Refine search
Actions for selected content:
7009 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Bibliography
-
- Book:
- Geometric and Topological Inference
- Published online:
- 14 September 2018
- Print publication:
- 27 September 2018, pp 224-230
-
- Chapter
- Export citation
3 - Convex Polytopes
- from Part II - Delaunay Complexes
-
- Book:
- Geometric and Topological Inference
- Published online:
- 14 September 2018
- Print publication:
- 27 September 2018, pp 23-43
-
- Chapter
- Export citation
4 - Delaunay Complexes
- from Part II - Delaunay Complexes
-
- Book:
- Geometric and Topological Inference
- Published online:
- 14 September 2018
- Print publication:
- 27 September 2018, pp 44-68
-
- Chapter
- Export citation

Geometric and Topological Inference
-
- Published online:
- 14 September 2018
- Print publication:
- 27 September 2018
Combinatorial Analysis of Growth Models for Series-Parallel Networks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 14 August 2018, pp. 574-599
-
- Article
- Export citation
Analysis of Robin Hood and Other Hashing Algorithms Under the Random Probing Model, With and Without Deletions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 14 August 2018, pp. 600-617
-
- Article
- Export citation
Dual-Pivot Quicksort: Optimality, Analysis and Zeros of Associated Lattice Paths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 14 August 2018, pp. 485-518
-
- Article
- Export citation
Bounding the Number of Common Zeros of Multivariate Polynomials and Their Consecutive Derivatives
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 03 August 2018, pp. 253-279
-
- Article
- Export citation
Limit Shapes via Bijections
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 02 August 2018, pp. 187-240
-
- Article
- Export citation
Exact Distance Colouring in Trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 24 July 2018, pp. 177-186
-
- Article
- Export citation
Tilings in Randomly Perturbed Dense Graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 16 July 2018, pp. 159-176
-
- Article
- Export citation
Turán Number of an Induced Complete Bipartite Graph Plus an Odd Cycle
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 16 July 2018, pp. 241-252
-
- Article
- Export citation
Asymmetric Rényi Problem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 27 June 2018, pp. 542-573
-
- Article
- Export citation
-
In 1960 Rényi, in his Michigan State University lectures, asked for the number of random queries necessary to recover a hidden bijective labelling of n distinct objects. In each query one selects a random subset of labels and asks, which objects have these labels? We consider here an asymmetric version of the problem in which in every query an object is chosen with probability p > 1/2 and we ignore ‘inconclusive’ queries. We study the number of queries needed to recover the labelling in its entirety (Hn), before at least one element is recovered (Fn), and to recover a randomly chosen element (Dn). This problem exhibits several remarkable behaviours: Dn converges in probability but not almost surely; Hn and Fn exhibit phase transitions with respect to p in the second term. We prove that for p > 1/2 with high probability we need
queries to recover the entire bijection. This should be compared to its symmetric (p = 1/2) counterpart established by Pittel and Rubin, who proved that in this case one requires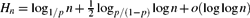 $$H_n=\log_{1/p} n +{\tfrac{1}{2}} \log_{p/(1-p)}\log n +o(\log \log n)$$queries. As a bonus, our analysis implies novel results for random PATRICIA tries, as the problem is probabilistically equivalent to that of the height, fillup level, and typical depth of a PATRICIA trie built from n independent binary sequences generated by a biased(p) memoryless source.
$$H_n=\log_{1/p} n +{\tfrac{1}{2}} \log_{p/(1-p)}\log n +o(\log \log n)$$queries. As a bonus, our analysis implies novel results for random PATRICIA tries, as the problem is probabilistically equivalent to that of the height, fillup level, and typical depth of a PATRICIA trie built from n independent binary sequences generated by a biased(p) memoryless source.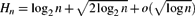 $$ H_n=\log_{2} n +\sqrt{2 \log_{2} n} +o(\sqrt{\log n})$$
$$ H_n=\log_{2} n +\sqrt{2 \log_{2} n} +o(\sqrt{\log n})$$
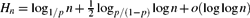
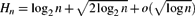
An Extremal Graph Problem with a Transcendental Solution
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 26 June 2018, pp. 303-324
-
- Article
- Export citation
The Number of Satisfying Assignments of Random Regular k-SAT Formulas
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 4 / July 2018
- Published online by Cambridge University Press:
- 20 June 2018, pp. 496-530
-
- Article
- Export citation
Drift Analysis and Evolutionary Algorithms Revisited
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 4 / July 2018
- Published online by Cambridge University Press:
- 20 June 2018, pp. 643-666
-
- Article
- Export citation
Introduction
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 4 / July 2018
- Published online by Cambridge University Press:
- 20 June 2018, p. 441
-
- Article
- Export citation
Bounding the Size of an Almost-Equidistant Set in Euclidean Space
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 13 June 2018, pp. 280-286
-
- Article
- Export citation
Indistinguishable Sceneries on the Boolean Hypercube
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 1 / January 2019
- Published online by Cambridge University Press:
- 05 June 2018, pp. 46-60
-
- Article
- Export citation

Combinatorics
- Topics, Techniques, Algorithms
-
- Published online:
- 28 May 2018
- Print publication:
- 06 October 1994
-
- Textbook
- Export citation
