Refine search
Actions for selected content:
53175 results in Statistics and Probability
Are children and adolescents living with HIV in Europe and South Africa at higher risk of SARS-CoV-2 and poor COVID-19 outcomes?
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 21 February 2025, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Uneven progress: Analyzing the factors behind digital technology adoption rates in Sub-Saharan Africa (SSA)
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 February 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PARAMETERS ON THE BOUNDARY IN PREDICTIVE REGRESSION
-
- Journal:
- Econometric Theory / Volume 42 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 21 February 2025, pp. 470-500
-
- Article
- Export citation
A comprehensive review of the childhood vaccination landscape in Malaysia
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 20 February 2025, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk management in the era of data-centric engineering
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 20 February 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Worst-case reinsurance strategy with likelihood ratio uncertainty
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 20 February 2025, pp. 492-513
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Digital & data-driven transformations in governance: a landscape review
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 20 February 2025, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The mean residual life at random age and its connection to variability measures
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 19 February 2025, pp. 326-343
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a nonnegative random variable T representing the lifetime of a system. We discuss the residual lifetime
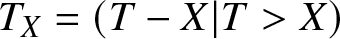 $T_X=(T-X|T \gt X)$, where X denotes the random age of the system. We also discuss the mean residual life (MRL) of T at the random time X. It is shown that the MRL at random age (MRLR) is closely related to some well-known variability measures. In particular, we show that the MRLR can be considered a generalization of Gini’s mean difference (GMD). Under the proportional hazards model, we show that the MRLR gives the extended GMD and the extended cumulative residual entropy as special cases. Then, we provide a decomposition result indicating that the MRLR has a covariance representation. Some comparison results are also established for the MRLs of two systems at random ages.
$T_X=(T-X|T \gt X)$, where X denotes the random age of the system. We also discuss the mean residual life (MRL) of T at the random time X. It is shown that the MRL at random age (MRLR) is closely related to some well-known variability measures. In particular, we show that the MRLR can be considered a generalization of Gini’s mean difference (GMD). Under the proportional hazards model, we show that the MRLR gives the extended GMD and the extended cumulative residual entropy as special cases. Then, we provide a decomposition result indicating that the MRLR has a covariance representation. Some comparison results are also established for the MRLs of two systems at random ages.
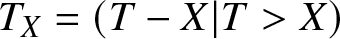
Cost-effectiveness of excluding children with Shiga toxin-producing Escherichia coli (STEC) from childcare settings until microbiological clearance compared to return to childcare settings before microbiological clearance
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 18 February 2025, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cancer insurance pricing under different scenarios associated with diagnosis and treatment
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 3 / November 2025
- Published online by Cambridge University Press:
- 18 February 2025, pp. 511-542
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Long edges in Galton–Watson trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 18 February 2025, pp. 1053-1068
- Print publication:
- September 2025
-
- Article
- Export citation
TESTING FOR COEFFICIENT RANDOMNESS IN LOCAL-TO-UNITY AUTOREGRESSIONS
-
- Journal:
- Econometric Theory / Volume 42 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 18 February 2025, pp. 443-469
-
- Article
- Export citation
Analysis of National Cybersecurity Strategies of G20: objectives, latent themes, latest trends and comparisons
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 18 February 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fostering public trust in national health data platforms: key considerations for public involvement activities for England and Switzerland
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The REDATAM format and its challenges for data access and information creation in public policy
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Invisible data in night-time governance: addressing policy gaps and building a digital rights framework for cities after dark
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Semi-parametric estimation of system reliability for multicomponent stress-strength model under hierarchical Archimedean copulas
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 17 February 2025, pp. 278-308
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
State-linked manipulated media in the time of Covid-19: a look at Iran
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
LEAST TRIMMED SQUARES: NUISANCE PARAMETER FREE ASYMPTOTICS
-
- Journal:
- Econometric Theory / Volume 42 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 17 February 2025, pp. 336-374
-
- Article
-
- You have access
- Open access
- Export citation
-
The Least Trimmed Squares (LTS) regression estimator is known to be very robust to the presence of “outliers”. It is based on a clear and intuitive idea: in a sample of size n, it searches for the h-subsample of observations with the smallest sum of squared residuals. The remaining
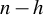 $n-h$ observations are declared “outliers”. Fast algorithms for its computation exist. Nevertheless, the existing asymptotic theory for LTS, based on the traditional
$n-h$ observations are declared “outliers”. Fast algorithms for its computation exist. Nevertheless, the existing asymptotic theory for LTS, based on the traditional 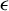 $\epsilon $-contamination model, shows that the asymptotic behavior of both regression and scale estimators depend on nuisance parameters. Using a recently proposed new model, in which the LTS estimator is maximum likelihood, we show that the asymptotic behavior of both the LTS regression and scale estimators are free of nuisance parameters. Thus, with the new model as a benchmark, standard inference procedures apply while allowing a broad range of contamination.
$\epsilon $-contamination model, shows that the asymptotic behavior of both regression and scale estimators depend on nuisance parameters. Using a recently proposed new model, in which the LTS estimator is maximum likelihood, we show that the asymptotic behavior of both the LTS regression and scale estimators are free of nuisance parameters. Thus, with the new model as a benchmark, standard inference procedures apply while allowing a broad range of contamination.
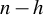
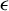
Probabilistic voting models with varying speeds of Correlation decay
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 17 February 2025, pp. 35-64
- Print publication:
- March 2025
-
- Article
- Export citation
