Refine search
Actions for selected content:
52383 results in Statistics and Probability
Maker–Breaker percolation games I: crossing grids
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 15 September 2020, pp. 200-227
-
- Article
-
- You have access
- Open access
- Export citation
Spreading of SARS-CoV-2 in West Africa and assessment of risk factors
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 14 September 2020, e213
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ORDERINGS OF FINITE MIXTURE MODELS WITH LOCATION-SCALE DISTRIBUTED COMPONENTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 14 September 2020, pp. 461-481
-
- Article
- Export citation
Neisseria meningitidis carriage and risk factors among teenagers in Suizhou city in China
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 14 September 2020, e227
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ecologic association between influenza and COVID-19 mortality rates in European countries
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 11 September 2020, e209
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Learning to count: A deep learning framework for graphlet count estimation
-
- Journal:
- Network Science / Volume 9 / Issue S1 / October 2021
- Published online by Cambridge University Press:
- 11 September 2020, pp. S23-S60
-
- Article
- Export citation
Descriptive epidemiology of coronavirus disease 2019 in Nigeria, 27 February–6 June 2020
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 11 September 2020, e208
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The relationship between clinical outcomes and empirical antibiotic therapy in patients with community-onset Gram-negative bloodstream infections: a cohort study from a large teaching hospital
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 11 September 2020, e225
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Underreporting COVID-19: the curious case of the Indian subcontinent
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 11 September 2020, e207
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mortality forecasting using a Lexis-based state-space model
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 3 / November 2021
- Published online by Cambridge University Press:
- 11 September 2020, pp. 519-548
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association of TLR3 (rs3775291) and IL-10 (rs1800871) gene polymorphisms with susceptibility to Hepatitis B infection: A meta-analysis
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 11 September 2020, e228
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What is the resource footprint of a computer science department? Place, people, and Pedagogy
-
- Journal:
- Data & Policy / Volume 2 / 2020
- Published online by Cambridge University Press:
- 11 September 2020, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ratios of neutrophil-to-lymphocyte and platelet-to-lymphocyte predict all-cause mortality in inpatients with coronavirus disease 2019 (COVID-19): a retrospective cohort study in a single medical centre
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 09 September 2020, e211
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Triangle-degrees in graphs and tetrahedron coverings in 3-graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 09 September 2020, pp. 175-199
-
- Article
-
- You have access
- Open access
- Export citation
-
We investigate a covering problem in 3-uniform hypergraphs (3-graphs): Given a 3-graph F, what is c1(n, F), the least integer d such that if G is an n-vertex 3-graph with minimum vertex-degree
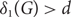 $\delta_1(G)>d$ then every vertex of G is contained in a copy of F in G?
$\delta_1(G)>d$ then every vertex of G is contained in a copy of F in G?We asymptotically determine c1(n, F) when F is the generalized triangle
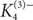 $K_4^{(3)-}$, and we give close to optimal bounds in the case where F is the tetrahedron
$K_4^{(3)-}$, and we give close to optimal bounds in the case where F is the tetrahedron 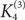 $K_4^{(3)}$ (the complete 3-graph on 4 vertices).
$K_4^{(3)}$ (the complete 3-graph on 4 vertices).This latter problem turns out to be a special instance of the following problem for graphs: Given an n-vertex graph G with
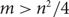 $m> n^2/4$ edges, what is the largest t such that some vertex in G must be contained in t triangles? We give upper bound constructions for this problem that we conjecture are asymptotically tight. We prove our conjecture for tripartite graphs, and use flag algebra computations to give some evidence of its truth in the general case.
$m> n^2/4$ edges, what is the largest t such that some vertex in G must be contained in t triangles? We give upper bound constructions for this problem that we conjecture are asymptotically tight. We prove our conjecture for tripartite graphs, and use flag algebra computations to give some evidence of its truth in the general case.
