Refine search
Actions for selected content:
49494 results in Computer Science
Ramsey simplicity of random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 03 December 2024, pp. 298-320
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A graph
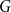 $G$ is
$G$ is 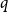 $q$-Ramsey for another graph
$q$-Ramsey for another graph 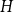 $H$ if in any
$H$ if in any 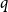 $q$-edge-colouring of
$q$-edge-colouring of 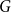 $G$ there is a monochromatic copy of
$G$ there is a monochromatic copy of 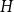 $H$, and the classic Ramsey problem asks for the minimum number of vertices in such a graph. This was broadened in the seminal work of Burr, Erdős, and Lovász to the investigation of other extremal parameters of Ramsey graphs, including the minimum degree.
$H$, and the classic Ramsey problem asks for the minimum number of vertices in such a graph. This was broadened in the seminal work of Burr, Erdős, and Lovász to the investigation of other extremal parameters of Ramsey graphs, including the minimum degree.It is not hard to see that if
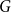 $G$ is minimally
$G$ is minimally 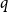 $q$-Ramsey for
$q$-Ramsey for 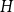 $H$ we must have
$H$ we must have 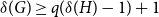 $\delta (G) \ge q(\delta (H) - 1) + 1$, and we say that a graph
$\delta (G) \ge q(\delta (H) - 1) + 1$, and we say that a graph  $H$ is
$H$ is  $q$-Ramsey simple if this bound can be attained. Grinshpun showed that this is typical of rather sparse graphs, proving that the random graph
$q$-Ramsey simple if this bound can be attained. Grinshpun showed that this is typical of rather sparse graphs, proving that the random graph 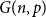 $G(n,p)$ is almost surely
$G(n,p)$ is almost surely 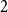 $2$-Ramsey simple when
$2$-Ramsey simple when 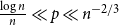 $\frac{\log n}{n} \ll p \ll n^{-2/3}$. In this paper, we explore this question further, asking for which pairs
$\frac{\log n}{n} \ll p \ll n^{-2/3}$. In this paper, we explore this question further, asking for which pairs 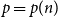 $p = p(n)$ and
$p = p(n)$ and 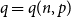 $q = q(n,p)$ we can expect
$q = q(n,p)$ we can expect 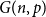 $G(n,p)$ to be
$G(n,p)$ to be 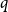 $q$-Ramsey simple.
$q$-Ramsey simple.We first extend Grinshpun’s result by showing that
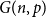 $G(n,p)$ is not just
$G(n,p)$ is not just 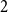 $2$-Ramsey simple, but is in fact
$2$-Ramsey simple, but is in fact 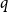 $q$-Ramsey simple for any
$q$-Ramsey simple for any 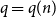 $q = q(n)$, provided
$q = q(n)$, provided 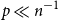 $p \ll n^{-1}$ or
$p \ll n^{-1}$ or 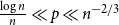 $\frac{\log n}{n} \ll p \ll n^{-2/3}$. Next, when
$\frac{\log n}{n} \ll p \ll n^{-2/3}$. Next, when 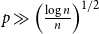 $p \gg \left ( \frac{\log n}{n} \right )^{1/2}$, we find that
$p \gg \left ( \frac{\log n}{n} \right )^{1/2}$, we find that 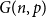 $G(n,p)$ is not
$G(n,p)$ is not 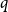 $q$-Ramsey simple for any
$q$-Ramsey simple for any 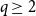 $q \ge 2$. Finally, we uncover some interesting behaviour for intermediate edge probabilities. When
$q \ge 2$. Finally, we uncover some interesting behaviour for intermediate edge probabilities. When 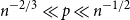 $n^{-2/3} \ll p \ll n^{-1/2}$, we find that there is some finite threshold
$n^{-2/3} \ll p \ll n^{-1/2}$, we find that there is some finite threshold 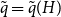 $\tilde{q} = \tilde{q}(H)$, depending on the structure of the instance
$\tilde{q} = \tilde{q}(H)$, depending on the structure of the instance 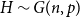 $H \sim G(n,p)$ of the random graph, such that
$H \sim G(n,p)$ of the random graph, such that 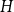 $H$ is
$H$ is 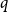 $q$-Ramsey simple if and only if
$q$-Ramsey simple if and only if 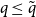 $q \le \tilde{q}$. Aside from a couple of logarithmic factors, this resolves the qualitative nature of the Ramsey simplicity of the random graph over the full spectrum of edge probabilities.
