Refine search
Actions for selected content:
52675 results in Statistics and Probability
From satisficing to artificing: The evolution of administrative decision-making in the age of the algorithm
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 29 January 2021, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Thrombocytopenia as a prognostic marker in COVID-19 patients: diagnostic test accuracy meta-analysis
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 29 January 2021, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The number of maximum primitive sets of integers
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 5 / September 2021
- Published online by Cambridge University Press:
- 28 January 2021, pp. 781-795
-
- Article
- Export citation
-
A set of integers is primitive if it does not contain an element dividing another. Let f(n) denote the number of maximum-size primitive subsets of {1,…,2n}. We prove that the limit α = limn→∞f(n)1/n exists. Furthermore, we present an algorithm approximating α with (1 + ε) multiplicative error in N(ε) steps, showing in particular that α ≈ 1.318. Our algorithm can be adapted to estimate the number of all primitive sets in {1,…,n} as well.
We address another related problem of Cameron and Erdős. They showed that the number of sets containing pairwise coprime integers in {1,…n} is between
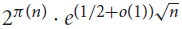 ${2^{\pi (n)}} \cdot {e^{(1/2 + o(1))\sqrt n }}$ and
${2^{\pi (n)}} \cdot {e^{(1/2 + o(1))\sqrt n }}$ and 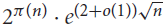 ${2^{\pi (n)}} \cdot {e^{(2 + o(1))\sqrt n }}$. We show that neither of these bounds is tight: there are in fact
${2^{\pi (n)}} \cdot {e^{(2 + o(1))\sqrt n }}$. We show that neither of these bounds is tight: there are in fact 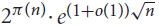 ${2^{\pi (n)}} \cdot {e^{(1 + o(1))\sqrt n }}$ such sets.
${2^{\pi (n)}} \cdot {e^{(1 + o(1))\sqrt n }}$ such sets.
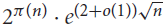
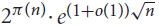
Urgent need for evaluation of point-of-care tests as an RT-PCR-sparing strategy for the diagnosis of Covid-19 in symptomatic patients
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 January 2021, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A scoping review of the detection, epidemiology and control of Cyclospora cayetanensis with an emphasis on produce, water and soil
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 January 2021, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Immunogenicity and safety of rapid scheme vaccination against tick-borne encephalitis in HIV-1 infected persons
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 January 2021, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal group testing
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 28 January 2021, pp. 811-848
-
- Article
- Export citation
Response to Letter to Editor by Zavascki A.P.: Urgent need for evaluating point-of-care tests as a RT-PCR-sparing strategy for the diagnosis of Covid-19 in symptomatic patients
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 January 2021, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Permutations with equal orders
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 5 / September 2021
- Published online by Cambridge University Press:
- 27 January 2021, pp. 800-810
-
- Article
- Export citation
-
Let
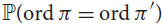 ${\mathbb{P}}(ord\pi = ord\pi ')$ be the probability that two independent, uniformly random permutations of [n] have the same order. Answering a question of Thibault Godin, we prove that
${\mathbb{P}}(ord\pi = ord\pi ')$ be the probability that two independent, uniformly random permutations of [n] have the same order. Answering a question of Thibault Godin, we prove that 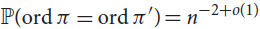 ${\mathbb{P}}(ord\pi = ord\pi ') = {n^{ - 2 + o(1)}}$ and that
${\mathbb{P}}(ord\pi = ord\pi ') = {n^{ - 2 + o(1)}}$ and that 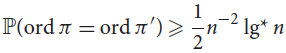 ${\mathbb{P}}(ord\pi = ord\pi ') \ge {1 \over 2}{n^{ - 2}}lg*n$ for infinitely many n. (Here lg*n is the height of the tallest tower of twos that is less than or equal to n.)
${\mathbb{P}}(ord\pi = ord\pi ') \ge {1 \over 2}{n^{ - 2}}lg*n$ for infinitely many n. (Here lg*n is the height of the tallest tower of twos that is less than or equal to n.)
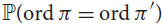
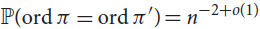
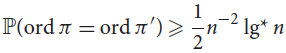
A counterexample to the Bollobás–Riordan conjectures on sparse graph limits
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 5 / September 2021
- Published online by Cambridge University Press:
- 27 January 2021, pp. 796-799
-
- Article
- Export citation
NONLINEAR COINTEGRATING POWER FUNCTION REGRESSION WITH ENDOGENEITY
-
- Journal:
- Econometric Theory / Volume 37 / Issue 6 / December 2021
- Published online by Cambridge University Press:
- 26 January 2021, pp. 1173-1213
-
- Article
- Export citation
Artificial Benchmark for Community Detection (ABCD)—Fast random graph model with community structure
-
- Journal:
- Network Science / Volume 9 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 26 January 2021, pp. 153-178
-
- Article
-
- You have access
- Open access
- Export citation
ON THE UNIFORM CONVERGENCE OF DECONVOLUTION ESTIMATORS FROM REPEATED MEASUREMENTS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 25 January 2021, pp. 172-193
-
- Article
- Export citation
Investigating reconstructed inflows and pathogen infection patterns between low-relief and high-relief subtropical oyster reefs—CORRIGENDUM
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 25 January 2021, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NONLINEAR PANEL DATA MODELS WITH DISTRIBUTION-FREE CORRELATED RANDOM EFFECTS
-
- Journal:
- Econometric Theory / Volume 37 / Issue 6 / December 2021
- Published online by Cambridge University Press:
- 25 January 2021, pp. 1075-1099
-
- Article
- Export citation
Hepatitis B virus infection in EU/EEA and United Kingdom prisons: a descriptive analysis
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 25 January 2021, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A recommendation and risk classification system for connecting rough sleepers to essential outreach services
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 22 January 2021, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
International agricultural trade forecasting using machine learning
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 22 January 2021, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A network approach to measuring state preferences
-
- Journal:
- Network Science / Volume 9 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 20 January 2021, pp. 135-152
-
- Article
- Export citation
Respiratory failure among patients with COVID-19 in Jiangsu province, China: a multicentre retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 20 January 2021, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