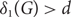
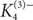
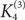
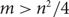
Machine learning approaches to identify and design low thermal conductivity oxides for thermoelectric applications
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 09 September 2020, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The search space for new thermoelectric oxides has been limited to the alloys of a few known systems, such as ZnO, SrTiO3, and CaMnO3. Notwithstanding the high power factor, their high thermal conductivity is a roadblock in achieving higher efficiency. In this paper, we apply machine learning (ML) models for discovering novel transition metal oxides with low lattice thermal conductivity (
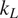 $ {k}_L $). A two-step process is proposed to address the problem of small datasets frequently encountered in material informatics. First, a gradient-boosted tree classifier is learnt to categorize unknown compounds into three categories of
$ {k}_L $). A two-step process is proposed to address the problem of small datasets frequently encountered in material informatics. First, a gradient-boosted tree classifier is learnt to categorize unknown compounds into three categories of 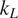 $ {k}_L $: low, medium, and high. In the second step, we fit regression models on the targeted class (i.e., low
$ {k}_L $: low, medium, and high. In the second step, we fit regression models on the targeted class (i.e., low 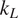 $ {k}_L $) to estimate
$ {k}_L $) to estimate 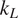 $ {k}_L $ with an
$ {k}_L $ with an 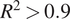 $ {R}^2>0.9 $. Gradient boosted tree model was also used to identify key material properties influencing classification of
$ {R}^2>0.9 $. Gradient boosted tree model was also used to identify key material properties influencing classification of 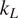 $ {k}_L $, namely lattice energy per atom, atom density, band gap, mass density, and ratio of oxygen by transition metal atoms. Only fundamental materials properties describing the crystal symmetry, compound chemistry, and interatomic bonding were used in the classification process, which can be readily used in the initial phases of materials design. The proposed two-step process addresses the problem of small datasets and improves the predictive accuracy. The ML approach adopted in the present work is generic in nature and can be combined with high-throughput computing for the rapid discovery of new materials for specific applications.
$ {k}_L $, namely lattice energy per atom, atom density, band gap, mass density, and ratio of oxygen by transition metal atoms. Only fundamental materials properties describing the crystal symmetry, compound chemistry, and interatomic bonding were used in the classification process, which can be readily used in the initial phases of materials design. The proposed two-step process addresses the problem of small datasets and improves the predictive accuracy. The ML approach adopted in the present work is generic in nature and can be combined with high-throughput computing for the rapid discovery of new materials for specific applications.
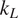
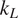
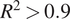
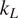
A review on Poisson, Cox, Hawkes, shot-noise Poisson and dynamic contagion process and their compound processes
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 3 / November 2021
- Published online by Cambridge University Press:
- 09 September 2020, pp. 623-644
-
- Article
- Export citation
Multifactorial disorders and polygenic risk scores: predicting common diseases and the possibility of adverse selection in life and protection insurance – CORRIGENDUM
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 3 / November 2021
- Published online by Cambridge University Press:
- 08 September 2020, p. 504
-
- Article
-
- You have access
- HTML
- Export citation
Hamiltonian Berge cycles in random hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 08 September 2020, pp. 228-238
-
- Article
- Export citation
-
In this note we study the emergence of Hamiltonian Berge cycles in random r-uniform hypergraphs. For
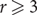 $r\geq 3$ we prove an optimal stopping time result that if edges are sequentially added to an initially empty r-graph, then as soon as the minimum degree is at least 2, the hypergraph with high probability has such a cycle. In particular, this determines the threshold probability for Berge Hamiltonicity of the Erdős–Rényi random r-graph, and we also show that the 2-out random r-graph with high probability has such a cycle. We obtain similar results for weak Berge cycles as well, thus resolving a conjecture of Poole.
$r\geq 3$ we prove an optimal stopping time result that if edges are sequentially added to an initially empty r-graph, then as soon as the minimum degree is at least 2, the hypergraph with high probability has such a cycle. In particular, this determines the threshold probability for Berge Hamiltonicity of the Erdős–Rényi random r-graph, and we also show that the 2-out random r-graph with high probability has such a cycle. We obtain similar results for weak Berge cycles as well, thus resolving a conjecture of Poole.
Bias correction methods for test-negative designs in the presence of misclassification
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 08 September 2020, e216
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Semi-supervised machine learning with word embedding for classification in price statistics
-
- Journal:
- Data & Policy / Volume 2 / 2020
- Published online by Cambridge University Press:
- 07 September 2020, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
