Refine search
Actions for selected content:
48287 results in Computer Science
Part II - Dimension-reduction: PCA/KPCA and feature selection
-
- Book:
- Kernel Methods and Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 17 April 2014, pp 77-78
-
- Chapter
- Export citation
Index
-
- Book:
- Kernel Methods and Machine Learning
- Published online:
- 05 July 2014
- Print publication:
- 17 April 2014, pp 578-591
-
- Chapter
- Export citation
Work it, wrap it, fix it, fold it
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 16 April 2014, pp. 113-127
-
- Article
-
- You have access
- Export citation
ROB volume 32 issue 3 Cover and Front matter
-
- Article
-
- You have access
- Export citation
JFP volume 24 issue 1 Cover and Front matter
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 16 April 2014, pp. f1-f2
-
- Article
-
- You have access
- Export citation
BILATERAL RELEVANT LOGIC
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 2 / June 2014
- Published online by Cambridge University Press:
- 16 April 2014, pp. 250-272
- Print publication:
- June 2014
-
- Article
- Export citation
TRUTH AND SPEED-UP
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 2 / June 2014
- Published online by Cambridge University Press:
- 16 April 2014, pp. 319-340
- Print publication:
- June 2014
-
- Article
- Export citation
ROB volume 32 issue 3 Cover and Back matter
-
- Article
-
- You have access
- Export citation
JFP volume 24 issue 1 Cover and Back matter
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 16 April 2014, pp. b1-b8
-
- Article
-
- You have access
- Export citation
A JUMP-FLUID PRODUCTION–INVENTORY MODEL WITH A DOUBLE BAND CONTROL
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 3 / July 2014
- Published online by Cambridge University Press:
- 15 April 2014, pp. 313-333
-
- Article
-
- You have access
- Export citation
Realm of Racket, by Forrest Bice, Rose DeMaio, Spencer Florence, Feng-Yun Mimi Lin, Scott Lindeman, Nicole Nussbaum, Eric Peterson, Ryan Plessner, David Van Horn, Matthias Felleisen and Conrad Barski, MD, No Starch Press, San Franscisco, CA, 2013, £27.49. ISBN-10:1-59327-491-2.
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 2-3 / May 2014
- Published online by Cambridge University Press:
- 15 April 2014, pp. 419-421
-
- Article
-
- You have access
- Export citation
Inference and learning in probabilistic logic programs using weighted Boolean formulas
-
- Journal:
- Theory and Practice of Logic Programming / Volume 15 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 15 April 2014, pp. 358-401
-
- Article
-
- You have access
- Export citation
REC volume 26 issue 2 Cover and Back matter
-
- Article
-
- You have access
- Export citation
REC volume 26 issue 2 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Distributed collaborative 3D pose estimation of robots from heterogeneous relative measurements: an optimization on manifold approach
-
- Article
- Export citation
-
We propose a distributed algorithm for estimating the 3D pose (position and orientation) of multiple robots with respect to a common frame of reference when Global Positioning System is not available. This algorithm does not rely on the use of any maps, or the ability to recognize landmarks in the environment. Instead, we assume that noisy relative measurements between pairs of robots are intermittently available, which can be any one, or combination, of the following: relative pose, relative orientation, relative position, relative bearing, and relative distance. The additional information about each robot's pose provided by these measurements are used to improve over self-localization estimates. The proposed method is similar to a pose-graph optimization algorithm in spirit: pose estimates are obtained by solving an optimization problem in the underlying Riemannian manifold
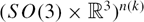 $(SO(3)\times{\mathcal R}^3)^{n(k)}$ . The proposed algorithm is directly applicable to 3D pose estimation, can fuse heterogeneous measurement types, and can handle arbitrary time variation in the neighbor relationships among robots. Simulations show that the errors in the pose estimates obtained using this algorithm are significantly lower than what is achieved when robots estimate their pose without cooperation. Results from experiments with a pair of ground robots with vision-based sensors reinforce these findings. Further, simulations comparing the proposed algorithm with two state-of-the-art existing collaborative localization algorithms identify under what circumstances the proposed algorithm performs better than the existing methods. In addition, the question of trade-offs between cost (of obtaining a certain type of relative measurement) and benefit (improvement in localization accuracy) for various types of relative measurements is considered.
$(SO(3)\times{\mathcal R}^3)^{n(k)}$ . The proposed algorithm is directly applicable to 3D pose estimation, can fuse heterogeneous measurement types, and can handle arbitrary time variation in the neighbor relationships among robots. Simulations show that the errors in the pose estimates obtained using this algorithm are significantly lower than what is achieved when robots estimate their pose without cooperation. Results from experiments with a pair of ground robots with vision-based sensors reinforce these findings. Further, simulations comparing the proposed algorithm with two state-of-the-art existing collaborative localization algorithms identify under what circumstances the proposed algorithm performs better than the existing methods. In addition, the question of trade-offs between cost (of obtaining a certain type of relative measurement) and benefit (improvement in localization accuracy) for various types of relative measurements is considered.
The infection tree of global epidemics
-
- Journal:
- Network Science / Volume 2 / Issue 1 / April 2014
- Published online by Cambridge University Press:
- 10 April 2014, pp. 132-137
-
- Article
-
- You have access
- Open access
- Export citation