$q \le \tilde{q}$. Aside from a couple of logarithmic factors, this resolves the qualitative nature of the Ramsey simplicity of the random graph over the full spectrum of edge probabilities.
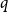
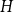
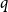
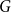
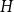
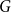
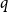
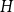
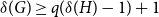
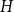
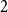
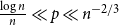
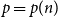
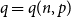
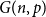
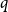
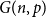
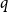
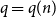
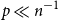
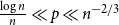
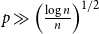
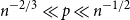
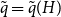
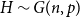
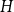
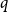
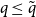
Measuring the effectiveness of programmed instructions (PI) to learn design thinking concepts for secondary school students
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 03 December 2024, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Signalling and rich trustworthiness in data-driven healthcare: an interdisciplinary approach
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e62
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Artificial intelligence at the bench: Legal and ethical challenges of informing—or misinforming—judicial decision-making through generative AI
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The ethics at the intersection of artificial intelligence and transhumanism: a personhood-based approach
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A scoping review on human-centered design approaches and considerations in the design of technologies for loneliness and social isolation in older adults
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessing design process knowledge in project-based learning: a comparative study in introductory engineering and junior manufacturing courses
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Artificial intelligence for collective intelligence: a national-scale research strategy
-
- Journal:
- The Knowledge Engineering Review / Volume 39 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Characteristics of effective design support: insights from evaluating additive manufacturing design artefacts
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A review of extensible continuum robots: mechanical structure, actuation methods, stiffness variability, and control methods
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Characterizing the use of contextual factors in engineering design: an exploration of global health designer practice
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
D-MEANDS-MD: an improved evolutionary algorithm with memory and diversity strategies applied to a discrete, dynamic, and many-objective optimization problem
-
- Journal:
- The Knowledge Engineering Review / Volume 39 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Human–machine collaboration for enhanced decision-making in governance
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 02 December 2024, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Other-than-Human Perspectives on Écosystème(s): Towards an ecosemiotic approach to sound and media art
-
- Journal:
- Organised Sound / Volume 29 / Issue 3 / December 2024
- Published online by Cambridge University Press:
- 20 December 2024, pp. 303-314
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Harold Clark, New Music in the Light of Nobleness: A Scandinavian Dream. An Expatriate’s View of Avant-Garde Norway, 1969–1979. Oslo: Norsk Musikforlag A/S, 2021. ISBN: 978-82-7093-734-9.
-
- Journal:
- Organised Sound / Volume 29 / Issue 3 / December 2024
- Published online by Cambridge University Press:
- 13 December 2024, pp. 352-353
- Print publication:
- December 2024
-
- Article
- Export citation
Improvising with Machines: A taxonomy of musical interactions
-
- Journal:
- Organised Sound / Volume 29 / Issue 3 / December 2024
- Published online by Cambridge University Press:
- 08 January 2025, pp. 340-351
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From Boethian Harmony to a Dry Riverbed: El sonido recobrado
-
- Journal:
- Organised Sound / Volume 29 / Issue 3 / December 2024
- Published online by Cambridge University Press:
- 16 December 2024, pp. 245-253
- Print publication:
- December 2024
-
- Article
- Export citation
Machine Listening as Sonification
-
- Journal:
- Organised Sound / Volume 29 / Issue 3 / December 2024
- Published online by Cambridge University Press:
- 19 December 2024, pp. 275-284
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Technology and Mathematics as Non-Human Forces: The agency of hyperbolic paraboloids, computer software and interface hardware in the making of a visitor-interactive audiovisual work
-
- Journal:
- Organised Sound / Volume 29 / Issue 3 / December 2024
- Published online by Cambridge University Press:
- 10 January 2025, pp. 327-339
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
