Refine search
Actions for selected content:
49487 results in Computer Science
References
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 166-177
-
- Chapter
- Export citation
Preface
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp xi-xii
-
- Chapter
- Export citation
Enhancing TRIZ through environment-based design methodology supported by a large language model
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tolerancing in product design – a holistic description scheme
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 28 April 2025, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interlude II - Platform Urbanites: The Doge Pesaro
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 39-41
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp i-iv
-
- Chapter
- Export citation
2 - Edging: From Terminals to Interfaces
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 20-38
-
- Chapter
- Export citation
8 - Implications
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 158-165
-
- Chapter
- Export citation
Interlude III - Container Figures
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 68-70
-
- Chapter
- Export citation
List of Figures and Tables
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp x-x
-
- Chapter
- Export citation
Dedication
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp v-vi
-
- Chapter
- Export citation
Colouring random subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 28 April 2025, pp. 585-595
-
- Article
- Export citation
-
We study several basic problems about colouring the
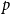 $p$-random subgraph
$p$-random subgraph 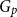 $G_p$ of an arbitrary graph
$G_p$ of an arbitrary graph 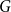 $G$, focusing primarily on the chromatic number and colouring number of
$G$, focusing primarily on the chromatic number and colouring number of 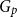 $G_p$. In particular, we show that there exist infinitely many
$G_p$. In particular, we show that there exist infinitely many 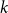 $k$-regular graphs
$k$-regular graphs 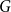 $G$ for which the colouring number (i.e., degeneracy) of
$G$ for which the colouring number (i.e., degeneracy) of 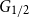 $G_{1/2}$ is at most
$G_{1/2}$ is at most 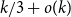 $k/3 + o(k)$ with high probability, thus disproving the natural prediction that such random graphs must have colouring number at least
$k/3 + o(k)$ with high probability, thus disproving the natural prediction that such random graphs must have colouring number at least 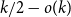 $k/2 - o(k)$.
$k/2 - o(k)$.
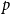
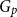
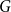
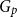
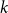
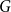
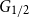
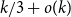
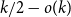
5 - Embedding and Embodying
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 92-110
-
- Chapter
- Export citation
Interlude I - Life along Edges: Coastlines and Reefs
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 18-19
-
- Chapter
- Export citation
Series Editors’ Preface
-
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp viii-ix
-
- Chapter
- Export citation
4 - Hashing Many Containers
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 71-88
-
- Chapter
- Export citation
Interlude V - Being on Stage
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 111-113
-
- Chapter
- Export citation
6 - Closures and Their Stagings
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 114-133
-
- Chapter
- Export citation
Interlude IV - Banded Iron Formations
-
- Book:
- 1000 Platforms
- Published by:
- Bristol University Press
- Published online:
- 06 September 2025
- Print publication:
- 28 April 2025, pp 89-91
-
- Chapter
- Export citation
Mining of high utility itemsets from incremental datasets: a survey
-
- Journal:
- The Knowledge Engineering Review / Volume 40 / 2025
- Published online by Cambridge University Press:
- 28 April 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
