Refine search
Actions for selected content:
48287 results in Computer Science
Deterministic polynomial factoring and association schemes
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 123-140
-
- Article
-
- You have access
- Export citation
-
The problem of finding a nontrivial factor of a polynomial
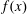 $f(x)$ over a finite field
$f(x)$ over a finite field 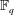 ${\mathbb{F}}_q$ has many known efficient, but randomized, algorithms. The deterministic complexity of this problem is a famous open question even assuming the generalized Riemann hypothesis (GRH). In this work we improve the state of the art by focusing on prime degree polynomials; let
${\mathbb{F}}_q$ has many known efficient, but randomized, algorithms. The deterministic complexity of this problem is a famous open question even assuming the generalized Riemann hypothesis (GRH). In this work we improve the state of the art by focusing on prime degree polynomials; let  $n$ be the degree. If
$n$ be the degree. If 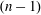 $(n-1)$ has a‘large’
$(n-1)$ has a‘large’  $r$ -smooth divisor
$r$ -smooth divisor  $s$ , then we find a nontrivial factor of
$s$ , then we find a nontrivial factor of 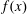 $f(x)$ in deterministic
$f(x)$ in deterministic 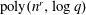 $\mbox{poly}(n^r,\log q)$ time, assuming GRH and that
$\mbox{poly}(n^r,\log q)$ time, assuming GRH and that 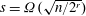 $s=\Omega (\sqrt{n/2^r})$ . Thus, for
$s=\Omega (\sqrt{n/2^r})$ . Thus, for 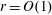 $r=O(1)$ our algorithm is polynomial time. Further, for
$r=O(1)$ our algorithm is polynomial time. Further, for 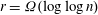 $r=\Omega (\log \log n)$ there are infinitely many prime degrees
$r=\Omega (\log \log n)$ there are infinitely many prime degrees  $n$ for which our algorithm is applicable and better than the best known, assuming GRH. Our methods build on the algebraic-combinatorial framework of
$n$ for which our algorithm is applicable and better than the best known, assuming GRH. Our methods build on the algebraic-combinatorial framework of 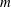 $m$ -schemes initiated by Ivanyos, Karpinski and Saxena (ISSAC 2009). We show that the
$m$ -schemes initiated by Ivanyos, Karpinski and Saxena (ISSAC 2009). We show that the 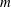 $m$ -scheme on
$m$ -scheme on  $n$ points, implicitly appearing in our factoring algorithm, has an exceptional structure, leading us to the improved time complexity. Our structure theorem proves the existence of small intersection numbers in any association scheme that has many relations, and roughly equal valencies and indistinguishing numbers.
$n$ points, implicitly appearing in our factoring algorithm, has an exceptional structure, leading us to the improved time complexity. Our structure theorem proves the existence of small intersection numbers in any association scheme that has many relations, and roughly equal valencies and indistinguishing numbers.
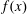

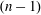


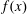
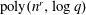
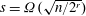
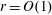
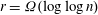


