Refine search
Actions for selected content:
190 results
Chapter 4 - Learning as Habituation and Teaching of Skills
- from Part II - Theory/Practice
-
- Book:
- Genres of Teaching
- Published online:
- 29 April 2026
- Print publication:
- 04 June 2026, pp 74-123
-
- Chapter
- Export citation
Amigo: a Data-Driven Calibration of the JWST Interferometer
-
- Journal:
- Publications of the Astronomical Society of Australia / Accepted manuscript
- Published online by Cambridge University Press:
- 29 April 2026, pp. 1-37
-
- Article
-
- You have access
- Open access
- Export citation
Integrating Machine Learning and Path Planning for UAS-based Weed Recognition and Site-specific Management in Turfgrass Systems
-
- Journal:
- Weed Science / Accepted manuscript
- Published online by Cambridge University Press:
- 26 March 2026, pp. 1-29
-
- Article
-
- You have access
- Open access
- Export citation
1 - What’s in an Abbreviation? Defining and Understanding AI
-
- Book:
- Governing AI
- Published online:
- 20 February 2026
- Print publication:
- 19 February 2026, pp 9-21
-
- Chapter
- Export citation

Introduction to Machine Learning
- From Math to Code
-
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025
-
- Textbook
- Export citation
2 - Principles of Artificial Neural Networks
-
- Book:
- Introduction to Neuromorphic Computing
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026, pp 15-26
-
- Chapter
- Export citation
Artificial intelligence in breast cancer diagnosis: A systematic literature review
-
- Journal:
- Cambridge Prisms: Precision Medicine / Volume 3 / 2025
- Published online by Cambridge University Press:
- 21 November 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Do stable neural networks exist for classification problems? – A new view on stability in AI
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 20 November 2025, pp. 238-258
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In deep learning (DL), the instability phenomenon is widespread and well documented, and the most commonly used measure of stability is the Lipschitz constant. While a small Lipchitz constant is traditionally viewed as guarantying stability, it does not capture the instability phenomenon in DL for classification well. The reason is that a classification function – which is the target function to be approximated – is necessarily discontinuous, thus having an ‘infinite’ Lipchitz constant. As a result, the classical approach will deem every classification function unstable, yet basic classification functions a la ‘is there a cat in the image?’ will typically be locally very ‘flat’ – and thus locally stable – except at the decision boundary. The lack of an appropriate measure of stability hinders a rigorous theory for stability in DL, and consequently, there are no proper approximation theoretic results that can guarantee the existence of stable networks for classification functions. In this paper, we introduce a novel stability measure
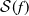 $\mathcal{S}(f)$, for any classification function
$\mathcal{S}(f)$, for any classification function 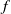 $f$, appropriate to study the stability of classification functions and their approximations. We further prove two approximation theorems: First, for any
$f$, appropriate to study the stability of classification functions and their approximations. We further prove two approximation theorems: First, for any 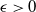 $\epsilon \gt 0$ and any classification function
$\epsilon \gt 0$ and any classification function 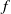 $f$ on a compact set, there is a neural network (NN)
$f$ on a compact set, there is a neural network (NN) 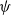 $\psi$, such that
$\psi$, such that 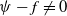 $\psi - f \neq 0$ only on a set of measure
$\psi - f \neq 0$ only on a set of measure 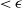 $\lt \epsilon$; moreover,
$\lt \epsilon$; moreover, 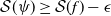 $\mathcal{S}(\psi ) \geq \mathcal{S}(f) - \epsilon$ (as accurate and stable as
$\mathcal{S}(\psi ) \geq \mathcal{S}(f) - \epsilon$ (as accurate and stable as 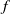 $f$ up to
$f$ up to  $\epsilon$). Second, for any classification function
$\epsilon$). Second, for any classification function 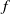 $f$ and
$f$ and 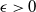 $\epsilon \gt 0$, there exists a NN
$\epsilon \gt 0$, there exists a NN 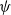 $\psi$ such that
$\psi$ such that 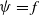 $\psi = f$ on the set of points that are at least
$\psi = f$ on the set of points that are at least  $\epsilon$ away from the decision boundary.
$\epsilon$ away from the decision boundary.
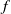
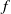
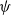
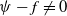
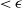
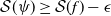
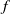

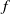
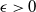
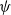
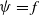

