
Let 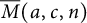 $\overline {M}(a,c,n)$ denote the number of overpartitions of n with first residual crank congruent to a modulo c with
$\overline {M}(a,c,n)$ denote the number of overpartitions of n with first residual crank congruent to a modulo c with  $c\geq 3$ being odd and
$c\geq 3$ being odd and  $0\leq a<c$. The central objective of this paper is twofold: firstly, to establish an asymptotic formula for the crank of overpartitions; and secondly, to establish several inequalities concerning
$0\leq a<c$. The central objective of this paper is twofold: firstly, to establish an asymptotic formula for the crank of overpartitions; and secondly, to establish several inequalities concerning  $\overline {M}(a,c,n)$ that encompasses crank differences, positivity, and strict log-subadditivity.
$\overline {M}(a,c,n)$ that encompasses crank differences, positivity, and strict log-subadditivity.

