Refine search
Actions for selected content:
7009 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Large triangle packings and Tuza’s conjecture in sparse random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 22 July 2020, pp. 757-779
-
- Article
- Export citation
Pseudorandom hypergraph matchings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 22 July 2020, pp. 868-885
-
- Article
- Export citation
A note on distinct distances
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 16 July 2020, pp. 650-663
-
- Article
- Export citation
-
We show that, for a constant-degree algebraic curve γ in ℝD, every set of n points on γ spans at least Ω(n4/3) distinct distances, unless γ is an algebraic helix, in the sense of Charalambides [2]. This improves the earlier bound Ω(n5/4) of Charalambides [2].
We also show that, for every set P of n points that lie on a d-dimensional constant-degree algebraic variety V in ℝD, there exists a subset S ⊂ P of size at least Ω(n4/(9+12(d−1))), such that S spans
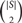 $\left({\begin{array}{*{20}{c}} {|S|} \\ 2 \\\end{array}} \right)$ distinct distances. This improves the earlier bound of Ω(n1/(3d)) of Conlon, Fox, Gasarch, Harris, Ulrich and Zbarsky [4].
$\left({\begin{array}{*{20}{c}} {|S|} \\ 2 \\\end{array}} \right)$ distinct distances. This improves the earlier bound of Ω(n1/(3d)) of Conlon, Fox, Gasarch, Harris, Ulrich and Zbarsky [4].Both results are consequences of a common technical tool.
Preface
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp xiii-xvi
-
- Chapter
- Export citation
6 - Selection
- from Part Two - Divide and Conquer
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 121-140
-
- Chapter
- Export citation
9 - Greedy algorithms on graphs
- from Part Three - Greedy Algorithms
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 205-236
-
- Chapter
- Export citation
7 - Greedy algorithms on lists
- from Part Three - Greedy Algorithms
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 145-176
-
- Chapter
- Export citation
3 - Useful data structures
- from Part One - Basics
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 43-58
-
- Chapter
- Export citation
Part Six - Exhaustive Search
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 365-368
-
- Chapter
- Export citation
Part Four - Thinning Algorithms
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 237-240
-
- Chapter
- Export citation
11 - Segments and subsequences
- from Part Four - Thinning Algorithms
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 267-288
-
- Chapter
- Export citation
Contents
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp vii-xii
-
- Chapter
- Export citation
Index
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 432-437
-
- Chapter
- Export citation
8 - Greedy algorithms on trees
- from Part Three - Greedy Algorithms
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 177-204
-
- Chapter
- Export citation
Dedication
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp v-vi
-
- Chapter
- Export citation
Part One - Basics
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 1-4
-
- Chapter
- Export citation
10 - Introduction to thinning
- from Part Four - Thinning Algorithms
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 241-266
-
- Chapter
- Export citation
Part Two - Divide and Conquer
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 59-62
-
- Chapter
- Export citation
2 - Timing
- from Part One - Basics
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 25-42
-
- Chapter
- Export citation
5 - Sorting
- from Part Two - Divide and Conquer
-
- Book:
- Algorithm Design with Haskell
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020, pp 93-120
-
- Chapter
- Export citation
