Refine search
Actions for selected content:
53179 results in Statistics and Probability
Hydrogen reaction rate modeling based on convolutional neural network for large eddy simulation
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This article establishes a data-driven modeling framework for lean hydrogen (
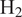 $ {\mathrm{H}}_2 $)-air reaction rates for the Large Eddy Simulation (LES) of turbulent reactive flows. This is particularly challenging since
$ {\mathrm{H}}_2 $)-air reaction rates for the Large Eddy Simulation (LES) of turbulent reactive flows. This is particularly challenging since 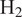 $ {\mathrm{H}}_2 $ molecules diffuse much faster than heat, leading to large variations in burning rates, thermodiffusive instabilities at the subfilter scale, and complex turbulence-chemistry interactions. Our data-driven approach leverages a Convolutional Neural Network (CNN), trained to approximate filtered burning rates from emulated LES data. First, five different lean premixed turbulent
$ {\mathrm{H}}_2 $ molecules diffuse much faster than heat, leading to large variations in burning rates, thermodiffusive instabilities at the subfilter scale, and complex turbulence-chemistry interactions. Our data-driven approach leverages a Convolutional Neural Network (CNN), trained to approximate filtered burning rates from emulated LES data. First, five different lean premixed turbulent 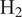 $ {\mathrm{H}}_2 $-air flame Direct Numerical Simulations (DNSs) are computed each with a unique global equivalence ratio. Second, DNS snapshots are filtered and downsampled to emulate LES data. Third, a CNN is trained to approximate the filtered burning rates as a function of LES scalar quantities: progress variable, local equivalence ratio, and flame thickening due to filtering. Finally, the performances of the CNN model are assessed on test solutions never seen during training. The model retrieves burning rates with very high accuracy. It is also tested on two filter and downsampling parameters and two global equivalence ratios between those used during training. For these interpolation cases, the model approximates burning rates with low error even though the cases were not included in the training dataset. This a priori study shows that the proposed data-driven machine learning framework is able to address the challenge of modeling lean premixed
$ {\mathrm{H}}_2 $-air flame Direct Numerical Simulations (DNSs) are computed each with a unique global equivalence ratio. Second, DNS snapshots are filtered and downsampled to emulate LES data. Third, a CNN is trained to approximate the filtered burning rates as a function of LES scalar quantities: progress variable, local equivalence ratio, and flame thickening due to filtering. Finally, the performances of the CNN model are assessed on test solutions never seen during training. The model retrieves burning rates with very high accuracy. It is also tested on two filter and downsampling parameters and two global equivalence ratios between those used during training. For these interpolation cases, the model approximates burning rates with low error even though the cases were not included in the training dataset. This a priori study shows that the proposed data-driven machine learning framework is able to address the challenge of modeling lean premixed 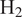 $ {\mathrm{H}}_2 $-air burning rates. It paves the way for a new modeling paradigm for the simulation of carbon-free hydrogen combustion systems.
$ {\mathrm{H}}_2 $-air burning rates. It paves the way for a new modeling paradigm for the simulation of carbon-free hydrogen combustion systems.
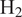
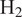
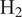
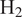
Case studies of AI policy development in Africa
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CHRONOLOGICALLY TRIMMED LS FOR NONLINEAR PREDICTIVE REGRESSIONS WITH PERSISTENCE OF UNKNOWN FORM
-
- Journal:
- Econometric Theory / Volume 42 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 07 February 2025, pp. 375-413
-
- Article
-
- You have access
- Open access
- Export citation
Characteristics and risk factors associated with COVID-19 reinfection in Hong Kong: a retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
IFoA Presidential Address 2024 by Kartina Tahir Thomson
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dientamoeba fragilis cases identified by molecular detection, Utah, United States, 2014–2024
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Face enumeration for split matroid polytopes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 07 February 2025, pp. 528-544
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper initiates the explicit study of face numbers of matroid polytopes and their computation. We prove that, for the large class of split matroid polytopes, their face numbers depend solely on the number of cyclic flats of each rank and size, together with information on the modular pairs of cyclic flats. We provide a formula which allows us to calculate
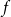 $f$-vectors without the need of taking convex hulls or computing face lattices. We discuss the particular cases of sparse paving matroids and rank two matroids, which are of independent interest due to their appearances in other combinatorial and geometric settings.
$f$-vectors without the need of taking convex hulls or computing face lattices. We discuss the particular cases of sparse paving matroids and rank two matroids, which are of independent interest due to their appearances in other combinatorial and geometric settings.
