Refine search
Actions for selected content:
53175 results in Statistics and Probability
The role of carbonate equilibrium in scale formation of calcium carbonate in a power plant open recirculating system
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Applied Probability Trust prizes 2024
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 14 February 2025, p. 445
- Print publication:
- March 2025
-
- Article
- Export citation
REGRESSION DISCONTINUITY DESIGN WITH POTENTIALLY MANY COVARIATES
-
- Journal:
- Econometric Theory / Volume 41 / Issue 6 / December 2025
- Published online by Cambridge University Press:
- 14 February 2025, pp. 1416-1451
-
- Article
-
- You have access
- Open access
- Export citation
-
This article examines high-dimensional covariates in regression discontinuity design (RDD) analysis. We introduce estimation and inference methods for the RDD models that incorporate covariate selection while maintaining stability across various numbers of covariates. The proposed methods combine a localization approach using kernel weights with
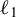 $\ell _{1}$-penalization to handle high-dimensional covariates. We provide both theoretical and numerical evidence demonstrating the efficacy of our methods. Theoretically, we present risk and coverage properties for our point estimation and inference methods. Conditions are given under which the proposed estimator becomes more efficient than the conventional covariate adjusted estimator at the cost of an additional sparsity condition. Numerically, our simulation experiments and empirical examples show the robust behaviors of the proposed methods to the number of covariates in terms of bias and variance for point estimation and coverage probability and interval length for inference.
$\ell _{1}$-penalization to handle high-dimensional covariates. We provide both theoretical and numerical evidence demonstrating the efficacy of our methods. Theoretically, we present risk and coverage properties for our point estimation and inference methods. Conditions are given under which the proposed estimator becomes more efficient than the conventional covariate adjusted estimator at the cost of an additional sparsity condition. Numerically, our simulation experiments and empirical examples show the robust behaviors of the proposed methods to the number of covariates in terms of bias and variance for point estimation and coverage probability and interval length for inference.
Advancing early warning mechanisms: an augmented intelligence-driven model for predicting multidimensional vulnerability levels in Afghanistan
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 14 February 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reliability and optimal age replacement policy of a system subject to shocks following a Markovian arrival process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 14 February 2025, pp. 1010-1027
- Print publication:
- September 2025
-
- Article
- Export citation
Optimal convergence rates of MCMC integration for functions with unbounded second moment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 14 February 2025, pp. 1069-1075
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the Markov chain Monte Carlo estimator for numerical integration for functions that do not need to be square integrable with respect to the invariant distribution. For chains with a spectral gap we show that the absolute mean error for
 $L^p$ functions, with
$L^p$ functions, with  $p \in (1,2)$, decreases like
$p \in (1,2)$, decreases like  $n^{({1}/{p}) -1}$, which is known to be the optimal rate. This improves currently known results where an additional parameter
$n^{({1}/{p}) -1}$, which is known to be the optimal rate. This improves currently known results where an additional parameter  $\delta \gt 0$ appears and the convergence is of order
$\delta \gt 0$ appears and the convergence is of order  $n^{(({1+\delta})/{p})-1}$.
$n^{(({1+\delta})/{p})-1}$.





Large Shigella flexneri outbreak linked to a takeaway, South Wales: a case–control study
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 14 February 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Minimal H-factors and covers
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 14 February 2025, pp. 136-152
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a fixed small graph H and a larger graph G, an H-factor is a collection of vertex-disjoint subgraphs
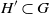 $H'\subset G$, each isomorphic to H, that cover the vertices of G. If G is the complete graph
$H'\subset G$, each isomorphic to H, that cover the vertices of G. If G is the complete graph 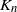 $K_n$ equipped with independent U(0,1) edge weights, what is the lowest total weight of an H-factor? This problem has previously been considered for
$K_n$ equipped with independent U(0,1) edge weights, what is the lowest total weight of an H-factor? This problem has previously been considered for 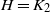 $H=K_2$, for example. We show that if H contains a cycle, then the minimum weight is sharply concentrated around some
$H=K_2$, for example. We show that if H contains a cycle, then the minimum weight is sharply concentrated around some 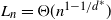 $L_n = \Theta(n^{1-1/d^*})$ (where
$L_n = \Theta(n^{1-1/d^*})$ (where 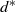 $d^*$ is the maximum 1-density of any subgraph of H). Some of our results also hold for H-covers, where the copies of H are not required to be vertex-disjoint.
$d^*$ is the maximum 1-density of any subgraph of H). Some of our results also hold for H-covers, where the copies of H are not required to be vertex-disjoint.
