2020, pp. 401-432
-
- Article
- Export citation
Epidemiological profile and transmission dynamics of COVID-19 in the Philippines
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 15 September 2020, e204
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
