Refine search
Actions for selected content:
48287 results in Computer Science
The influence of social networks and homophily on correct voting
-
- Journal:
- Network Science / Volume 2 / Issue 1 / April 2014
- Published online by Cambridge University Press:
- 03 April 2014, pp. 90-106
-
- Article
- Export citation
Sampling networks from their posterior predictive distribution
-
- Journal:
- Network Science / Volume 2 / Issue 1 / April 2014
- Published online by Cambridge University Press:
- 03 April 2014, pp. 107-131
-
- Article
- Export citation
A MACHINE-ASSISTED PROOF OF GÖDEL’S INCOMPLETENESS THEOREMS FOR THE THEORY OF HEREDITARILY FINITE SETS
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 3 / September 2014
- Published online by Cambridge University Press:
- 03 April 2014, pp. 484-498
- Print publication:
- September 2014
-
- Article
- Export citation
Uncovering the structure and temporal dynamics of information propagation
-
- Journal:
- Network Science / Volume 2 / Issue 1 / April 2014
- Published online by Cambridge University Press:
- 03 April 2014, pp. 26-65
-
- Article
- Export citation
Classification of subgroups isomorphic to
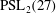 $\mathrm{PSL}_2(27)$ in the Monster
$\mathrm{PSL}_2(27)$ in the Monster
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 33-46
-
- Article
-
- You have access
- Export citation
-
As a contribution to an eventual solution of the problem of the determination of the maximal subgroups of the Monster we prove that the Monster does not contain any subgroup isomorphic to
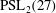 $\mathrm{PSL}_2(27)$ .
$\mathrm{PSL}_2(27)$ .
MODALITY AND AXIOMATIC THEORIES OF TRUTH I: FRIEDMAN-SHEARD
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 2 / June 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 273-298
- Print publication:
- June 2014
-
- Article
- Export citation
Computing fundamental domains for the Bruhat–Tits tree for
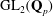 ${\rm GL}_2(\mathbf{Q}_p)$ ,
${\rm GL}_2(\mathbf{Q}_p)$ , 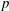 $p$ -adic automorphic forms, and the canonical embedding of Shimura curves
$p$ -adic automorphic forms, and the canonical embedding of Shimura curves
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 1-23
-
- Article
-
- You have access
- Export citation
MODALITY AND AXIOMATIC THEORIES OF TRUTH II: KRIPKE-FEFERMAN
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 2 / June 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 299-318
- Print publication:
- June 2014
-
- Article
- Export citation
On a conjecture of Rudin on squares in arithmetic progressions
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 58-76
-
- Article
-
- You have access
- Export citation
-
Let
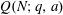 $Q(N;q,a)$ be the number of squares in the arithmetic progression
$Q(N;q,a)$ be the number of squares in the arithmetic progression 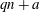 $qn+a$ , for
$qn+a$ , for 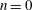 $n=0$ ,
$n=0$ , 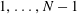 $1,\ldots,N-1$ , and let
$1,\ldots,N-1$ , and let 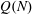 $Q(N)$ be the maximum of
$Q(N)$ be the maximum of 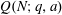 $Q(N;q,a)$ over all non-trivial arithmetic progressions
$Q(N;q,a)$ over all non-trivial arithmetic progressions 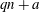 $qn + a$ . Rudin’s conjecture claims that
$qn + a$ . Rudin’s conjecture claims that 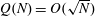 $Q(N)=O(\sqrt{N})$ , and in its stronger form that
$Q(N)=O(\sqrt{N})$ , and in its stronger form that 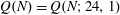 $Q(N)=Q(N;24,1)$ if
$Q(N)=Q(N;24,1)$ if 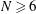 $N\ge 6$ . We prove the conjecture above for
$N\ge 6$ . We prove the conjecture above for 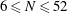 $6\le N\le 52$ . We even prove that the arithmetic progression
$6\le N\le 52$ . We even prove that the arithmetic progression 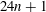 $24n+1$ is the only one, up to equivalence, that contains
$24n+1$ is the only one, up to equivalence, that contains 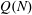 $Q(N)$ squares for the values of
$Q(N)$ squares for the values of 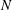 $N$ such that
$N$ such that 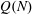 $Q(N)$ increases, for
$Q(N)$ increases, for 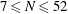 $7\le N\le 52$ (
$7\le N\le 52$ ( 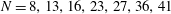 $N=8,13,16,23,27,36,41$ and
$N=8,13,16,23,27,36,41$ and 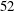 $52$ ).
$52$ ).
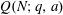
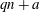
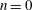
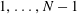
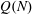
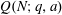
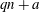
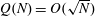
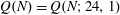
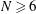
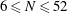
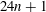
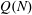
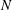
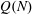
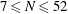
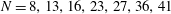
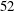
On the state complexity of semi-quantum finiteautomata⋆⋆⋆
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 17 April 2014, pp. 187-207
- Print publication:
- April 2014
-
- Article
- Export citation
Wieferich pairs and Barker sequences, II
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 24-32
-
- Article
-
- You have access
- Export citation
-
We show that if a Barker sequence of length
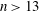 $n>13$ exists, then either n
$n>13$ exists, then either n  $=$ 3 979 201 339 721749 133 016 171 583 224 100, or
$=$ 3 979 201 339 721749 133 016 171 583 224 100, or 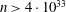 $n > 4\cdot 10^{33}$ . This improves the lower bound on the length of a long Barker sequence by a factor of nearly
$n > 4\cdot 10^{33}$ . This improves the lower bound on the length of a long Barker sequence by a factor of nearly 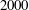 $2000$ . We also obtain eighteen additional integers
$2000$ . We also obtain eighteen additional integers 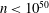 $n<10^{50}$ that cannot be ruled out as the length of a Barker sequence, and find more than 237 000 additional candidates
$n<10^{50}$ that cannot be ruled out as the length of a Barker sequence, and find more than 237 000 additional candidates 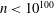 $n<10^{100}$ . These results are obtained by completing extensive searches for Wieferich prime pairs and using them, together with a number of arithmetic restrictions on
$n<10^{100}$ . These results are obtained by completing extensive searches for Wieferich prime pairs and using them, together with a number of arithmetic restrictions on  $n$ , to construct qualifying integers below a given bound. We also report on some updated computations regarding open cases of the circulant Hadamard matrix problem.
$n$ , to construct qualifying integers below a given bound. We also report on some updated computations regarding open cases of the circulant Hadamard matrix problem.
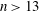

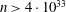
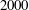
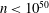
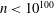

A scalable approach for ideation in biologically inspired design
-
- Article
-
- You have access
- HTML
- Export citation
Reuse of constraint knowledge bases and problem solvers explored in engineering design
-
- Article
-
- You have access
- HTML
- Export citation
A Generalized Model of PAC Learning and itsApplicability
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 09 April 2014, pp. 209-245
- Print publication:
- April 2014
-
- Article
- Export citation
