Refine search
Actions for selected content:
7009 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
On the structure of Dense graphs with bounded clique number
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 05 June 2020, pp. 641-649
-
- Article
- Export citation
Graph limits of random unlabelled k-trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 18 May 2020, pp. 722-746
-
- Article
-
- You have access
- Open access
- Export citation
Pointer chasing via triangular discrimination
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 15 May 2020, pp. 485-494
-
- Article
-
- You have access
- Open access
- Export citation
-
We prove an essentially sharp
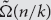 $\tilde \Omega (n/k)$ lower bound on the k-round distributional complexity of the k-step pointer chasing problem under the uniform distribution, when Bob speaks first. This is an improvement over Nisan and Wigderson’s
$\tilde \Omega (n/k)$ lower bound on the k-round distributional complexity of the k-step pointer chasing problem under the uniform distribution, when Bob speaks first. This is an improvement over Nisan and Wigderson’s 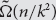 $\tilde \Omega (n/{k^2})$ lower bound, and essentially matches the randomized lower bound proved by Klauck. The proof is information-theoretic, and a key part of it is using asymmetric triangular discrimination instead of total variation distance; this idea may be useful elsewhere.
$\tilde \Omega (n/{k^2})$ lower bound, and essentially matches the randomized lower bound proved by Klauck. The proof is information-theoretic, and a key part of it is using asymmetric triangular discrimination instead of total variation distance; this idea may be useful elsewhere.
Finding independent transversals efficiently
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 14 May 2020, pp. 780-806
-
- Article
- Export citation
-
We give an efficient algorithm that, given a graph G and a partition V1,…,Vm of its vertex set, finds either an independent transversal (an independent set {v1,…,vm} in G such that
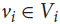 ${v_i} \in {V_i}$ for each i), or a subset
${v_i} \in {V_i}$ for each i), or a subset 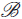 ${\cal B}$ of vertex classes such that the subgraph of G induced by
${\cal B}$ of vertex classes such that the subgraph of G induced by 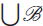 $\bigcup\nolimits_{\cal B}$ has a small dominating set. A non-algorithmic proof of this result has been known for a number of years and has been used to solve many other problems. Thus we are able to give algorithmic versions of many of these applications, a few of which we describe explicitly here.
$\bigcup\nolimits_{\cal B}$ has a small dominating set. A non-algorithmic proof of this result has been known for a number of years and has been used to solve many other problems. Thus we are able to give algorithmic versions of many of these applications, a few of which we describe explicitly here.
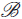
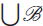

Algorithmic Randomness
- Progress and Prospects
-
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020
8 - Higher randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 232-300
-
- Chapter
- Export citation
1 - Key developments in algorithmic randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 1-39
-
- Chapter
- Export citation
6 - Aspects of Chaitin’s Omega
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 175-205
-
- Chapter
- Export citation
3 - Algorithmic randomness and constructive/computable measure theory
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 58-114
-
- Chapter
- Export citation
7 - Biased algorithmic randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 206-231
-
- Chapter
- Export citation
Index
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 349-359
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp i-iv
-
- Chapter
- Export citation
2 - Algorithmic randomness in ergodic theory
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 40-57
-
- Chapter
- Export citation
5 - Relativization in randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 134-174
-
- Chapter
- Export citation
Contents
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp v-vi
-
- Chapter
- Export citation
4 - Algorithmic randomness and layerwise computability
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 115-133
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp vii-x
-
- Chapter
- Export citation
9 - Resource bounded randomness and its applications
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 301-348
-
- Chapter
- Export citation
5 - What Algorithms Don’t Do
-
- Book:
- The Age of Algorithms
- Published online:
- 17 March 2020
- Print publication:
- 16 April 2020, pp 36-44
-
- Chapter
- Export citation
18 - Can an Algorithm Be Intelligent?
-
- Book:
- The Age of Algorithms
- Published online:
- 17 March 2020
- Print publication:
- 16 April 2020, pp 150-155
-
- Chapter
- Export citation