Using SARS-CoV-2 nucleoprotein antibodies to detect (re)infection
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reflections on the relevance of updated, standardised, and reliable data on sexual and gender-based violence for research and policymaking for eradication, response, and prevention in Sierra Leone
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Anticipating climate change-related mobility in Karachi and Ho Chi Minh City: lessons from a hybrid foresight approach
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Adapting the Flexible Farrington Algorithm for daily situational awareness and alert system to support public health decision-making during the SARS-CoV-2 epidemic in England
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 06 February 2025, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Extending Wormald’s differential equation method to one-sided bounds
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 06 February 2025, pp. 545-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sustaining transformative change in public health in Africa to achieve health development goals
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 06 February 2025, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Satisfiability thresholds for regular occupation problems
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 04 February 2025, pp. 491-527
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In the last two decades the study of random instances of constraint satisfaction problems (CSPs) has flourished across several disciplines, including computer science, mathematics and physics. The diversity of the developed methods, on the rigorous and non-rigorous side, has led to major advances regarding both the theoretical as well as the applied viewpoints. Based on a ceteris paribus approach in terms of the density evolution equations known from statistical physics, we focus on a specific prominent class of regular CSPs, the so-called occupation problems, and in particular on
 $r$-in-
$r$-in-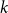 $k$ occupation problems. By now, out of these CSPs only the satisfiability threshold – the largest degree for which the problem admits asymptotically a solution – for the
$k$ occupation problems. By now, out of these CSPs only the satisfiability threshold – the largest degree for which the problem admits asymptotically a solution – for the 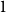 $1$-in-
$1$-in-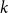 $k$ occupation problem has been rigorously established. Here we determine the satisfiability threshold of the
$k$ occupation problem has been rigorously established. Here we determine the satisfiability threshold of the 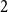 $2$-in-
$2$-in-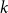 $k$ occupation problem for all
$k$ occupation problem for all 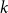 $k$. In the proof we exploit the connection of an associated optimization problem regarding the overlap of satisfying assignments to a fixed point problem inspired by belief propagation, a message passing algorithm developed for solving such CSPs.
$k$. In the proof we exploit the connection of an associated optimization problem regarding the overlap of satisfying assignments to a fixed point problem inspired by belief propagation, a message passing algorithm developed for solving such CSPs.

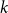
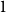
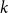
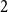
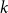
SARS-CoV-2 vaccination influence in the development of long-COVID clinical phenotypes
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 04 February 2025, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Critical configurations of the hard-core model on square grid graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 04 February 2025, pp. 445-485
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the hard-core model on a finite square grid graph with stochastic Glauber dynamics parametrized by the inverse temperature
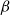 $\beta$. We investigate how the transition between its two maximum-occupancy configurations takes place in the low-temperature regime
$\beta$. We investigate how the transition between its two maximum-occupancy configurations takes place in the low-temperature regime 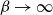 $\beta \to \infty$ in the case of periodic boundary conditions. The hard-core constraints and the grid symmetry make the structure of the critical configurations for this transition, also known as essential saddles, very rich and complex. We provide a comprehensive geometrical characterization of these configurations that together constitute a bottleneck for the Glauber dynamics in the low-temperature limit. In particular, we develop a novel isoperimetric inequality for hard-core configurations with a fixed number of particles and show how the essential saddles are characterized not only by the number of particles but also their geometry.
$\beta \to \infty$ in the case of periodic boundary conditions. The hard-core constraints and the grid symmetry make the structure of the critical configurations for this transition, also known as essential saddles, very rich and complex. We provide a comprehensive geometrical characterization of these configurations that together constitute a bottleneck for the Glauber dynamics in the low-temperature limit. In particular, we develop a novel isoperimetric inequality for hard-core configurations with a fixed number of particles and show how the essential saddles are characterized not only by the number of particles but also their geometry.
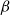
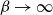
Deep learning modeling of manufacturing and build variations on multistage axial compressors aerodynamics
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 03 February 2025, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Applications of deep learning to physical simulations such as Computational Fluid Dynamics have recently experienced a surge in interest, and their viability has been demonstrated in different domains. However, due to the highly complex, turbulent, and three-dimensional flows, they have not yet been proven usable for turbomachinery applications. Multistage axial compressors for gas turbine applications represent a remarkably challenging case, due to the high-dimensionality of the regression of the flow field from geometrical and operational variables. This paper demonstrates the development and application of a deep learning framework for predictions of the flow field and aerodynamic performance of multistage axial compressors. A physics-based dimensionality reduction approach unlocks the potential for flow-field predictions, as it re-formulates the regression problem from an unstructured to a structured one, as well as reducing the number of degrees of freedom. Compared to traditional “black-box” surrogate models, it provides explainability to the predictions of the overall performance by identifying the corresponding aerodynamic drivers. The model is applied to manufacturing and build variations, as the associated performance scatter is known to have a significant impact on
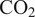 $ \mathrm{C}{\mathrm{O}}_2 $ emissions, which poses a challenge of great industrial and environmental relevance. The proposed architecture is proven to achieve an accuracy comparable to that of the CFD benchmark, in real-time, for an industrially relevant application. The deployed model is readily integrated within the manufacturing and build process of gas turbines, thus providing the opportunity to analytically assess the impact on performance with actionable and explainable data.
$ \mathrm{C}{\mathrm{O}}_2 $ emissions, which poses a challenge of great industrial and environmental relevance. The proposed architecture is proven to achieve an accuracy comparable to that of the CFD benchmark, in real-time, for an industrially relevant application. The deployed model is readily integrated within the manufacturing and build process of gas turbines, thus providing the opportunity to analytically assess the impact on performance with actionable and explainable data.
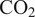
Digital policy and Nigeria’s Platform Code of Practice: towards a radical co-regulatory turn
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 03 February 2025, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Flexible multi-fidelity framework for load estimation of wind farms through graph neural networks and transfer learning – ERRATUM
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 03 February 2025, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interacting urns on directed networks with node-dependent sampling and reinforcement
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 03 February 2025, pp. 972-996
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