Instability in deep learning – when algorithms cannot compute uncertainty quantifications for neural networks
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 20 November 2025, pp. 290-312
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In deep learning, interval neural networks are used to quantify the uncertainty of a pre-trained neural network. Suppose we are given a computational problem
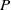 $P$ and a pre-trained neural network
$P$ and a pre-trained neural network 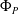 $\Phi _P$ that aims to solve
$\Phi _P$ that aims to solve 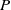 $P$. An interval neural network is then a pair of neural networks
$P$. An interval neural network is then a pair of neural networks 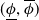 $(\underline {\phi }, \overline {\phi })$, with the property that
$(\underline {\phi }, \overline {\phi })$, with the property that 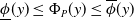 $\underline {\phi }(y) \leq \Phi _P(y) \leq \overline {\phi }(y)$ for all inputs
$\underline {\phi }(y) \leq \Phi _P(y) \leq \overline {\phi }(y)$ for all inputs 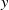 $y$, where the inequalities are meant componentwise.
$y$, where the inequalities are meant componentwise. 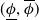 $(\underline {\phi }, \overline {\phi })$ are specifically trained to quantify the uncertainty of
$(\underline {\phi }, \overline {\phi })$ are specifically trained to quantify the uncertainty of 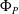 $\Phi _P$, in the sense that the size of the interval
$\Phi _P$, in the sense that the size of the interval 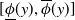 $[\underline {\phi }(y),\overline {\phi }(y)]$ quantifies the uncertainty of the prediction
$[\underline {\phi }(y),\overline {\phi }(y)]$ quantifies the uncertainty of the prediction 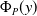 $\Phi _P(y)$. In this paper, we investigate the phenomenon when algorithms cannot compute interval neural networks in the setting of inverse problems. We show that in the typical setting of a linear inverse problem, the problem of constructing an optimal pair of interval neural networks is non-computable, even with the assumption that the pre-trained neural network
$\Phi _P(y)$. In this paper, we investigate the phenomenon when algorithms cannot compute interval neural networks in the setting of inverse problems. We show that in the typical setting of a linear inverse problem, the problem of constructing an optimal pair of interval neural networks is non-computable, even with the assumption that the pre-trained neural network 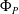 $\Phi _P$ is an optimal solution. In other words, there exist classes of training sets
$\Phi _P$ is an optimal solution. In other words, there exist classes of training sets  $\Omega$, such that there is no algorithm, even randomised (with probability
$\Omega$, such that there is no algorithm, even randomised (with probability 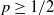 $p \geq 1/2$), that computes an optimal pair of interval neural networks for each training set
$p \geq 1/2$), that computes an optimal pair of interval neural networks for each training set 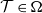 ${\mathcal{T}} \in \Omega$. This phenomenon happens even when we are given a pre-trained neural network
${\mathcal{T}} \in \Omega$. This phenomenon happens even when we are given a pre-trained neural network 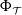 $\Phi _{{\mathcal{T}}}$ that is optimal for
$\Phi _{{\mathcal{T}}}$ that is optimal for 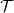 $\mathcal{T}$. This phenomenon is intimately linked to instability in deep learning.
$\mathcal{T}$. This phenomenon is intimately linked to instability in deep learning.
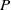
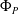
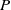
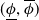
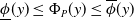
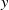
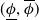
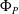
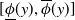
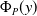
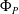

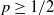
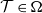
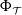
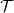

Mathematical Methods in Data Science
- Bridging Theory and Applications with Python
-
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025
-
- Textbook
- Export citation
8 - Neural Networks, Backpropagation, and Stochastic Gradient Descent
-
- Book:
- Mathematical Methods in Data Science
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025, pp 494-559
-
- Chapter
- Export citation
1 - What Is AI?
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 4-23
-
- Chapter
- Export citation

Deep Learning in Quantitative Trading
-
- Published online:
- 03 October 2025
- Print publication:
- 30 October 2025
-
- Element
- Export citation
Neuromodulation and neural networks in psychiatric disorders: current status and emerging prospects
-
- Journal:
- Psychological Medicine / Volume 55 / 2025
- Published online by Cambridge University Press:
- 26 September 2025, e281
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - Statistical Learning
- from Part III - Advanced Concepts
-
- Book:
- Statistics for Chemical Engineers
- Published online:
- 12 December 2025
- Print publication:
- 25 September 2025, pp 289-384
-
- Chapter
- Export citation
