Refine search
Actions for selected content:
52675 results in Statistics and Probability
15 - Applying Statistics to Research and an Introduction to Advanced Statistical Methods
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 456-498
-
- Chapter
- Export citation
7 - Anomalous Diffusion
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 133-144
-
- Chapter
- Export citation
6 - Generalized Central Limit Theorem and Extreme Value Statistics
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 96-132
-
- Chapter
- Export citation
Appendix B - A Brief Linear Algebra Reminder, and Some Gaussian Integrals
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 211-213
-
- Chapter
- Export citation
Preface
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp ix-xiii
-
- Chapter
- Export citation
Appendices
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 499-520
-
- Chapter
- Export citation
Appendix E - Minimizing Functionals, the Divergence Theorem, and Saddle-Point Approximations
-
- Book:
- Thinking Probabilistically
- Published online:
- 15 December 2020
- Print publication:
- 17 December 2020, pp 220-221
-
- Chapter
- Export citation
Appendix A1 - z-Table
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 499-506
-
- Chapter
- Export citation
Extended-spectrum beta-lactamase Escherichia coli and Klebsiella pneumoniae urinary tract infections
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 17 December 2020, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Subject Index
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 580-590
-
- Chapter
- Export citation
5 - Linear Transformations and z-Scores
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 104-127
-
- Chapter
- Export citation
8 - One-Sample t-Tests
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 183-219
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp iv-iv
-
- Chapter
- Export citation
ESTIMATION OF THE KRONECKER COVARIANCE MODEL BY QUADRATIC FORM
-
- Journal:
- Econometric Theory / Volume 38 / Issue 5 / October 2022
- Published online by Cambridge University Press:
- 17 December 2020, pp. 1014-1067
-
- Article
- Export citation
-
We propose a new estimator, the quadratic form estimator, of the Kronecker product model for covariance matrices. We show that this estimator has good properties in the large dimensional case (i.e., the cross-sectional dimension n is large relative to the sample size T). In particular, the quadratic form estimator is consistent in a relative Frobenius norm sense provided
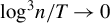 ${\log }^3n/T\to 0$. We obtain the limiting distributions of the Lagrange multiplier and Wald tests under both the null and local alternatives concerning the mean vector
${\log }^3n/T\to 0$. We obtain the limiting distributions of the Lagrange multiplier and Wald tests under both the null and local alternatives concerning the mean vector 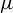 $\mu $. Testing linear restrictions of
$\mu $. Testing linear restrictions of 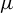 $\mu $ is also investigated. Finally, our methodology is shown to perform well in finite sample situations both when the Kronecker product model is true and when it is not true.
$\mu $ is also investigated. Finally, our methodology is shown to perform well in finite sample situations both when the Kronecker product model is true and when it is not true.
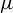
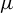
Dedication
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp v-vi
-
- Chapter
- Export citation
Acknowledgements
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp xiv-xv
-
- Chapter
- Export citation
13 - Regression
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 375-409
-
- Chapter
- Export citation
References
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 557-575
-
- Chapter
- Export citation
Appendix A2 - t-Table
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 507-509
-
- Chapter
- Export citation
7 - Null Hypothesis Statistical Significance Testing and z-Tests
-
- Book:
- Statistics for the Social Sciences
- Published online:
- 24 December 2020
- Print publication:
- 17 December 2020, pp 152-182
-
- Chapter
- Export citation
