Refine search
Actions for selected content:
53175 results in Statistics and Probability
A non-convex optimization approach of searching algebraic degree phase-type representations for general phase-type distributions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 03 March 2025, pp. 1101-1137
- Print publication:
- September 2025
-
- Article
- Export citation
Cyber-insurance pricing models
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 03 March 2025, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bartonella tracing in wild rodents in northwestern Mexico
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 28 February 2025, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data technologies and analytics for policy and governance: a landscape review
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
GenFormer: a deep-learning-based approach for generating multivariate stochastic processes
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A UNIFIED THEORY FOR ARMA MODELS WITH VARYING COEFFICIENTS: ONE SOLUTION FITS ALL
-
- Journal:
- Econometric Theory / Volume 42 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 27 February 2025, pp. 192-245
-
- Article
-
- You have access
- Open access
- Export citation
IS COMPLETENESS NECESSARY? ESTIMATION IN NONIDENTIFIED LINEAR MODELS
-
- Journal:
- Econometric Theory / Volume 41 / Issue 6 / December 2025
- Published online by Cambridge University Press:
- 27 February 2025, pp. 1284-1321
-
- Article
- Export citation
A NOTE ON MINIMAX REGRET RULES WITH MULTIPLE TREATMENTS IN FINITE SAMPLES
-
- Journal:
- Econometric Theory / Volume 42 / Issue 3 / June 2026
- Published online by Cambridge University Press:
- 27 February 2025, pp. 723-749
-
- Article
- Export citation
-
We study minimax regret treatment rules under matched treatment assignment in a setup where a policymaker, informed by a sample of size N, needs to decide between T different treatments for a $T\geq 2$
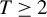 . Randomized rules are allowed for. We show that the generalization of the minimax regret rule derived in Schlag (2006, ELEVEN—Tests needed for a recommendation, EUI working paper) and Stoye (2009, Journal of Econometrics 151, 70–81) for the case $T=2$
. Randomized rules are allowed for. We show that the generalization of the minimax regret rule derived in Schlag (2006, ELEVEN—Tests needed for a recommendation, EUI working paper) and Stoye (2009, Journal of Econometrics 151, 70–81) for the case $T=2$ is minimax regret for general finite $T>2$
is minimax regret for general finite $T>2$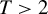 and also that the proof structure via the Nash equilibrium and the “coarsening” approaches generalizes as well. We also show by example, that in the case of random assignment the generalization of the minimax rule in Stoye (2009, Journal of Econometrics 151, 70–81) to the case $T>2$
and also that the proof structure via the Nash equilibrium and the “coarsening” approaches generalizes as well. We also show by example, that in the case of random assignment the generalization of the minimax rule in Stoye (2009, Journal of Econometrics 151, 70–81) to the case $T>2$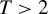 is not necessarily minimax regret and derive minimax regret rules for a few small sample cases, e.g., for $N=2$
is not necessarily minimax regret and derive minimax regret rules for a few small sample cases, e.g., for $N=2$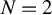 when $T=3.$
when $T=3.$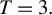
In the case where a covariate x is included, it is shown that a minimax regret rule is obtained by using minimax regret rules in the “conditional-on-x” problem if the latter are obtained as Nash equilibria.
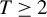

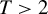
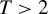
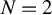
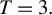
Extropy-based dynamic cumulative residual inaccuracy measure: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 26 February 2025, pp. 461-485
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Some generalized information and divergence generating functions: properties, estimation, validation, and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 25 February 2025, pp. 397-430
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reliability analysis of a K-out-of-N system with random rate of repair
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 25 February 2025, pp. 431-460
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
When forecasting and foresight meet data and innovation: toward a taxonomy of anticipatory methods for migration policy
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 25 February 2025, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transmission of Mycobacterium tuberculosis in four prisons in Colombia
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 24 February 2025, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The number of overlapping customers in Erlang-A queues: an asymptotic approach
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 21 February 2025, pp. 344-369
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Active learning for regression in engineering populations: a risk-informed approach
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 21 February 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A negative charge at position D+5 of Motif A is critical for function of the major facilitator superfamily multidrug/H+ antiporter MdtM’ – RETRACTION
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 21 February 2025, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A NONPARAMETRIC TEST FOR INSTANTANEOUS CAUSALITY WITH TIME-VARYING VARIANCES
-
- Journal:
- Econometric Theory / Volume 42 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 21 February 2025, pp. 414-442
-
- Article
- Export citation
-
This paper proposes a consistent nonparametric test with good sampling properties to detect instantaneous causality between vector autoregressive (VAR) variables with time-varying variances. The new test takes the form of the U-statistic, and has a limiting standard normal distribution under the null. We further show that the test is consistent against any fixed alternatives, and has nontrivial asymptotic power against a class of local alternatives with a rate slower than
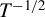 $T^{-1/2}$. We also propose a wild bootstrap procedure to better approximate the finite sample null distribution of the test statistic. Monte Carlo experiments are conducted to highlight the merits of the proposed test relative to other popular tests in finite samples. Finally, we apply the new test to investigate the instantaneous causality relationship between money supply and inflation rates in the USA.
$T^{-1/2}$. We also propose a wild bootstrap procedure to better approximate the finite sample null distribution of the test statistic. Monte Carlo experiments are conducted to highlight the merits of the proposed test relative to other popular tests in finite samples. Finally, we apply the new test to investigate the instantaneous causality relationship between money supply and inflation rates in the USA.
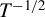
Graph connectivity with fixed endpoints in the random-connection model
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 21 February 2025, pp. 370-396
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the count of subgraphs with an arbitrary configuration of endpoints in the random-connection model based on a Poisson point process on
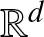 ${\mathord{\mathbb R}}^d$. We present combinatorial expressions for the computation of the cumulants and moments of all orders of such subgraph counts, which allow us to estimate the growth of cumulants as the intensity of the underlying Poisson point process goes to infinity. As a consequence, we obtain a central limit theorem with explicit convergence rates under the Kolmogorov distance and connectivity bounds. Numerical examples are presented using a computer code in SageMath for the closed-form computation of cumulants of any order, for any type of connected subgraph, and for any configuration of endpoints in any dimension
${\mathord{\mathbb R}}^d$. We present combinatorial expressions for the computation of the cumulants and moments of all orders of such subgraph counts, which allow us to estimate the growth of cumulants as the intensity of the underlying Poisson point process goes to infinity. As a consequence, we obtain a central limit theorem with explicit convergence rates under the Kolmogorov distance and connectivity bounds. Numerical examples are presented using a computer code in SageMath for the closed-form computation of cumulants of any order, for any type of connected subgraph, and for any configuration of endpoints in any dimension 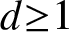 $d{\geq} 1$. In particular, graph connectivity estimates, Gram–Charlier expansions for density estimation, and correlation estimates for joint subgraph counting are obtained.
$d{\geq} 1$. In particular, graph connectivity estimates, Gram–Charlier expansions for density estimation, and correlation estimates for joint subgraph counting are obtained.
Competition between protons and substrate for binding to the major facilitator superfamily multidrug/H+ antiporter MdtM’ – RETRACTION
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 21 February 2025, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Count on Me: Moral Language in Social Media and Policy Discourse during the Ukraine-Russia Conflict
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 February 2025, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