Colouring Planar Graphs With Three Colours and No Large Monochromatic Components
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 4 / July 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 551-570
-
- Article
- Export citation
-
We prove the existence of a function
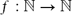 $f :\mathbb{N} \to \mathbb{N}$ such that the vertices of every planar graph with maximum degree Δ can be 3-coloured in such a way that each monochromatic component has at most f(Δ) vertices. This is best possible (the number of colours cannot be reduced and the dependence on the maximum degree cannot be avoided) and answers a question raised by Kleinberg, Motwani, Raghavan and Venkatasubramanian in 1997. Our result extends to graphs of bounded genus.
$f :\mathbb{N} \to \mathbb{N}$ such that the vertices of every planar graph with maximum degree Δ can be 3-coloured in such a way that each monochromatic component has at most f(Δ) vertices. This is best possible (the number of colours cannot be reduced and the dependence on the maximum degree cannot be avoided) and answers a question raised by Kleinberg, Motwani, Raghavan and Venkatasubramanian in 1997. Our result extends to graphs of bounded genus.
Calculating conjugacy classes in Sylow
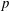 $p$ -subgroups of finite Chevalley groups of rank six and seven
$p$ -subgroups of finite Chevalley groups of rank six and seven
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 109-122
-
- Article
-
- You have access
- Export citation
-
Let
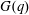 $G(q)$ be a finite Chevalley group, where
$G(q)$ be a finite Chevalley group, where 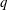 $q$ is a power of a good prime
$q$ is a power of a good prime 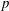 $p$ , and let
$p$ , and let 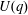 $U(q)$ be a Sylow
$U(q)$ be a Sylow 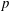 $p$ -subgroup of
$p$ -subgroup of 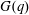 $G(q)$ . Then a generalized version of a conjecture of Higman asserts that the number
$G(q)$ . Then a generalized version of a conjecture of Higman asserts that the number 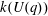 $k(U(q))$ of conjugacy classes in
$k(U(q))$ of conjugacy classes in 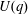 $U(q)$ is given by a polynomial in
$U(q)$ is given by a polynomial in 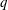 $q$ with integer coefficients. In [S. M. Goodwin and G. Röhrle, J. Algebra 321 (2009) 3321–3334], the first and the third authors of the present paper developed an algorithm to calculate the values of
$q$ with integer coefficients. In [S. M. Goodwin and G. Röhrle, J. Algebra 321 (2009) 3321–3334], the first and the third authors of the present paper developed an algorithm to calculate the values of 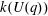 $k(U(q))$ . By implementing it into a computer program using
$k(U(q))$ . By implementing it into a computer program using 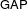 $\mathsf{GAP}$ , they were able to calculate
$\mathsf{GAP}$ , they were able to calculate 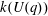 $k(U(q))$ for
$k(U(q))$ for 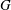 $G$ of rank at most five, thereby proving that for these cases
$G$ of rank at most five, thereby proving that for these cases 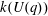 $k(U(q))$ is given by a polynomial in
$k(U(q))$ is given by a polynomial in 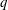 $q$ . In this paper we present some refinements and improvements of the algorithm that allow us to calculate the values of
$q$ . In this paper we present some refinements and improvements of the algorithm that allow us to calculate the values of 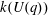 $k(U(q))$ for finite Chevalley groups of rank six and seven, except
$k(U(q))$ for finite Chevalley groups of rank six and seven, except 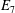 $E_7$ . We observe that
$E_7$ . We observe that 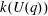 $k(U(q))$ is a polynomial, so that the generalized Higman conjecture holds for these groups. Moreover, if we write
$k(U(q))$ is a polynomial, so that the generalized Higman conjecture holds for these groups. Moreover, if we write 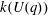 $k(U(q))$ as a polynomial in
$k(U(q))$ as a polynomial in 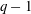 $q-1$ , then the coefficients are non-negative.
$q-1$ , then the coefficients are non-negative.Under the assumption that
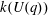 $k(U(q))$ is a polynomial in
$k(U(q))$ is a polynomial in 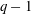 $q-1$ , we also give an explicit formula for the coefficients of
$q-1$ , we also give an explicit formula for the coefficients of 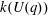 $k(U(q))$ of degrees zero, one and two.
$k(U(q))$ of degrees zero, one and two.
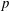
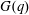
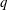
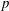
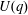
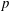
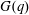
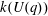
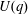
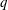
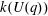
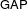
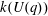
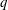
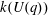
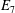
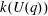
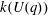
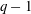
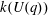
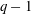
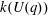
Bounds for zeros of Meixner and Kravchuk polynomials
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 47-57
-
- Article
-
- You have access
- Export citation
Implicit self-adjusting computation for purely functional programs
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 31 March 2014, pp. 56-112
-
- Article
-
- You have access
- Export citation
Randomness in biology
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240308
-
- Article
-
- You have access
- Export citation
Preface to the special issue on developments of the concepts of randomness, statistics and probability
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240301
-
- Article
-
- You have access
- Export citation
Joint distributions, the uncertainty principle and positive distributions†
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240305
-
- Article
- Export citation
Probability, statistics and computation in dynamical systems
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240304
-
- Article
- Export citation
On the concept of probability
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240309
-
- Article
- Export citation
Kolmogorov on the role of randomness in probability theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240302
-
- Article
- Export citation
Probability in quantum computation and quantum computational logics: a survey
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240306
-
- Article
- Export citation
Shannon entropy: a rigorous notion at the crossroads between probability, information theory, dynamical systems and statistical physics
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240311
-
- Article
-
- You have access
- Export citation
A quantum random number generator certified by value indefiniteness
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 28 March 2014, e240303
-
- Article
- Export citation