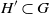
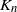
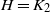
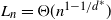
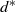
LEARNING MARKOV PROCESSES WITH LATENT VARIABLES
-
- Journal:
- Econometric Theory / Volume 42 / Issue 3 / June 2026
- Published online by Cambridge University Press:
- 13 February 2025, pp. 501-513
-
- Article
- Export citation
THE ET INTERVIEW: PROFESSOR JOEL L. HOROWITZ
- Part of
-
- Journal:
- Econometric Theory / Volume 42 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 13 February 2025, pp. 246-293
-
- Article
- Export citation
OPTIMAL MODEL AVERAGING FOR JOINT VALUE-AT-RISK AND EXPECTED SHORTFALL REGRESSION
-
- Journal:
- Econometric Theory / Volume 42 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 12 February 2025, pp. 101-134
-
- Article
- Export citation
Bayesian spatio-temporal modelling of tuberculosis in Vietnam: Insights from a local-area analysis
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 12 February 2025, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Towards more transparent risk assessment of communicable diseases – Redefining probability and impact
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 12 February 2025, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A maximum likelihood approach for uncertain volumes in the additive reserving model
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 12 February 2025, pp. 287-312
- Print publication:
- May 2025
-
- Article
- Export citation
Centrality and social domains: The role of support, conflict, and ambivalence in the perception of linguistic similarity
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The philosophical foundations of digital twinning
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hydrogen reaction rate modeling based on convolutional neural network for large eddy simulation
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This article establishes a data-driven modeling framework for lean hydrogen (
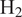 $ {\mathrm{H}}_2 $)-air reaction rates for the Large Eddy Simulation (LES) of turbulent reactive flows. This is particularly challenging since
$ {\mathrm{H}}_2 $)-air reaction rates for the Large Eddy Simulation (LES) of turbulent reactive flows. This is particularly challenging since 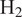 $ {\mathrm{H}}_2 $ molecules diffuse much faster than heat, leading to large variations in burning rates, thermodiffusive instabilities at the subfilter scale, and complex turbulence-chemistry interactions. Our data-driven approach leverages a Convolutional Neural Network (CNN), trained to approximate filtered burning rates from emulated LES data. First, five different lean premixed turbulent
$ {\mathrm{H}}_2 $ molecules diffuse much faster than heat, leading to large variations in burning rates, thermodiffusive instabilities at the subfilter scale, and complex turbulence-chemistry interactions. Our data-driven approach leverages a Convolutional Neural Network (CNN), trained to approximate filtered burning rates from emulated LES data. First, five different lean premixed turbulent 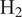 $ {\mathrm{H}}_2 $-air flame Direct Numerical Simulations (DNSs) are computed each with a unique global equivalence ratio. Second, DNS snapshots are filtered and downsampled to emulate LES data. Third, a CNN is trained to approximate the filtered burning rates as a function of LES scalar quantities: progress variable, local equivalence ratio, and flame thickening due to filtering. Finally, the performances of the CNN model are assessed on test solutions never seen during training. The model retrieves burning rates with very high accuracy. It is also tested on two filter and downsampling parameters and two global equivalence ratios between those used during training. For these interpolation cases, the model approximates burning rates with low error even though the cases were not included in the training dataset. This a priori study shows that the proposed data-driven machine learning framework is able to address the challenge of modeling lean premixed
$ {\mathrm{H}}_2 $-air flame Direct Numerical Simulations (DNSs) are computed each with a unique global equivalence ratio. Second, DNS snapshots are filtered and downsampled to emulate LES data. Third, a CNN is trained to approximate the filtered burning rates as a function of LES scalar quantities: progress variable, local equivalence ratio, and flame thickening due to filtering. Finally, the performances of the CNN model are assessed on test solutions never seen during training. The model retrieves burning rates with very high accuracy. It is also tested on two filter and downsampling parameters and two global equivalence ratios between those used during training. For these interpolation cases, the model approximates burning rates with low error even though the cases were not included in the training dataset. This a priori study shows that the proposed data-driven machine learning framework is able to address the challenge of modeling lean premixed 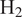 $ {\mathrm{H}}_2 $-air burning rates. It paves the way for a new modeling paradigm for the simulation of carbon-free hydrogen combustion systems.
$ {\mathrm{H}}_2 $-air burning rates. It paves the way for a new modeling paradigm for the simulation of carbon-free hydrogen combustion systems.
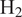
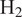
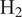
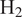
Case studies of AI policy development in Africa
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CHRONOLOGICALLY TRIMMED LS FOR NONLINEAR PREDICTIVE REGRESSIONS WITH PERSISTENCE OF UNKNOWN FORM
-
- Journal:
- Econometric Theory / Volume 42 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 07 February 2025, pp. 375-413
-
- Article
-
- You have access
- Open access
- Export citation
Characteristics and risk factors associated with COVID-19 reinfection in Hong Kong: a retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
